Setbacks: 2025 has been a challenging year for the Open Library community and the library world. We began the year by upgrading our systems in response to cybersecurity incidents and fortifying our web services to withstand relentless DDOS (distributed denial of service) attacks from bots. We developed revised plans to achieve More with Less to meet the needs of patrons who lost access to 500,000 books due to late-2024 takedowns. The year continued to bring setbacks, including a Brussels Court order, which resulted in additional removals, and contesting thousands of spammy automated takedown requests from an AI company. Just last month, we responded to a power outage affecting one of our data centers and then a cut that was identified in one of our internet service provider’s fiberoptic cables, resulting in reduced access.
Given all these setbacks, why weren’t we seeing a decline in sign-ups?
Less is More: Putting patrons’ experience first. As the year progressed and we reviewed our quarterly numbers, one metric that circumstantially held high was sign-ups. The Open Library is historically a significant source of registrations for the Internet Archive, contributing to approximately 30% of all registrations. Some websites may have found it reassuring that, despite all the challenges presented in 2024 and 2025, adoption seemed to keep its pace. At the Open Library, we measure success in value delivered to readers — not registrations — and this trend seemed to indicated something may have become out of balance:
What reason(s) might explain why registrations remain steady when significant sources of value are no longer accessible?
We hypothesized some class of patrons are signing up with an expectation and then not getting the value they are expecting.
Testing the hypothesis: The first step of our investigation was to take inventory of the possible reasons one might register an account. Each of the following actions require accounts:
Borrowing a book
Using the Reading Log
Adding books to Lists
Community review tags
Following other readers
Reading Goals
Supporting Evidence: We started by reviewing the Reading Log because it’s the platform’s largest source of engagement, with 5M unique patrons logging 11.5M books. We discovered that millions of patrons had only logged a single book. There’s nothing inherently bad about this statistic, in fact many websites may be happy about this engagement. However, unlike many book catalog websites, the Open Library is unique in that it links to millions of books that may be accessed through trusted book providers. It is thus reasonable that many patrons come to the Open Library website with the intent of accessing a specific title. This data amplified occasional reports from patrons who expressed disappointed when clicking “Want to Read” did not result in access to the book.
Refined hypothesis: Based on these learnings, we felt confident the “Want to Read” button may be confusing new patrons who thought clicking the button would get them access to the book. Under this lens, each of these registrations represents adoption for the wrong reason: i.e. a patron is compelled by the offering to register, but they bounce because what they get is a broken promise.
Trying a solution: Data gave us confidence the “Want to Read” button may be confusing new visitors to the site, but it also revealed that hundreds of thousands of patrons are actively using the Reading Log to keep track of books and we didn’t want to confuse the experience for them. We decided to change the website so that non-logged-in patrons, would see the “Want to Read” button as “Add to List” instead, whereas logged-in returning visitors would continue to see the “Want to Read” button they were used to.
Before:The original button presented to patrons, which shows a potentially misleading: “Want to Read”After: The button presented to logged out patrons after the change, reading “Add to List” instead of “Want to Read”
Results: When our team launched this week’s deploy, we noticed a few performance hiccups: our latest deploy increased memory demands and our servers began using too much memory, causing swapping. After some fire-fighting, we were able to make adjustments to our workers that normalized performance, though we remained alert.
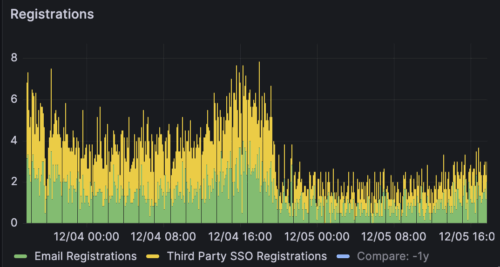
Later that night, we noticed a significant drop in registrations and started frantically testing the website:
We were thrilled to realize that our services are working correctly and the chart accurately reflected — what we hope to be — a decrease in bad experiences for our patrons.
Conclusion: Sometimes, less is more. We anticipate this will be the first small change in a long series of marginal improvements we hope to bring us closer into alignment with the core needs of our patrons. As we move towards 2026, we will continue to respond to the new normal shaped by recent events with the mantra: back to basics.
The Open Library is a card catalog of every book published spanning more than 50 million edition records. Fetching all of these records all at once is computationally expensive, so we use Apache Solr to power our search engine. This system is primarily maintained by Drini Cami and has enjoyed support from myself, Scott Barnes, Ben Deitch, and Jim Champ.
Our search engine is responsible for rapidly generating results when patrons use the autocomplete search box, when apps make book data requests using our programatic Search API, to load data for rending book carousels, and much more.
A key challenge of maintaining such a search engine is keeping its schema manageable so it is both compact and efficient yet also versatile enough to serve the diverse needs of millions of registered patrons. Small decisions, like whether a certain field should be made sortable can — at scale — make or break the system’s ability to keep up with requests.
This year, the Open Library team was committed to releasing several ambitious search improvements, during a time when the search engine was already struggling to meet the existing load:
Edition-powered Carousels that go beyond the general work to show you the most relevant, specific, available edition, in your desired language.
Trending algorithms that showcase what books are having sudden upticks, as opposed to what is consistently popular over stretches of time.
Rather than tout a success story (we’re still in the thick of figuring out performance day-by-day), our goal is to pay it forward, document our journey, and give others reference points and ideas for how to maintain, tune, and advance a large production search system with a small team. The vibe is “keep your head above water.”
Starting in the Red
Towards the third quarter of last year, the Internet Archive and the Open Library were victim to a large scale, coordinate DDOS attack. The result was significant excess load to our search engine and material changes in how we secured and accessed our networks. During this time, the entire Solr re-indexing process (i.e. the technical process for rebuilding a fresh search engine from the latest data dumps) was left in an broken state.
In this pressurized state, our first action was to tune Solr’s heap. We had allocated 10GB of RAM to the Solr instance but also the heap was allowed to use 10GB, resulting in memory exhaustion. When Scott lowered the heap to 8GB, we encountered fewer heap errors. This was compounded by the fact that previously, we dealt with long spikes of 503s by restarting Solr, causing a thundering herd problem where the server would restart just to be overwhelmed by heap errors.
With 8GB of heap, our memory utilization gradually rose until we were using about 95% of memory and without further tuning and monitoring, we had few options other than to increase RAM available to the host. Fortunately, we were able to grow from ~16GB to ~24GB. We typically operate within 10GB and are fairly CPU bound with a load average of around 8 across 8 CPUs.
We then fixed our Solr re-indexing flow, enabling us to more regularly “defragment” — i.e. run optimize on Solr. In rare cases, we’ve been able to split traffic between our prod-solr and staged-solr to withstand large spikes in traffic though typically we’re operating from a single Solr instance.
Even with more memory, there’s only so many long, expensive requests Solr can queue before getting overwhelmed. Outside of looking at the raw Solr logs, our visibility into what was happening across Solr was still limited, so we put our heads together to discuss obvious cases where the website makes expensive calls wastefully. Jim Champ helped us implement book carousels that load asynchronously and only when scrolled into view. He also switched the search page to asynchronously load the search facets sidebar. This was especially helpful as previously, trying to render expensive search facets would cause the entire search results page, as opposed to only the facets side menu, to fail.
Sentry on the Hill
After several tiers of low hanging fruit was plucked, we used more specific tools and added monitoring. First, we added sentry profiling which gave us much more clarity about which queries were expensive, and how often Solr errors were occurring.
Sentry allows us to see a panoramic view of our search performance.
Sentry also gives us the ability to drill in and explore specific errors and their frequencies.
With profiling, we can even explore individual function calls to learn where the process is spending the most amount of time.
Docker Monitoring & Grafana
To further increase our visibility, Drini developed a new type of monitoring docker container that can be deployed agnostically to each of our VMs and use environment variables so that only relevant jobs would be run for that host. This approach has allowed us to centrally configure recipes so each host collects the data it needs and uploads it to our central dashboards in Grafana.
Recently, we added labels to all of our Solr calls so we can view exactly how many requests are being made of each query type and what their performance characteristics are.
At a top level, we can see in blue how much total traffic we’re getting to Solr and the green colors (darker is better) lets us know how many requests are being served quickly.
We can then drill in and explore each Solr query by type, identifying which endpoints are causing the greatest strain and giving us a way to then analyze nginx web traffic further in case it is the result of a DDOS.
Until recently, we were able to see how hard each of our main Open Library web application works were working at any given time. Spikes of pink or purple were when Open Library was waiting for requests to finish from Archive.org. Yellow patches — until recently — were classified as “other,” meaning we didn’t know exactly what was going on (even though Sentry profiling and flame graphs gave us strong clues that Solr was the culprit). By using pyspy with our new docker monitoring setup, we were able to add Solr profling into our worker graphs on Grafana and visualize the complete story clearly:
Once we turned on this new monitoring flow, it was clear these large sections of yellow, where workers were inundated with “unknown” work, were almost entirely (~50%) Solr.
With Great Knowledge…
Each graph helped us further direct and focus our efforts. Once we knew Open Library was being slowed down primarily by Solr, we began investigating requests and Drini noticed many Solr requests were living on for more than 10 seconds, even though the Open Library app has been given instructions to abandon any Solr query that takes more than 10 seconds. It turns out, even in these cases, Solr may continue to process the query in the background (so it can finish and cache the result for the future). This “feature” was resulting in Solr’s free connections becoming exhausted and a long haproxy queue. Drini modified our Solr queries to include a timeAllowed parameter to match Open Library’s contract to quit after 10 seconds and almost immediately the service showed signs of recovery:
After we set the timeAllowed parameter, we began to encounter more clear examples of queries failing and investigated patterns within Sentry. We realized a prominent trends of very expensive, unuseful, one-character or stop-word-like queries like “*" or “a" or “the". By looking at the full request and url parameters in our nginx logs, we discovered that the autocomplete search bar was likely responsible for submitting lots of unuseful requests as patrons typed out the beginning of their search.
To fix this, we patched our autocomplete to require at least 3 characters (and not e.g. the word “the”) and also are building in backend directives to Solr to pre-validate queries to avoid processing these cases.
Conclusion
Sometimes, you just need more RAM. Sometimes, it’s really important to understand how complex systems work and how heap space needs to be tuned. More than anything, having visibility and monitoring tools have bee critical to learning which opportunities to pursue in order to use our time effectively. Always, having talented, dedicated engineers like Drini Cami, and the support of Scott Barnes, Jim Champ, and many other contributors, is the reason Open Library is able to keep running day after day. I’m proud to work with all of you and grateful for all the search features and performance improvements we’ve been able to deliver to Open Library’s patrons in 2025.
Over the course of 2023, the Open Library team conducted design research and video-interviewed nine volunteers to determine how learners and educators make use of the OpenLibrary.org platform, what challenges get in their way, and how we can help them succeed. Participants of the study included a mix of students, teachers, and researchers from around the globe, spanning a variety of disciplines.
About the Participants
At the earliest stages of this research, a screener survey involving 466 participants helped us understand the wide range of patrons who use the Open Library. Excluding 141 responses that didn’t match the criteria of this research, the remaining 325 respondents identified as:
126 high school, university, or graduate students
64 self learners
44 researchers
41 K-12 teachers
29 professors
12 parents of K-12 students
9 librarians
Participants reported affiliations with institutions spanning a diverse variety of geographies, including: Colombia, Romania, France, Uganda, Indonesia, China, India, Botswana, Nigeria, and Ireland.
Findings
A screenshot of the Findings section of the collaborative Mural canvas, filled with digital sticky notes
Here are the top 7 learnings we discovered from this research:
The fact that the Open Library is free and accessible online is paramount to patrons’ success. During interviews, several participants told us that the Open Library helps them locate hard to find books they have difficulty finding elsewhere. At least two participants didn’t have access to a nearby library or a book vendor that could provide the book they needed. In a recent Internet Archive blog post, several patrons corroborated these challenges. In addition to finding materials, one or more of our participants are affected by disabilities or have worked with such persons who have limited mobility, difficulty commuting, and benefit from online access. Research use cases also drove the necessity for online access: At least two interviewed participants used texts primarily as references to cite or verify certain passages. The ability to quickly search for and access specific, relevant passages online was essential to helping them to succeed at their research objective, which may have otherwise been prohibitively expensive or technologically intractable.
Participants voiced the importance of internationalization and having books in multiple languages. Nearly every participant we interviewed advocated for the website and books to be made available in more languages. One participant had to manually translate sections of English books into Arabic for their students. Another participant who studied classic literature manually translated editions so they could be compared. A teach who we interviewed relayed to us that it was common for their ESL (English as a Second Language) students to ask for help translating books from English into their primary language.
The interests of learners and educators who use the Open Library vary greatly. We expected to find themes in the types of books learners and educators are searching for. However, the foci of participants we interviewed spanned a variety of topics, from Buddhism, to roller coaster history, therapy, technical books, language learning materials, and classic literature. Nearly none of our candidates were looking for the same thing and most had different goals and learning objectives. One need they all have in common is searching for books.
The Open Library has many educational applications we hadn’t intended. One or more participant reported they had used the read aloud feature in their classroom to help students with phonics and language learning. While useful, participants also suggested the feature sometimes glitches and robotic sounding voices are a turnoff. We also learned several educators and researchers link to Open Library when creating course syllabi for their students.
Many of Open Library subject and collection pages weren’t sufficient for one or more of our learners and educators use cases. At least two interviewees ended up compiling their own collections using their own personal web pages and linking back to the Open Library. One participant tried to use Open Library to search for K-12, age-appropriate books pertaining to the “US Constitution Day” and was grateful for but underwhelmed by the results.
The Open Library service & its features are difficult to discover.
Several interviewees were unaware of Open Library’s full-text search, read aloud, or note-taking capabilities, yet expressed interest in these features.
Many respondents of the screener survey believed their affiliated institutions were unaware of the Open Library platform.
Open Library’s community is generous, active, and eager to participate in research to help us improve. Overall, 450+ individuals from 100+ institutions participated in this process. Previously, more than 2k individuals helped us learn how our patrons prefer to read and more than 750 participants helped us redesign our book pages.
Some of our learnings we had already predicted and seeing these predictions confirmed by data has also given us conviction in pursuing next steps. Some learnings were genuinely surprising to us, such as many teachers preferring the online web-based book reader because it doesn’t require them to install any extra software on school computers.
Proposals
After reviewing this list of findings and challenges, we’ve identified 10 areas where the Open Library may be improved for learners and educators around the globe:
Continuing to make more books available online by expanding our Trusted Book Providers program and adding Web Books to the catalog.
Participating in outreach to promote platform discovery & adoption. Connect with institutions and educators to surface opportunities for partnership, integration, and to establish clear patterns for using Open Library within learning environments.
Adding onboarding flow after registration to promote feature discovery. Conduct followup surveys to learn more about patrons, their challenges, and their needs. Add an onboarding experience which helps newly registered patrons become familiar with new services.
Making books available in more languages by prototyping the capability to translate currently open pages within bookreader to any language, on-the-fly.
Creating better subject and collection page experiences bygiving librarians tools to create custom collection pages and tag and organize books in bulk.
Improving Read Aloud by using AI to generate more natural/human voices, make the feature more discoverable in the bookreader interface, and fix read aloud navigation so it works more predictably.
Allowing educators to easily convert their syllabi to lists on Open Library using a Bulk Search & List creator feature.
Moving to a smarter, simpler omni-search experience that doesn’t require patrons to switch modes in order to get the search results they want.
Importing missing metadata and improving incomplete records by giving more librarians better tools for adding importers and identifying records with missing fields.
Improving the performance and speed of the service so it works better for more patrons in more areas.
About the Process
The Open Library team was fortunate to benefit from the guidance and leadership of Abbey Ripstra, a Human-Centered Design Researcher who formerly led Design Research efforts at the Wikimedia organization. This research effort wouldn’t have been achievable without her help and we’re grateful.
In preparation for our research, Abbey helped us outline a design process using an online collaboration and presentation tool called Mural.
During the planning process, we clarified five questions:
What are the objectives of our research?
How will we reach and identify the right people to speak with?
What questions will we ask interview participants?
How will we collate results across participants and synthesize useful output?
How can we make participants feel comfortable and appreciated?
To answer these questions, we:
Developed a Screener Survey survey which we rendered to patrons who were logged in to OpenLibrary.org. In total, 466 patrons from all over the world completed the survey, from which we identified 9 promising candidates to interview. Candidates were selected in such a way as to maximize the diversity of academic topics, coverage of geographies, and roles within academia.
We followed up with each candidate over email to confirm their interest in participating, suggesting meeting times, and then sent amenable participants our Welcome Letter and details of our Consent Process.
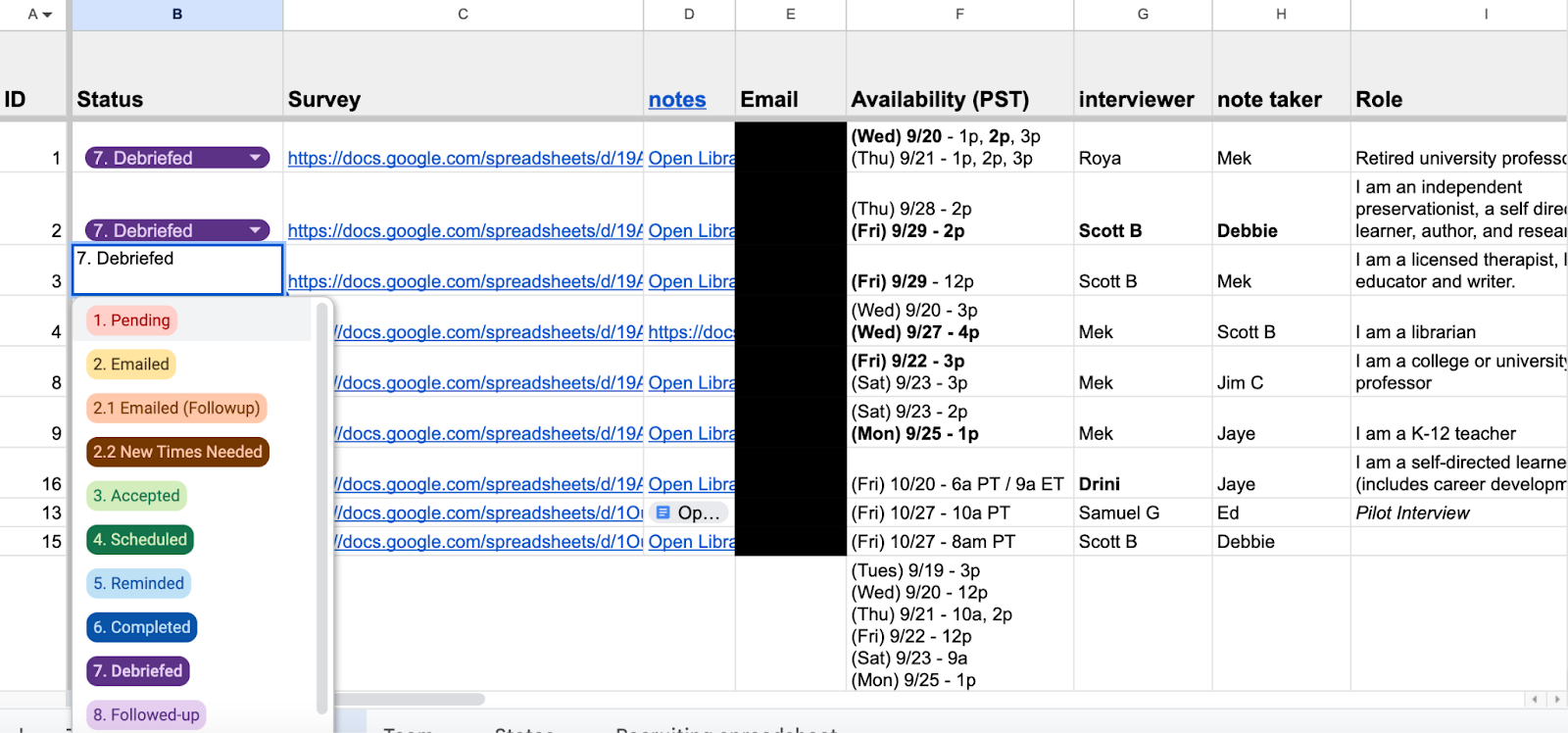
We coordinated interview times, delegated interview and note taking responsibilities, and kept track of the state of each candidate in the process using an Operations Tracker we built using Google Sheets:
During each interview, the elected interviewer followed our Interviewer’s Guide while the note taker took notes. At the end of each interview, we tidied up our notes and debriefed by adding the most salient notes to a shared mural board.
When the interviewing stage had concluded, we sent thank you notes and small thank you gifts to participants. Our design team then convened to cluster insights across interviews and surface noteworthy learnings.
For several years and with much gratitude, the Internet Archive has participated in Google’s Summer of Code (GSoC). GSoC is a program run by Google that supports select open source projects, like the Open Library, by generously funding students to intern with them for a summer. Participation in GSoC is as selective of organizations as it is for students and so in years when GSoC is not available to the Internet Archive, we try to fund our own Internet Archive Summer of Code (IASoC) paid fellowship opportunity.
GSoC and IASoC are traditionally limited to software engineering candidates which has meant that engineering contributions on Open Library have often outpaced its design. This year, to help us take steps towards righting this balance, an exceedingly generous donor (who wishes to remain anonymous but who is no less greatly appreciated) funded our first ever Internet Archive Summer of Design fellowship which was awarded to Hayoon Choi, a senior design student at CMU. In this post, we’re so excited to introduce you to Hayoon, showcase the impact she’s made with the Open Library team through her design work this summer, and show how her contributions are helping lay the groundwork to enable future designers to make impact on the Open Library project!
Introducing Hayoon Choi
Hello, my name is Hayoon Choi and this summer I worked as a UX designer with Open Library as part of the Internet Archive Summer of Code & Design fellowship program. I am a senior attending Carnegie Mellon University, majoring in Communication Design and minoring in HCI. I’m interested in learning more about creative storytelling and finding ways to incorporate motion design and interactions into digital designs.
Problem
When I first joined the Open Library team, the team was facing three design challenges:
There was no precedent or environment for rapidly prototyping designs
The website didn’t display well on mobile devices, which represents and important contingency of patrons.
Approach
In order to solve these challenges, I was asked to lead two important tasks:
Create a digital mockup of the existing book page (deskop and mobile) to enable rapid prototyping
A propose a redesign of the book page optimized for mobile.
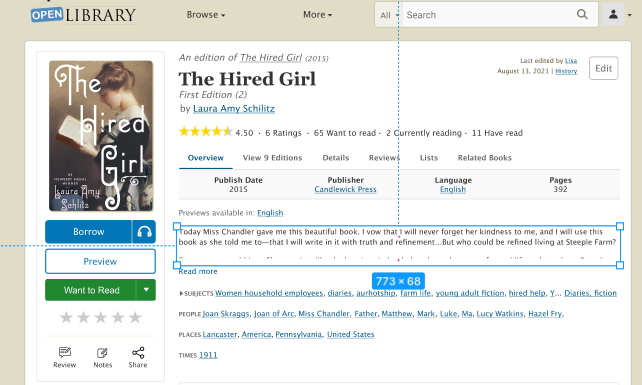
To achieve the first task, I studied the current design of the Open Library Book Page and prototyped the current layout for both mobile and desktop using Figma. In the process, I made sure every element of that Figma file is easily editable so that in the future, designers and developers can explore with the design without having to code.
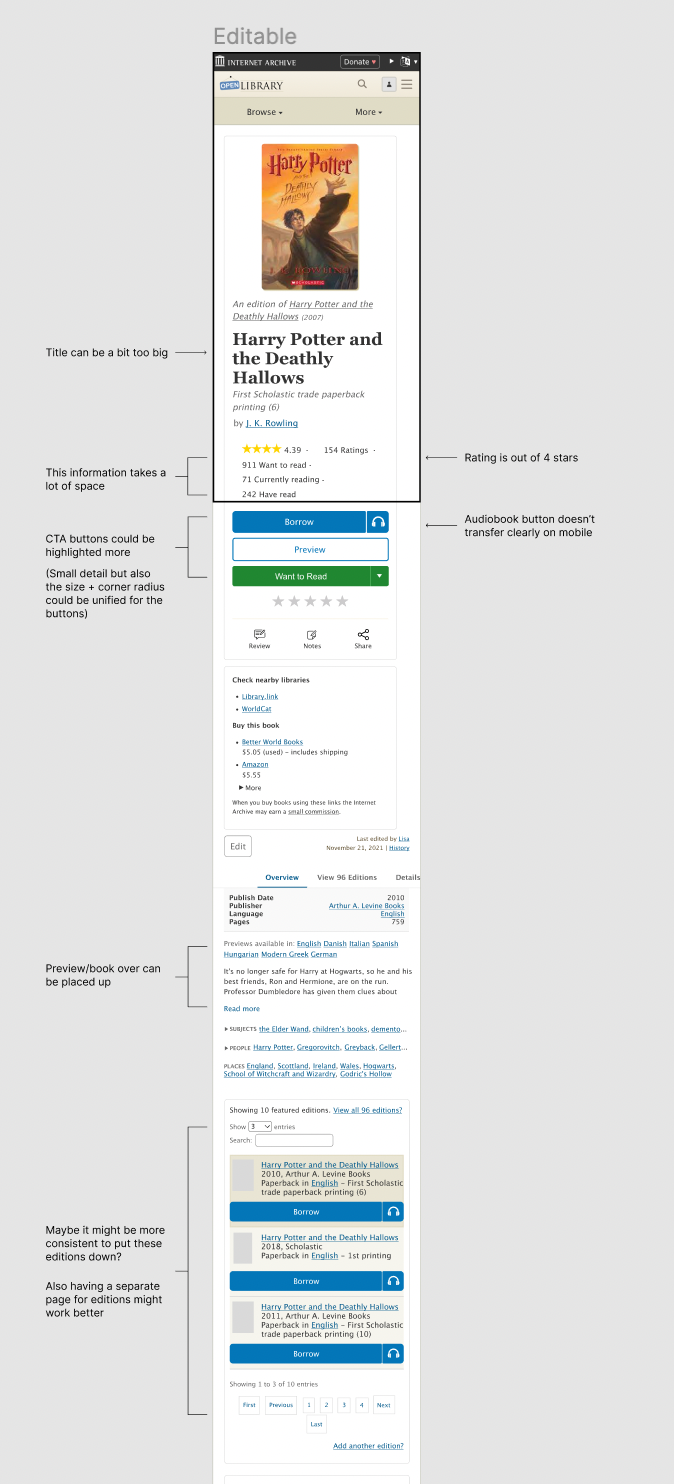
For the second task, we first scoped our work by setting our focus to be the set of content which appears above the fold — that is, the content which first loads and appears within the limited viewport of a mobile device. We wanted to make sure that when the page initially loads, our patrons are satisfied with the experience they receive.
Even before conducting interviews with patrons, there were easily identifiable design issues with the current mobile presentation:
Information hierarchy: some texts were too big; certain information took up too much space; placement of the book information were hard to discover
Not mobile friendly: Some images were shown too small on images; it was hard to scroll through the related books; one feature included hovering, which is not available on mobile devices
To address these concerns, I worked with the Open Library community to receive feedback and designed dozens of iterations of the mobile book page using Figma. Based on feedback I learned about the most necessary information to be presented above-the-fold, I choose to experiment with 6 elements:
The primary Call To Action (CTA) buttons: how do I make them more highlighted?
The Navigation Bar: which placement and styling are most convenient and effective?
The Editions Table: how might we make it easier for patrons to discover which other book editions and languages may be available?
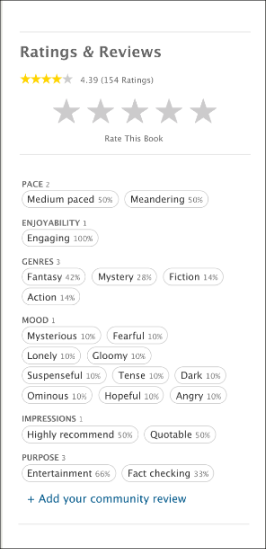
Ratings & reviews: how do I encourage users to rate more and help them understand the book effectively with the review system?
Sharing: how do I make it easier for users to share the book?
The Information Hierarchy: how can we reorder content to better meet the diverse needs of our audience?
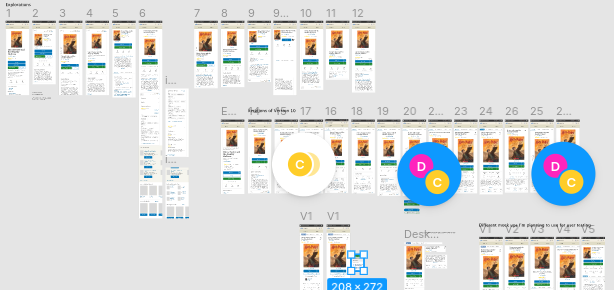
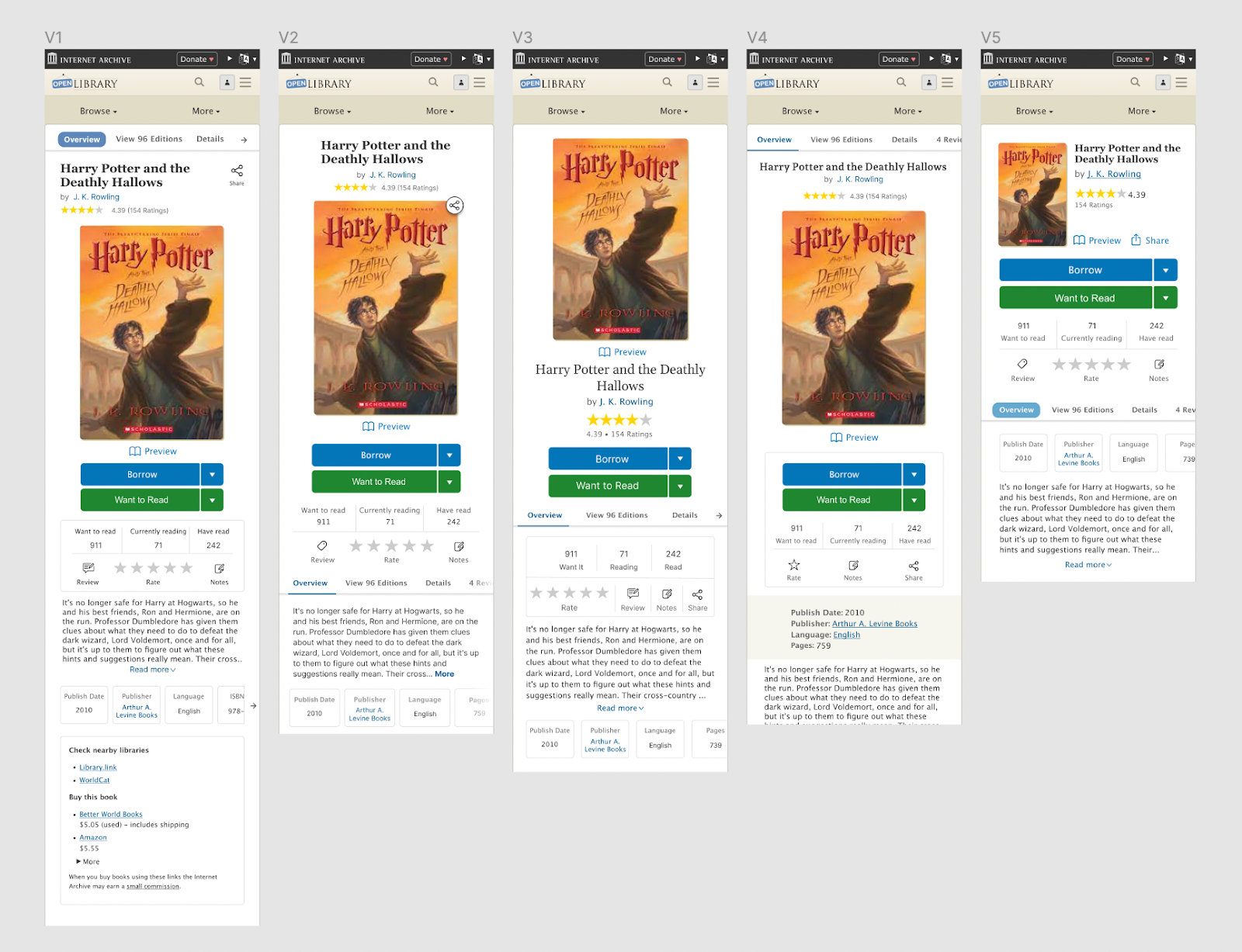
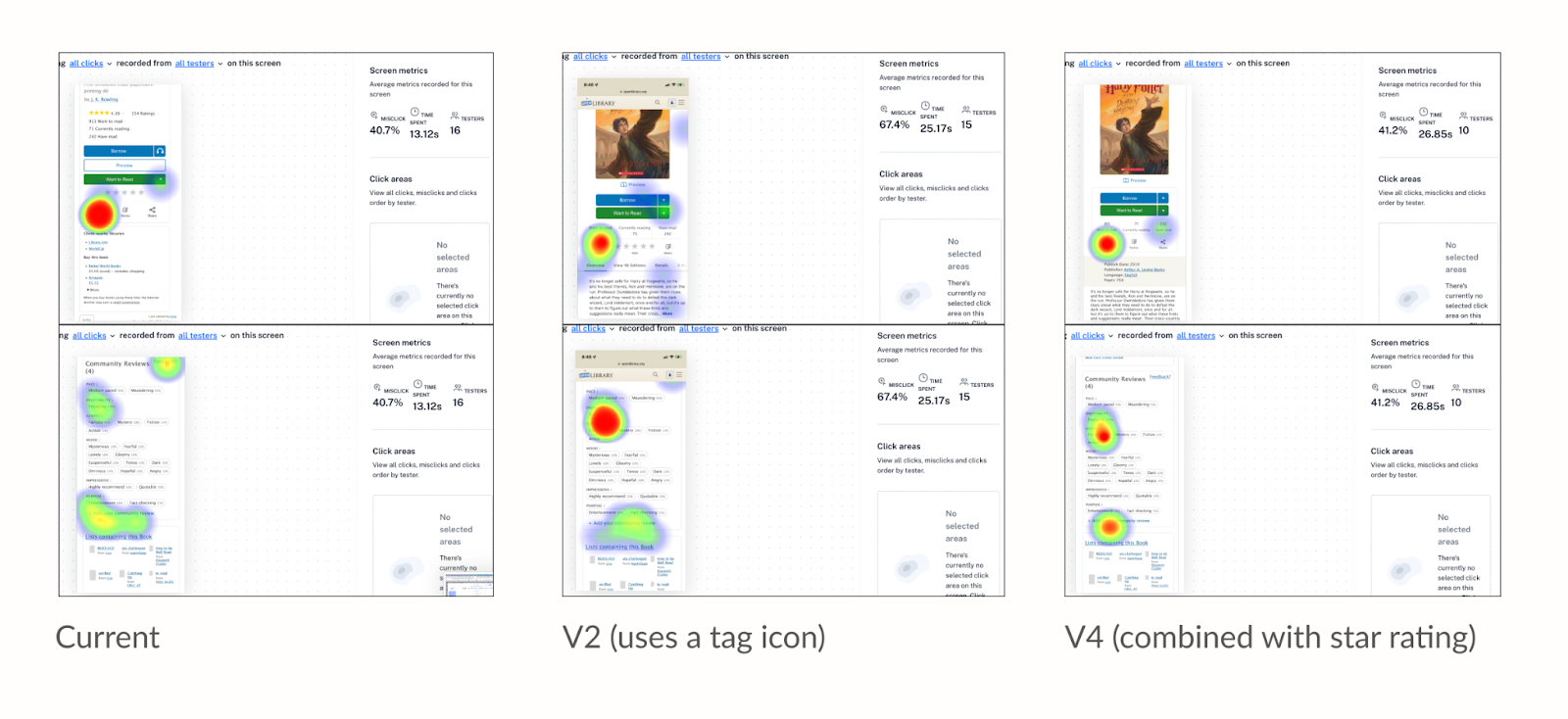
From these questions and feedback from the Open Library team, I was able to settle on five designs which seemed like effective possibilities for showcasing differences in book cover size, sharing buttons, information display, and rating and reviewing system which we wanted to test:
User Interviews& Mazes
With these five designs selected, I planned on running multivariate user testings to get feedback from actual users and to understand how I can more effectively make improvements to the design.
I believed that I would gather more participants if the user testing was done remotely since it would put less pressure on them. However, I wasn’t sure how I would do this until I discovered a tool called Maze.
Maze provides a way for patrons to interact with Figma mockups, complete certain tasks, answer questions, and leave feedback. While this is happening, Maze can record video sessions, keep track of where patrons are clicking, and provide valuable data about success rates on different tasks. I felt this service could be extremely useful and fitting for this project; therefore I went ahead and introduced Maze to the Open Library’s team. Thanks to a generous 3-month free partner coupon offered by Maze, I was able to create six Maze projects — one for each of our five new designs, as well as our current design as a control for our experiment. Each of these six links were connected to a banner that appeared across the Open Library website for a week. Each time the website was reloaded, the banner randomized the presented link so participants would be evenly distributed among the six Maze projects.
Although the Maze projects showed patrons different mobile screens, they enabled comparisons of functionality by asking patrons to answer the same pool of 7 questions and tasks:
What was the color of the borrow button (after showing them the screen for five seconds)
What key information is missing from this screen (while showing the above-the-fold screen)
Share and rate this book
Borrow the Spanish edition for this book
Try to open a Spanish edition
Review this book
Try to open the preview of this book
In between these tasks, the participants were asked to rate how challenging these tasks were and to write their feelings or opinions.
In addition to Maze, which we hoped would help us scale our survey to reach a high volume of diverse participants, we also conducted two digital person-to-person user interviews over Zoom to get more in depth understanding about how patrons approach challenging tasks. Because Maze can only encode flows we program directly, these “in person” interviews gave us the ability to intervene and learn more when patrons became confused.
Results & Findings
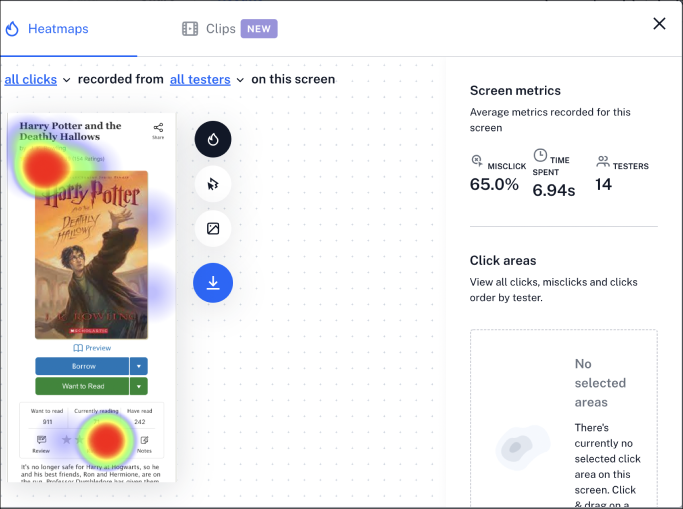
After around a week of releasing the Maze links on the website, we were able to get a total of 760 participants providing feedback on our existing and proposed designs. Maze provided us with useful synthesis about how long it took participants to complete tasks and showed a heat map of where patrons were clicking (correctly or incorrectly) on their screens. These features were helpful when evaluating which designs would better serve our patrons. Here’s a list of findings I gathered from Maze:
The Sharing Feature:
Results suggest that the V1 design was most clear to patrons for the task of sharing the book. It was surprising to learn patrons, on average, spent the most time completing the task on this same design. Some patrons provided feedback which challenged our initial expectations about what they wanted to accomplish, reporting that they were opposed to sharing a book or that their preferred social network was not included in the list of options.
Giving a book a Star Rating:
One common reaction for all designs was that people expected that clicking on the book’s star ratings summary would take them to a screen where they could rate the book. It was surprising and revealing to learn that many patrons didn’t know how to rate books on our current book page design!
Leaving a Community Review
When participants were asked to leave a community review, some scrolled all the way down the screen instead of using the review navigation link which was placed above the fold. In design V4, using a Tag 🏷️ icon for a review button confused many people who didn’t understand the relationship between book reviews and topic tags. In addition, the designs which tested combining community review tags and star ratings under a single “review” button were not effective at supporting patrons in the tasks of rating or reviewing books.
Borrowing Other Editions
Many of our new designs featured a new Read button with a not-yet-implemented drop down button. While it was not our intention, we found many people clicked the unimplemented borrow drop down with the expectation that this would let them switch between other available book editions, such as those in different languages. This task also taught us that a book page navigation bar at the top of the design was most effective at supporting patrons through this task. However, after successfully clicking the correct navigation button, patrons had a difficult time using the provided experience to find an borrow a Spanish edition within the editions table. Some patrons expected more obvious visual cues or a filtering system to more easily distinguish between available editions in different languages.
Synthesis
By synthesizing feedback across internal stakeholders, user interviews, and results from our six mazes, we arrived at a design proposal which provides patrons with several advantages over today’s existing design:
First and foremost, redesigned navigation at the very top of the book page
A prominent title & author section which showcases the book’s star ratings and invites the patron to share the book.
A large, clear book cover to orient patrons.
An actionable section which features a primary call to action of “Borrow”, a “Preview” link, and a visually de-emphasized “Want to Read” button. Tertiary options are provided for reviewing the book and jotting notes.
Below the fold, proposals for a re-designed experience for leaving reviews and browsing other editions.
(Before)
(After)
Reflections
I had a great time working with Open Library and learning more about the UX field. I enjoyed the process of identifying problems, iterating, and familiarizing myself with new tools. Throughout my fellowship, I got great feedback and support from everyone from the team, especially my mentor Mek. He helped me plan an efficient schedule while creating a comfortable working environment. Overall, I truly enjoyed my working experience here and I hope my design works will get to help patrons in the future!
About the Open Library Fellowship Program
The Internet Archive’s Open Library Fellowship is a flexible, self-designed independent study which pairs volunteers with mentors to lead development of a high impact feature for OpenLibrary.org. Most fellowship programs last one to two months and are flexible, according to the preferences of contributors and availability of mentors. We typically choose fellows based on their exemplary and active participation, conduct, and performance within the Open Library community. The Open Library staff typically only accepts 1 or 2 fellows at a time to ensure participants receive plenty of support and mentor time. Occasionally, funding for fellowships is made possible through Google Summer of Code or Internet Archive Summer of Code & Design. If you’re interested in contributing as an Open Library Fellow and receiving mentorship, you can apply using this form or email openlibrary@archive.org for more information.