



Public Library: An American Commons is a photography exhibition on at the San Francisco Public Library’s Jewett Gallery, running from April 9 to June 12. The photographer, Robert Dawson, has captured the American relationship with public libraries across the country in a series of intimate portraits. From the Design Observer review:
Tag Archives: Library
Minimum Viable Record?
Having worked more closely with bibliographic data than I had ever expected to over the last couple of years, I still can’t quite believe how complicated it can be. I keep holding tight something Karen Coyle told me when I first started at Open Library, that “library metadata is diabolically rational.” Now that I’ve witnessed the cataloging from lots of different sources and am more familiar with the level of detail that’s possible in a library catalog, I have a new fondness for these intensely variegated information systems; at times devilishly detailed, at others wildly incomplete or arcanely abbreviated. Everyone likes to arrange things and classify them into groups. It’s when you try to get people to put things into groups that someone else has come up with that it starts getting messy.
Get Thee to a Library!
For our first big release of 2011, we’d like to introduce you to a couple of new bits and pieces on Open Library:
- A new home page design
 When we launched the site redesign almost a year ago, the home page was trying to make it clear that it was possible to edit the Open Library site, and that we welcome your contributions. You might remember the cheeky “Ever wanted to play librarian?” phrase. Now that the new design has settled somewhat, and we have a great level of activity across the site, we wanted to shift the focus again, to make it clearer that you can actually get to books as well. Not only over 1 million free eBooks, but also our small, but growing Lending Library.
When we launched the site redesign almost a year ago, the home page was trying to make it clear that it was possible to edit the Open Library site, and that we welcome your contributions. You might remember the cheeky “Ever wanted to play librarian?” phrase. Now that the new design has settled somewhat, and we have a great level of activity across the site, we wanted to shift the focus again, to make it clearer that you can actually get to books as well. Not only over 1 million free eBooks, but also our small, but growing Lending Library.
So, the new home page displays 3 new “carousels” that display an assortment of free eBooks to read, a small curated selection of titles from the Lending Library, and Version 1 of a new “Return Cart” feature, that shows you eBooks that have, well, been recently returned.

We’ve also added some activity graphs at the bottom of the page, which tell you that in the last 28 days (at time of writing), we’ve had:
- 5,794,587 unique visitors,
- 14,219 new members sign up,
- 39,939 edits to the catalog,
- 990 new lists created, and
- 3,340 eBooks borrowed.
Wow!
- The “In Library” lending program
In one small step for library kind and readers around the world, today we’re announcing a new collection of “In Library” eBooks available for loan. Here’s the idea: there’s a group of libraries participating in the pilot program, each of which has added eBooks to the new pool.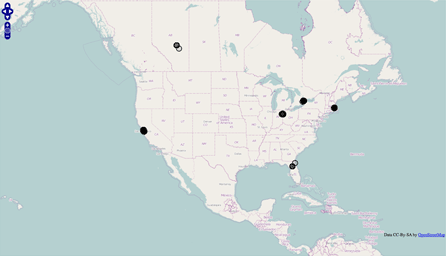
See a map displaying the participating libraries – Yay OpenStreetMap!The interesting part is that you, dear patron, need to get your bones into the actual libraries themselves to borrow any of the titles from any of the libraries in the pool. Once you’ve done that, the loan acts just like the “normal” Lending Library loans that are available to any Open Library account holder around the world, 5 books at a time, for up to 2 weeks. Cool, huh?
Loading the text of 2 million books into solr
Here at the Internet Archive we’ve scanned millions of books. One of our challenges is helping people find books they want to read. The bibliographic records can be searched in Open Library. If somebody knows the title they can find the book. It would be useful if all the text inside the book was also searchable. This is a problem I’ve been working on.
I started by taking the output in XML from our OCR and tidying up the results. The OCR program only considers individual pages, so paragraphs that span a page were split up. A phrase search that crosses the page boundary wouldn’t match. My code detects paragraphs broken across pages or columns and recombines them. It also deals intelligently with hyphenated words by joining them back together.
The process of fixing up the OCR involves parsing XML, it is slower than just reading a text file. Fortunately the books are stored on a few hundred computers in our petabox storage cluster. I’m able to run the XML parsing and OCR tidy stage on the computers in the cluster in parallel.
Next I take this data and feed it into solr. My solr schema is pretty simple. The fields are just the Internet Archive identifier and the text of book in a field called body. When we show a search inside results page we can pull the book title from the Open Library database. It might be quicker to generate result pages if all the data need to display them were in the search index, but that would mean updating the index whenever one of these piece of information changes. It is much simpler to only update the search index if the output from OCR changes.
Armistice Day

From The Western Front, published in 1917. A series of sketches, drawings and paintings from the ‘Ruined Tower of Becordel-Becourt’ to the ‘The Giant Slotters,’ Mr. Muirhead Bone’s sketches give us a unique eyewitness account of life on the Western Front.
There are over 2,800 books you can read online about World War, 1914-1918.