Mek here, program lead for OpenLibrary.org at the Internet Archive with important updates and a way for library lovers to help protect an Internet that champions library values.
Consider signing this open letter to urge publishers to restore access to the 500,000 books they’ve caused to be removed from the Internet Archive’s lending library and let readers read.
Over the course of 2023, the Open Library team conducted design research and video-interviewed nine volunteers to determine how learners and educators make use of the OpenLibrary.org platform, what challenges get in their way, and how we can help them succeed. Participants of the study included a mix of students, teachers, and researchers from around the globe, spanning a variety of disciplines.
About the Participants
At the earliest stages of this research, a screener survey involving 466 participants helped us understand the wide range of patrons who use the Open Library. Excluding 141 responses that didn’t match the criteria of this research, the remaining 325 respondents identified as:
126 high school, university, or graduate students
64 self learners
44 researchers
41 K-12 teachers
29 professors
12 parents of K-12 students
9 librarians
Participants reported affiliations with institutions spanning a diverse variety of geographies, including: Colombia, Romania, France, Uganda, Indonesia, China, India, Botswana, Nigeria, and Ireland.
Findings
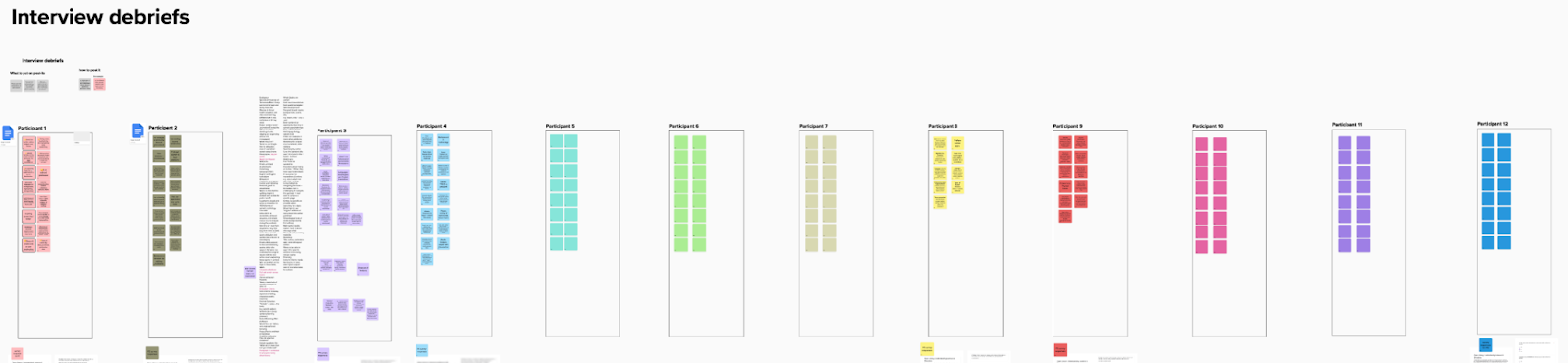
A screenshot of the Findings section of the collaborative Mural canvas, filled with digital sticky notes
Here are the top 7 learnings we discovered from this research:
The fact that the Open Library is free and accessible online is paramount to patrons’ success. During interviews, several participants told us that the Open Library helps them locate hard to find books they have difficulty finding elsewhere. At least two participants didn’t have access to a nearby library or a book vendor that could provide the book they needed. In a recent Internet Archive blog post, several patrons corroborated these challenges. In addition to finding materials, one or more of our participants are affected by disabilities or have worked with such persons who have limited mobility, difficulty commuting, and benefit from online access. Research use cases also drove the necessity for online access: At least two interviewed participants used texts primarily as references to cite or verify certain passages. The ability to quickly search for and access specific, relevant passages online was essential to helping them to succeed at their research objective, which may have otherwise been prohibitively expensive or technologically intractable.
Participants voiced the importance of internationalization and having books in multiple languages. Nearly every participant we interviewed advocated for the website and books to be made available in more languages. One participant had to manually translate sections of English books into Arabic for their students. Another participant who studied classic literature manually translated editions so they could be compared. A teach who we interviewed relayed to us that it was common for their ESL (English as a Second Language) students to ask for help translating books from English into their primary language.
The interests of learners and educators who use the Open Library vary greatly. We expected to find themes in the types of books learners and educators are searching for. However, the foci of participants we interviewed spanned a variety of topics, from Buddhism, to roller coaster history, therapy, technical books, language learning materials, and classic literature. Nearly none of our candidates were looking for the same thing and most had different goals and learning objectives. One need they all have in common is searching for books.
The Open Library has many educational applications we hadn’t intended. One or more participant reported they had used the read aloud feature in their classroom to help students with phonics and language learning. While useful, participants also suggested the feature sometimes glitches and robotic sounding voices are a turnoff. We also learned several educators and researchers link to Open Library when creating course syllabi for their students.
Many of Open Library subject and collection pages weren’t sufficient for one or more of our learners and educators use cases. At least two interviewees ended up compiling their own collections using their own personal web pages and linking back to the Open Library. One participant tried to use Open Library to search for K-12, age-appropriate books pertaining to the “US Constitution Day” and was grateful for but underwhelmed by the results.
The Open Library service & its features are difficult to discover.
Several interviewees were unaware of Open Library’s full-text search, read aloud, or note-taking capabilities, yet expressed interest in these features.
Many respondents of the screener survey believed their affiliated institutions were unaware of the Open Library platform.
Open Library’s community is generous, active, and eager to participate in research to help us improve. Overall, 450+ individuals from 100+ institutions participated in this process. Previously, more than 2k individuals helped us learn how our patrons prefer to read and more than 750 participants helped us redesign our book pages.
Some of our learnings we had already predicted and seeing these predictions confirmed by data has also given us conviction in pursuing next steps. Some learnings were genuinely surprising to us, such as many teachers preferring the online web-based book reader because it doesn’t require them to install any extra software on school computers.
Proposals
After reviewing this list of findings and challenges, we’ve identified 10 areas where the Open Library may be improved for learners and educators around the globe:
Continuing to make more books available online by expanding our Trusted Book Providers program and adding Web Books to the catalog.
Participating in outreach to promote platform discovery & adoption. Connect with institutions and educators to surface opportunities for partnership, integration, and to establish clear patterns for using Open Library within learning environments.
Adding onboarding flow after registration to promote feature discovery. Conduct followup surveys to learn more about patrons, their challenges, and their needs. Add an onboarding experience which helps newly registered patrons become familiar with new services.
Making books available in more languages by prototyping the capability to translate currently open pages within bookreader to any language, on-the-fly.
Creating better subject and collection page experiences bygiving librarians tools to create custom collection pages and tag and organize books in bulk.
Improving Read Aloud by using AI to generate more natural/human voices, make the feature more discoverable in the bookreader interface, and fix read aloud navigation so it works more predictably.
Allowing educators to easily convert their syllabi to lists on Open Library using a Bulk Search & List creator feature.
Moving to a smarter, simpler omni-search experience that doesn’t require patrons to switch modes in order to get the search results they want.
Importing missing metadata and improving incomplete records by giving more librarians better tools for adding importers and identifying records with missing fields.
Improving the performance and speed of the service so it works better for more patrons in more areas.
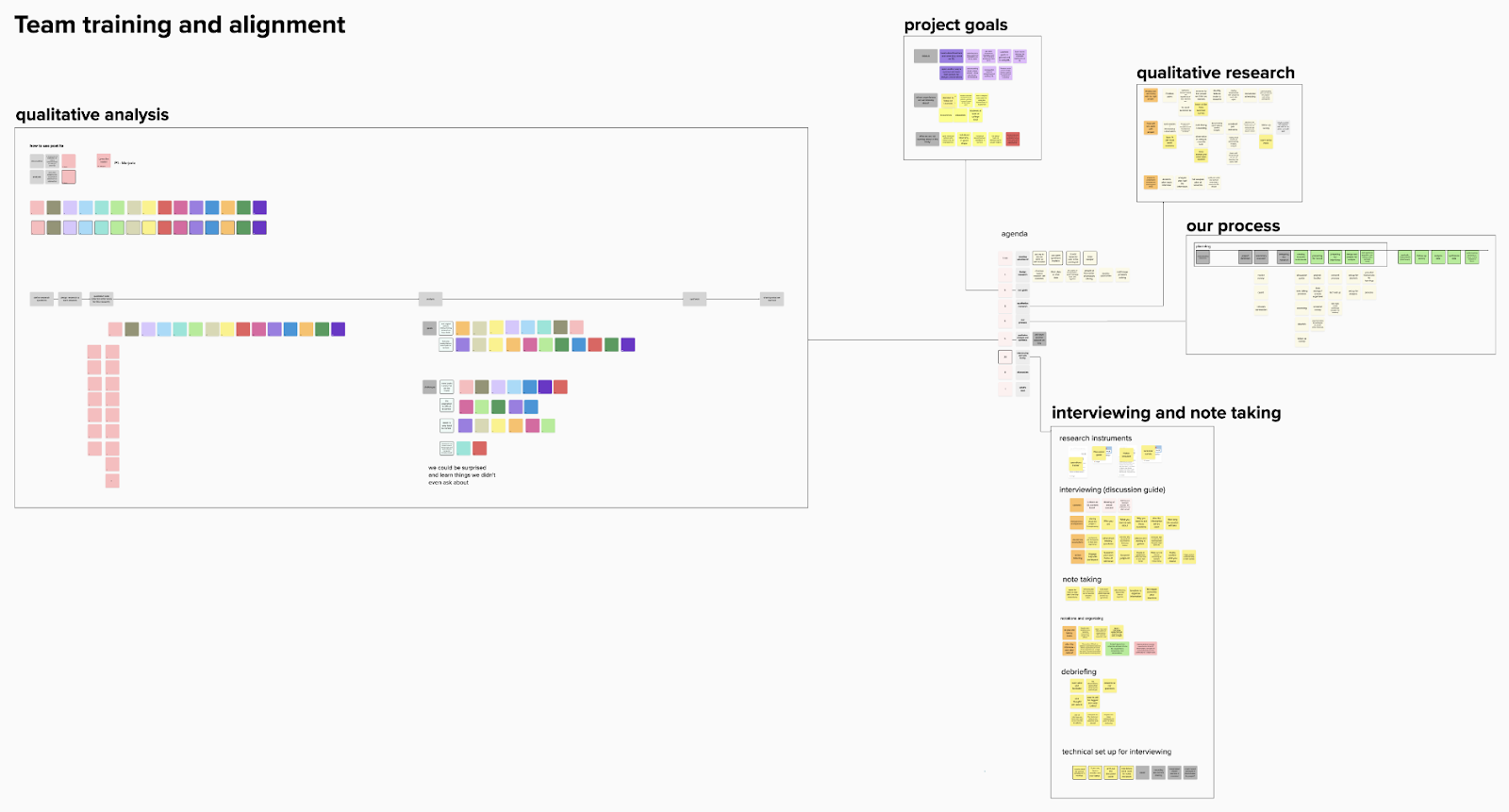
About the Process
The Open Library team was fortunate to benefit from the guidance and leadership of Abbey Ripstra, a Human-Centered Design Researcher who formerly led Design Research efforts at the Wikimedia organization. This research effort wouldn’t have been achievable without her help and we’re grateful.
In preparation for our research, Abbey helped us outline a design process using an online collaboration and presentation tool called Mural.
During the planning process, we clarified five questions:
What are the objectives of our research?
How will we reach and identify the right people to speak with?
What questions will we ask interview participants?
How will we collate results across participants and synthesize useful output?
How can we make participants feel comfortable and appreciated?
To answer these questions, we:
Developed a Screener Survey survey which we rendered to patrons who were logged in to OpenLibrary.org. In total, 466 patrons from all over the world completed the survey, from which we identified 9 promising candidates to interview. Candidates were selected in such a way as to maximize the diversity of academic topics, coverage of geographies, and roles within academia.
We followed up with each candidate over email to confirm their interest in participating, suggesting meeting times, and then sent amenable participants our Welcome Letter and details of our Consent Process.
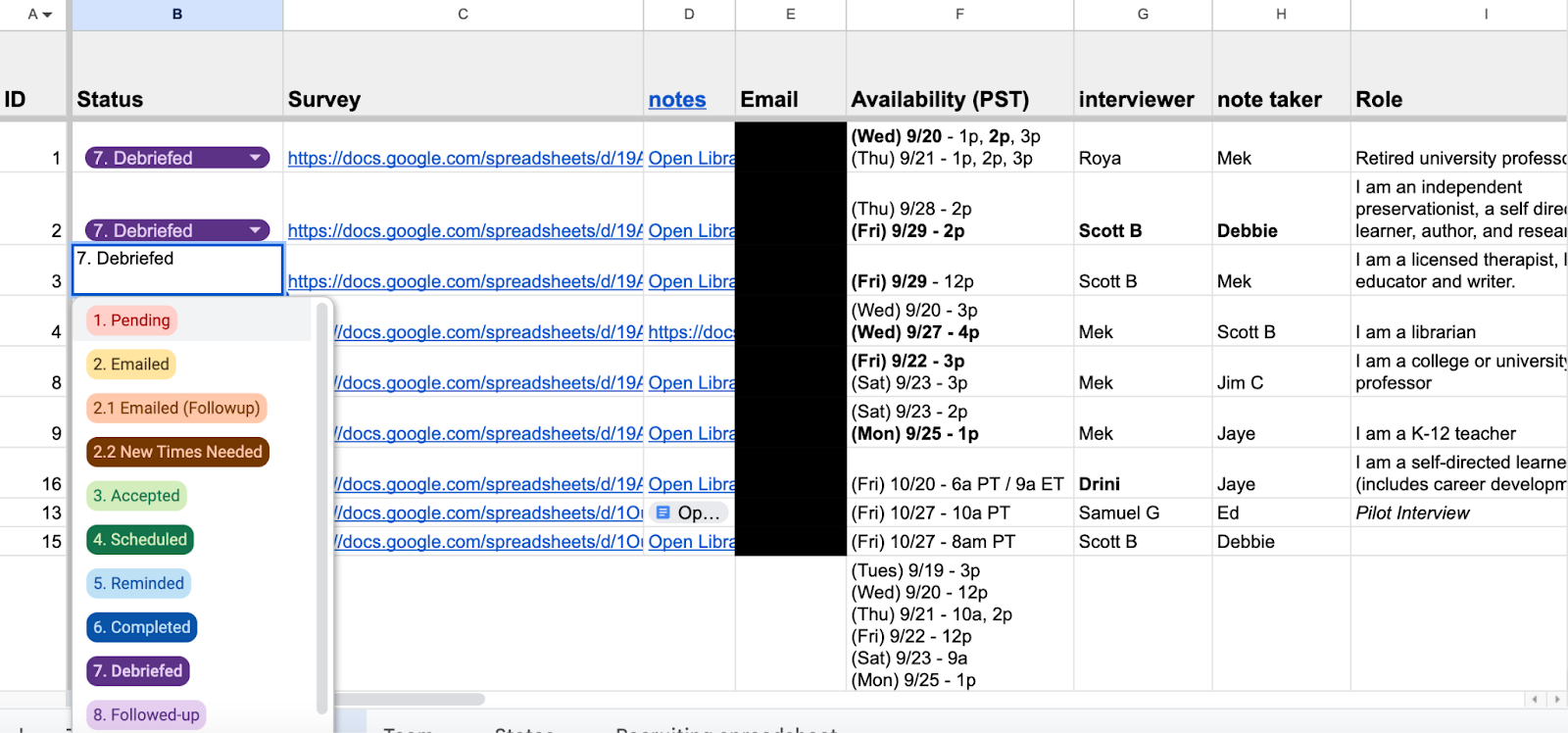
We coordinated interview times, delegated interview and note taking responsibilities, and kept track of the state of each candidate in the process using an Operations Tracker we built using Google Sheets:
During each interview, the elected interviewer followed our Interviewer’s Guide while the note taker took notes. At the end of each interview, we tidied up our notes and debriefed by adding the most salient notes to a shared mural board.
When the interviewing stage had concluded, we sent thank you notes and small thank you gifts to participants. Our design team then convened to cluster insights across interviews and surface noteworthy learnings.
More than just a ‘thank you’, Open Library’s new Team Page shines a spotlight, beyond staff, at the invaluable efforts of leads, fellows, and contributors – spanning engineering, design, librarianship, and communications – who make openlibrary.org possible.
The Open Library website is an open source effort, powered by an extensive network of volunteer contributors from across the globe. Some contributors swim by to nibble on a specific issue or check out our weekly community calls. Other contributors plant roots and collaborate with staff, as appointed Fellows, to make progress on involved projects that may entail weeks or months of thoughtful preparation. A select few contributors become intimately familiar with our systems, choose to mentor others in the community, and volunteer to manage and lead specific, discrete parts of the project, like our design system, our javascript practices, or internationalization.
In the past, the website had a stale list of contributors and we didn’t have an established framework for spotlighting the generous humans behind Open Library and keeping this list up to date. With the skillful touch of fellows from our design team—Debbie San, Jaye Lasseigne—and mentorship from Scott Barnes on staff, we now have a beautiful, filterable, and maintainable way of showcasing the achievements of Open Library’s diverse community of contributors: https://openlibrary.org/about/team
We had an opportunity to interview Debbie San, who is responsible for the new Team Page design, to learn more about the design process for this project, and Jaye Lasseigne, who led the new page’s implementation.
An Interview with the Designer & Developer
Speaking with Debbie about the Team Page’s Design Process:
Q.) What led to the decision to create a new team page?
A.) Debbie’s Insight: I have always believed that it is crucial to recognize individuals for their work. Open Library has many unique and talented individuals, volunteers and staff alike. Our team page is an opportunity to recognize them.
Q.) What was the inspiration behind the team page design?
A.) Debbie’s Response: There were many different websites used as inspirations. We looked at team pages from universities, smaller and bigger projects, and anything else that could help the vision of redesigning our team page.
Q.) How do you incorporate collective input and diverse perspectives into the design process?
A.) Debbie’s Advice: Design is a creative process, but it doesn’t mean it’s a solo process. I believe in the power of collective input and collaboration. Even when I wasn’t 100% sold on the feedback, I valued the diverse perspectives that shaped our collective vision. In the realm of design, embracing a variety of viewpoints is important when it comes to refining and enhancing the end result.
Q.) How do you approach the iterative process in design, particularly when creating different mock-ups?
A.) Debbie’s Thoughts: Even though the implementation may seem simple, challenges may appear, and it is up to everyone, designers and developers alike, to dialogue, to grow together and to find the best solutions.
I am super thankful to have worked with Jaye and Scott here and how hard they worked to bring this design to life. Now we have a team page that celebrates all staff and contributors who empower Open Library.
Speaking with Jaye about the Team Page’s Technical Implementation:
Q.) Can you share some insights into how your team worked together to bring this page to life?
A.) Jaye’s Thoughts: Debbie and I worked really well together! I got Debbie’s Figma designs and immediately started working to put it in code. I also received help from Scott Barnes and Mek (Program Lead) to hook up my CSS file, and Jim Champ showed me how to hook up a Javascript file. I remember checking in with Debbie a few times to get feedback on how the design looked on the browser.
Q.) Can you elaborate on challenges you encountered and how you overcame them during the coding process?
A.) Jaye’s Response: Most of my personal challenges came from my limited knowledge of the codebase and where files were located. To help me understand the codebase, I watched some of the videos in the ‘Getting Started’ guide on the Open Library GitHub.
After that, I found I still had questions so I reached out to Mek for help on the CSS. He was able to show me where the CSS files are located, and from there, I was able to figure out how to hook my CSS up to my HTML page. When I got to the Javascript portion, I reached out to Jim Champ who explained the flow of the Javascript files and where everything needed to go for it to work.
Q.) What advice would you give to other organizations who are looking to create a team page?
A.) Jaye’s Advice: “Do lots of research on other team pages you may find online. Find examples you like – you don’t need to reinvent the wheel.”
Just in Time for Growth
Debbie and Jaye’s hard work comes at an important time, given the recent growth of Open Library’s community of contributors.
In 2023, the Open Library project registered interest from 443 volunteer applicants, while cultivating a community of over 1,000 members on Slack. The project also benefited from 2,500 survey respondents, 20+ active developers, and 5 fellows across our 4 programs: Design, Communications, Engineering, and Librarianship. We celebrated the achievements of our community members during our 2023 Open Library Community Celebration.
Join In or Follow Along
Whether you’re a patron, a community contributor, or someone discovering Open Library for the first time, we invite you to explore our new Team Page to meet some of the people who power Open Library. Or, you can follow us on Twitter for our latest updates. If you’re inspired by our mission and want to contribute, let us know at openlibrary.org/volunteer.
Back in 2020, we started the tradition of hosting an annual Community Celebration to honor the efforts of volunteers across the globe who help make the Open Library project possible.
Tomorrow, Tuesday, October 31st at 9am Pacific, we warmly invite the public to join us in a small gathering to celebrate the hardworking humans who keep the website going, see demonstrations of their accomplishments, and get a glimpse into our direction for 2024 — Halloween Edition!
During this online celebration, you may look forward to:
Announcements of Our Latest Developments: Discover the impact of our recent initiatives and how they’re making a difference.
Opportunities to Participate: Learn how you can get involved and become an active member of our volunteer community.
A Sneak Peek Into Our Future: Get an exclusive glimpse of what lies ahead in 2024 and how we’re shaping the future together.
For all the latest updates leading up to the event, be sure to follow us on Twitter by visiting https://twitter.com/openlibrary. Looking for ways to get involved?
Mark your calendars, spread the word, and get ready for an event that’s all about our incredible community. We can’t wait to see you there!
Earlier this year, the Internet Archive’s Open Library conducted a brief survey to learn more about patrons’ experiences and preferences when borrowing and reading books. As promised, we’ve anonymized the results and are sharing them with you!
The purpose of this survey was to better understand:
If, how, & why Open Library patrons download books
How patron reading preferences align with our offerings
Survey Setup
For one week, starting on Tuesday 2022-02-07, OpenLibrary.org patrons were invited to participate in a brief survey including 7 questions — one of which was a screener to ensure we only included the responses of patrons who have prior experience using the Open Library.
In total, 2,121 patrons participated in the survey and, after screening, 1,118 were included in the results.
Errata: In the original survey, the question asking patrons “When you DON’T DOWNLOAD the books you’ve borrowed from Open Library, what is your primary reason?”, we mistakingly omitted a “N/A – I Don’t typically download” option and we corrected this on day 1 of the survey.
6 Key Learnings
Around half of participants have used adobe content server with DRM to securely download their loaned books
Of participants who download their loans, the top reason (54%) is for offline access
Of participants who download their loans, a quarter do so because they prefer the EPUB text format to the image-based experience of the online bookreader.
Around 42% ofparticipants report difficulty downloading their loans. Of these participants…
69% were unable to locate a download option (or a download option didn’t exist for that book)
31% experienced found a download option but couldn’t get it to work
Around half of participants intentionally opt for BookReader for a variety of reasons:
Its simplicity & convenience; no app installation required
Many teachers can’t download on school computers
Many patrons don’t trust downloads, dislike DRM, or want their reader privacy protected
Some patrons have limited storage space
Around half of participants read for pleasure, the other half for some form of self-learning or research.
What participants said
~150 participants shared their praise, thanks, and personal inspirational stories
~75 participants offered productive critiques for how we could improve our book finding and book reading experiences
Fixing OCR, hiding menu bars while reading, zooming & scrolling, etc
~55 participants expressed concerns about “1 hour” lending duration
Some participants did not like the intrusive, non-dismissable Open Library banner
We heard feedback from the community loud and clear that the implementation of 1-hour loans may not always be ideal for all patrons. The Internet Archive has been exploring and prototyping various tweaks to lending, such as an auto-renewal mechanism, that could extend a loan automatically for a patron if, at the end of the loan period, the book is still actively being read.