

Exploring how Open Library uses author data to help readers move from imagination to impact
By Nick Norman, Edited by Mek & Drini

According to René Descartes, a creative mathematician, “The reading of all good books is like a conversation with the finest [people] of past centuries.” If that’s true, then who are some of the people you’re talking to?
If you’re not sure how to answer that question, you’ll definitely appreciate the ‘Author Stats’ feature developed by Open Library.
A deep dive into author stats
Author stats give readers clear insights about their favorite authors that go much deeper than the front cover: such as birthplace, gender, works by time, ethnicity, and country of citizenship. These bits and pieces of knowledge about authors can empower readers in some dynamic ways. But how exactly?
To answer that question, consider a reader who’s passionate about the topic of cultural diversity. However, after the reader examines their personalized author stats, they realize that their reading history lacks diversity. This doesn’t mean the reader isn’t passionate about cultural diversity; rather, author stats empowers the reader to pinpoint specific stats that can be diversified.
Take a moment … or a day, and think about all the books you’ve read — just in the last year or as far back as you can. What if you could align the pages of each of those books with something meaningful … something that matters? What if each time you cracked open a book, the voices inside could point you to places filled with hope and opportunity?
According to Drini Cami — Open Library’s lead developer behind Author Stats , “These stats let readers determine where the voices they read are coming from.” Drini continues saying, “A book can be both like a conversation as well as a journey.” He also says, “Statistics related to the authors might help provide readers with feedback as to where the voices they are listening to are coming from, and hopefully encourage the reading of books from a wider variety of perspectives.” Take a moment to let that sink in.
Data with the power to change
While Open Library’s author stats can show author-related demographics, those same stats can do a lot more than that. Drini Cami went on to say that, “Author stats can help readers intelligently alter their behavior (if they wish to).” A profound statement that Mark Twain — one of the best writers in American history — might even shout from the rooftop.
Broad, wholesome, charitable views of [people] … cannot be acquired by vegetating in one little corner of the earth all one’s lifetime. — Mark Twain
In the eyes of Drini Cami and Mark Twain, books are like miniature time machines that have the power to launch readers into new spaces while changing their behaviors at the same time. For it is only when a reader steps out of their corner of the earth that they can step forward towards becoming a better person — for the entire world.
Connecting two worlds of data
Open Library has gone far beyond the extra mile to provide data about author demographics that some readers may not realize. It started with Open Library’s commitment to providing its readers with what Drini Cami describes as “clean, organized, structured, queryable data.” Simply put, readers can trust that Open Library’s data can be used to provide its audiences with maximum value. Which begs the question, where is all that ‘value’ coming from?
Drini Cami calls it “linked data”. In not so complex terms, you may think of linked data as being two or more storage sheds packed with data. When these storage sheds are connected, well… that’s when the magic happens. For Open Library, that magic starts at the link between Wikidata and Open Library knowledge bases.
Wikidata, a non-profit community-powered project run by Wikimedia, the same team which brought us Wikipedia, is a “free and open knowledge base that can be read and edited by both humans and machines”. It’s like Wikipedia except for storing bite-sized encyclopedic data and facts instead of articles. If you look closely, you may even find some of Wikidata’s data being leveraged within Wikipedia articles.
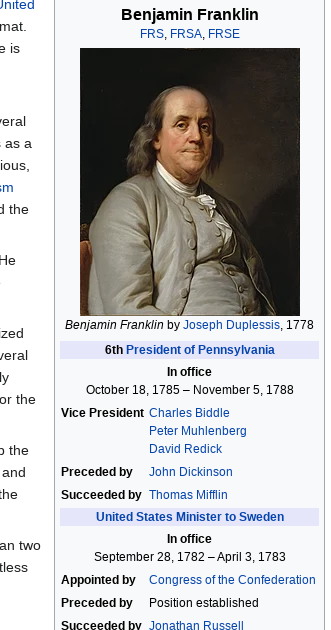
Wikipedia’s Summary Info Box 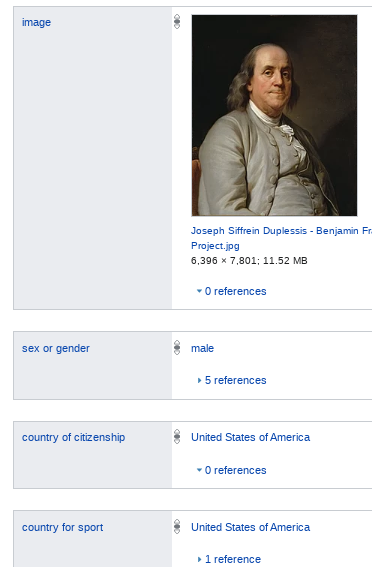
Source data in Wikidata
Wikidata is where Open Library gets its author demographic data from. This is possible because the entries on Wikidata often include links to source material such as books, authors, learning materials, e-journals, and even to other knowledge bases like Open Library’s. Because of these links, Open Library is able to share its data with Wikidata and often times get back detailed information and structured data in return. Such as author demographics.
Wrangling in the Data
Linking-up services like Wikidata and Open Library doesn’t happen automatically. It requires the hard work of “Metadata Wranglers”. That’s where Charles Horn comes in, the lead Data Engineer at Open Library — without his work, author stats would not be possible.
Charles Horn works closely with Drini Cami and also the team at Wikidata to connect book and author resources on Open Library with the data kept inside Wikidata. By writing clever bots and scripts, Charles and Drini are able to make tens of thousands of connections at scale. To put it simply, as both Open Library and Wikidata grow, their resources and data will become better connected and more accurate.
Thanks to the help of “Metadata Wranglers”, Open Library users will always have the smartest results — right at their fingertips.
It’s in a book …
Once Upon a Time, ten-time Grammy Award Winner Chaka Kahn greeted television viewers with her bright voice on the once-popular book reading program, Reading Rainbow. In her words, she sang … “Friends to know, and ways to grow, a Reading Rainbow. I can be anything. Take a look, it’s in a book …”
Thanks to Open Library’s author stats, not only do readers have the power to “take a look” into books, they can see further, and truly change what they see.
Try browsing your author stats and consider following Open Library on twitter.
What did you learn about your favorite authors? Please share in the comments below.