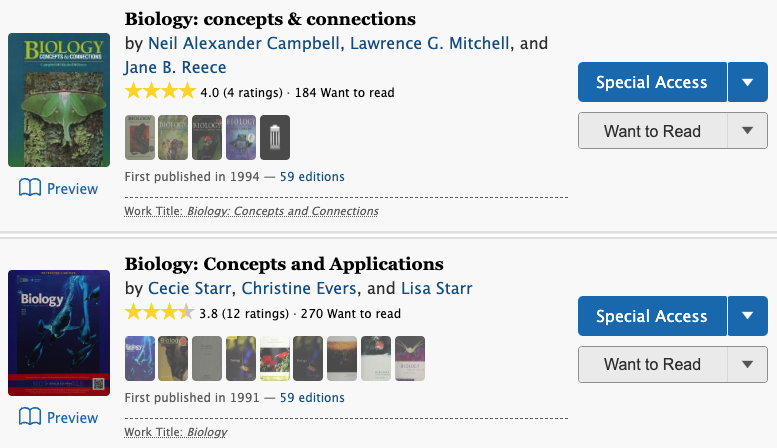
Today’s challenge is to find “The Secret of Secrets“, by Dan Brown using Open Library search. It’s not impossible, but it is not easy… And it’s not just because the Я is backwards on the cover.

If you search for “the secret of secrets“, you won’t find the right match on the first two pages of results.
If you search for “the secret of secrets dan brown“, the result is still 7th in the list.
In this example, our current search algorithm is biasing too heavily on returning book results that have lots of editions to vouch for them, as well as other boosting factors (like star ratings) that don’t always produce desired result.
What search algorithm would perform better? And how do know whether one approach is better than the other?
These are key questions Drini Cami — core maintainer of Open Library search — has been investigating this month.
Is Search Improving?
In order to know whether we’re making changes that improve the quality of our search results, we can’t just change the algorithm, type in a search, and see if the result is better in that one case. We need to apply some consistent framework across a collection of challenging queries and measure how the system — on a whole — performed before versus after.
In Open Library’s case, Drini maintains a Search Evaluation Spreadsheet that measures 100 common searches—everything from “Harry Potter” and “Little Prince” to “The Secret Garden” and “Narnia”. These searches come from our server logs (i.e. popular searches from patrons). It also contains challenging cases that we’ve seen underperform in the past.
For each search query we’ve collected, we define what we expect the “correct” search result to be and then check how often the correct result appears in the top 3 search results (across the search algorithms we’re considering).

Multiplicative Instead of Additive
For the technical crowd, this change (PR #12357) adjusts Work Search’s Solr eDisMax tuning to use multiplicative boosting (via boost) instead of additive boosting (via bf) to reduce over-weighting of popularity signals relative to textual relevance:
- Replaces
bf-based additive boosts with an eDismaxboostfunction expression. - Expands/adjusts
qfand phrase-boost parameters (pf,pf2) to change match weighting and proximity scoring.
Overall, the change has improved the relevance of our test results by roughly 10%:

Early Anecdotes:
In our testing playground…

- “The secret of secrets” now appears as the 3rd result.
- “My Life”, by Bill Clinton went from 101th to 19th
- “laws field guide” went from 14th to 1st
Expect these improvements to be live on the main site early next week. Happy reading!
Future Opportunities: Exact Match versus Browser
Since releasing this blog post, we received a great question internally by Sawood Alam, from the Wayback Machine team who asks:
Have you measured how would this change affects the discovery use-case where a patron is not after one specific document in mind, but wants to find out what options are out there (as opposed to the lookup use-case where they already know what they are looking for)?
And this is indeed something the Open Library team has been considering. Sawood is pointing out that there are [at least] two modes of searching:
- by Exact match
- Browsing
One may browse in a variety of different ways, but for simplicity I’d like to refer to this as “searching by proxy”. That is to say, instead of searching for an exact book by title, a patron may endeavor to discover a suitable book by any number or combination of proximal qualities like author, topic, format, genre. An example is a search for nonfiction books about UFOs that are advertised as textbooks and published before 1950.
For browsing queries of this flavor, it’s difficult to know (in advance) what book(s) should appear in the top-three position in search results as the answer will often be subjective to the searcher.
As a result, an additional approach will need to be instrumented and added to our existing process that (a) accurately identifies when a search term is for a proximal quality rather than an exact (e.g. title) match and, (b) introduces secondary evaluation metric, such as:
- Success Rate: How often any result is clicked — perhaps called Query Success Rate (QSR)
- Relevance: When a result is clicked… how often is this click for a record in a top 3 position — something like Mean Reciprocal Rank (MRR)
Further research is required to understand how these metrics may be combined in a recipe that results in the best experience for patrons. For instance, [when] is it more important to improve relevance versus the general distribution of clicks? Maybe “better” means increasing the ratio of searches-to-clicks by 20% rather than increasing the number of clicks in the top-3 position by 25% (if search-to-clicks were to drop by 5%).
Suffice to say, as policy changes make it more challenging for some readers to find the exact book(s) they are looking for, it becomes increasingly meaningful to be able to suggest suitable alternatives — and be able to measure how effective we are at making relevant recommendations. Measuring browse cases is something we expect to work towards in the coming months.