
Monthly Archives: April 2011
Coverstore Improvements
We have done some improvements to coverstore, the Open Library book covers service, recently.
Now it is possible to access book covers by all the available identifiers. For example:
pystatsd & 5,000 Lists!
We’re working hard to improve Open Library’s general stability and performance, after a few harrowing weeks moving our hardware infrastructure around. We’re beginning to measure more stuff across the site, from general activity levels (about 40,000 catalog edits every month!) to quite specific actions (like, seeing that every second, 1-3 people open up our BookReader).
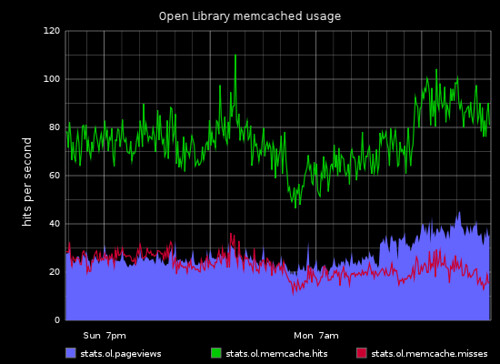
We’ve begun using a super awesome, real-time stats processing package called pystatsd, a Python implementation of Etsy’s statsd server. My favourite bit is a program that sits on top of that called graphite which takes all the stats we collect with pystatsd and renders them as graphs in a browser. Suddenly, we can see the system in a new and useful way.
We’re also looking hard at improving our memcached configuration, recently introducing another 4 memcached machines into our pool. Now that we can measure memcached hits and misses using pystatsd and graphite, we’ll be able to tell when our caching stuff is actually improving. Yay!
Another tweak you might find interesting… it used to be that lists would only show up on the main Lists page if they contained at least 3 seeds. The other day, Raj and I upped that to at least 5 seeds, and that immediately produced a selection of arguably more interesting lists, most of which settle around a subject area. Here’s a small selection:
- Victorian Illustrations by Old Book Illustrations
- Computer Technology by James Buckingham
- French psychology, 1880-1930 by John Carson
- The Best Books for Writers by Mary Gannon
- Bees by Iona Stewart
- And, not to blow my own horn too loud, but, I stumbled across what looks like a pretty good list on The (UK) Independent site, so I “transcribed” that into Open Library: The 50 Books Every Child Should Read
Have you made a great list, or found someone else’s? Let us know in the comments!
Alice: The On-Line Catalog

So awesome. That’s 1983 in Ohio, folks.
New Titles in Lending Library!
Our little lending library is continuing to grow, this time with 90 new titles purchased directly from two fabulous eBook publishers: A Book Apart & Smashwords.
3 titles from A Book Apart are all must-reads for any discerning web professional…