We’re very excited about a little integration that the smartypants team over at Flickr have done with Open Library. If you happen to use Flickr and just happen to photograph the covers or insides of books you read, there’s an easy way to connect them to the catalog records we have on Open Library. You just have to add a thingy called a “machine tag,” the same way you would add any other tag, making use of a special format for the tag.
For example, here is a photo of a book that Heather read, posted on Flickr:

This book also has a record on Open Library, at this URL:
http://openlibrary.org/b/OL23086206M/Tethered
Now, to link them together, all we need to do is add a specific machine tag to the Flickr photo that references the Open Library ID, like this:
openlibrary:id=OL23086206M
And hey presto, now you see a link to Open Library under Additional Information on Heather’s photo page:
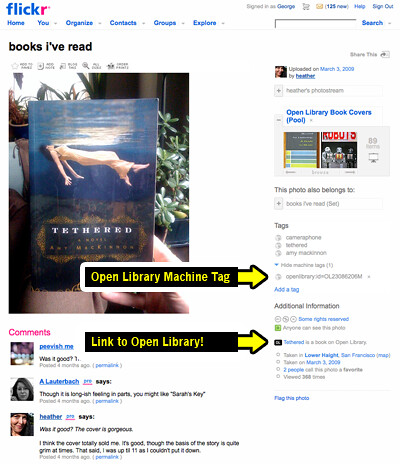
You might find yourself asking, why is this good? Well, it’s good because it creates another channel for content to come into Open Library. We’ve been thinking about how much the rest of the web knows about all the books in our catalog, and we’ve begun the process of actively seeking out this content, and piling it onto our catalog records. So, each photograph or cover that we now have access to via Flickr is like another node in the network that surrounds our book records. Rather than treat these records as isolated, we want to connect them to as many things as we can find, which in turn, will begin to make Open Library richer with more points of entry than a search on Open Library itself.
There’s a curious example of this already, from STML on Flickr. He added the same machine tag to several photographs he’d taken of his copy of the “Progressive Atlas” book:

Nice to be able to see inside the book too!
We were also thrilled to discover this morning that one of the largest independent publishers in the USA, W.W. Norton, has added these Open Library machine tags to some 100 or so of their beautiful covers, archived on Flickr! Awesome!



There are a few fiddly bits emerging as people try this out. Like, when you do a search for a book, Open Library displays all the editions it knows about in the search results, and you might even see two records that have the same publisher name and publish date… That sometimes makes it a bit tricky to work out which particular Open Library record to link to, but our advice at this stage is just to pick one and run with it. (Later, we’d like to provide the option to merge two records into one, but we’re not there yet.)
Another interesting question being asked internally here, and also on our Flickr group is “what conventions should we be using for machine tags?” Our attitude here is that this integration is only very new, so it’s not the time to be impressing standards or conventions. We’d much rather just step back and see what people come up with on their own. There was a funny example yesterday, where dumbledad asked whether it was OK to tag this “action shot” of himself reading a book sitting outside with the openlibrary:id= machine tag. The response is, yes! Go for it! Or, create your own machine tag that seems to work for you, perhaps openlibrary:actionshot= or openlibrary:inside=, and we’ll just see what happens.
The next step, of course, is to have all these lovely bits and pieces show up on Open Library itself. Stay tuned!
(Disclaimer – I thought it might be important to say that I used to work at Flickr, but I had absolutely no say in the development of this new feature. There are also several other services that are “connectible” using this method. You might like to read the Flickr Code blog for more details on that.)



