
For our first big release of 2011, we’d like to introduce you to a couple of new bits and pieces on Open Library:
- A new home page design
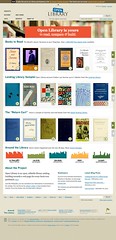 When we launched the site redesign almost a year ago, the home page was trying to make it clear that it was possible to edit the Open Library site, and that we welcome your contributions. You might remember the cheeky “Ever wanted to play librarian?” phrase. Now that the new design has settled somewhat, and we have a great level of activity across the site, we wanted to shift the focus again, to make it clearer that you can actually get to books as well. Not only over 1 million free eBooks, but also our small, but growing Lending Library.
When we launched the site redesign almost a year ago, the home page was trying to make it clear that it was possible to edit the Open Library site, and that we welcome your contributions. You might remember the cheeky “Ever wanted to play librarian?” phrase. Now that the new design has settled somewhat, and we have a great level of activity across the site, we wanted to shift the focus again, to make it clearer that you can actually get to books as well. Not only over 1 million free eBooks, but also our small, but growing Lending Library.
So, the new home page displays 3 new “carousels” that display an assortment of free eBooks to read, a small curated selection of titles from the Lending Library, and Version 1 of a new “Return Cart” feature, that shows you eBooks that have, well, been recently returned.

We’ve also added some activity graphs at the bottom of the page, which tell you that in the last 28 days (at time of writing), we’ve had:
- 5,794,587 unique visitors,
- 14,219 new members sign up,
- 39,939 edits to the catalog,
- 990 new lists created, and
- 3,340 eBooks borrowed.
Wow!
- The “In Library” lending program
In one small step for library kind and readers around the world, today we’re announcing a new collection of “In Library” eBooks available for loan. Here’s the idea: there’s a group of libraries participating in the pilot program, each of which has added eBooks to the new pool.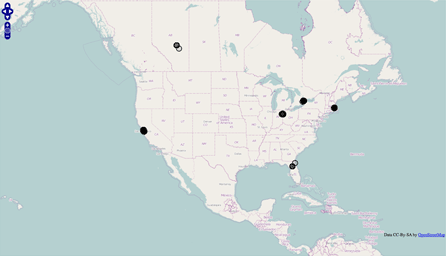
See a map displaying the participating libraries – Yay OpenStreetMap!The interesting part is that you, dear patron, need to get your bones into the actual libraries themselves to borrow any of the titles from any of the libraries in the pool. Once you’ve done that, the loan acts just like the “normal” Lending Library loans that are available to any Open Library account holder around the world, 5 books at a time, for up to 2 weeks. Cool, huh?