A major update to the Open Library search engine now makes it easy for patrons to find books that are receiving spikes of interest.
You may be familiar with the trending books featured on Open Library’s home page. Actually, you might be very familiar with them, because many seldom change! Our previous trending algorithm approximated popularity by tracking how often patrons clicked that they wanted to read a book. While this approach is great for showcasing popular books, the results often remain the same for weeks at a time.
The new trending algorithm, developed by Benjamin Deitch (Open Library volunteer and Engineering Fellow) and Drini Cami (Open Library staff and senior software engineer) uses hour-by-hour statistics to give patrons fresh, timely, high-interest books that are gaining traction now on Open Library.
This improved algorithm now powers much of the Open Library homepage and is fully integrated into Open Library’s search engine, meaning:
A patron can sort any search on Open Library by trending scores. Check out what’s trending today in Sci-fi, Romance, and Short-reads in French.
A more diverse selection of books should be displayed within the carousels on the homepage, the library explorer, and on subject pages.
Librarians can leverage sort-by-trending to discover which high-traffic book records may be impactful to prioritize.
Sorting by Trending
From the search results page, a patron may change the “Relevance” sort dropdown to “Trending” to sort results by the new z-score trending algorithm:
The Algorithm
Open Library’s Trending algorithm is implemented by computing a z-score for each book, which compares each book’s: (a) “activity score” over the last 24 hours with (b) the total “activity score” of the last 7 days.
Activity scores are computed for a given time interval by adding the book’s total human page views (how often is the book page visited) with an amplified count of its reading log events (e.g. when a patron marks a book as “Want to Read”). Here, amplified means that a single reading log event has a higher impact on the activity score than a single page view.
All of the intermediary data used to compose the z-score is stored and accessible from our search engine in the following ways:
For Developers
While the trending_z_score is the ultimate value used to determine a book’s trending score on Open Library, developers may also query the search engine directly to access many of the intermediary, raw values used to compute this score.
For instance, we’ve been experimenting with the trending_score_daily_[0-6] fields and the trending_score_hourly_sum field to create useful ways of visualizing trending data as a chart over time:
The search engine may be queried and filter by:
trending_score_hourly_sum – Find books with the highest accumulative hourly score for today, as opposed to the computed weekly trending score.
trending_score_daily_0 through trending_score_daily_6 – Find books with a certain total score on a previous day of the week.
trending_z_score:{0 TO *] – Find books with a trending score strictly greater than 0. Note that this is using Lucene syntax, so squiggly brackets {} can be used for an exclusive range, and square brackets [] for an inclusive range.
The results of these queries may be sorted by:
trending – View books ordered by the greatest change in activity score growth first. This uses the trending_z_score.
trending_score_hourly_sum – View books with the highest activity score in the last 24 hours
We’d love your feedback on the new Trending Algorithm. Share your thoughts with us on bluesky.
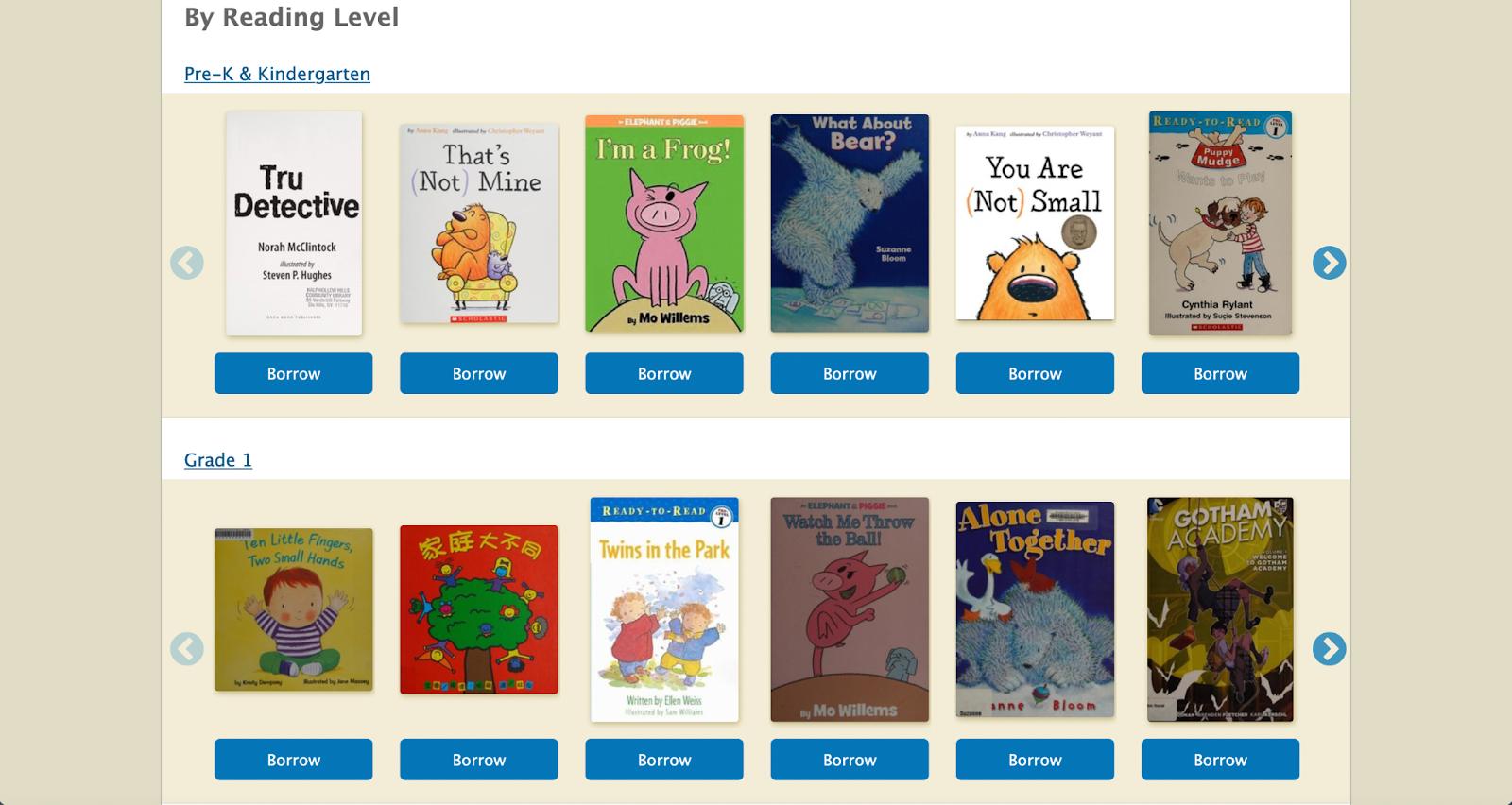
We recently improved the relevance of our Student Library collection by adding more than 10,000 reading levels to borrowable K-12 books in our search engine.
What are Reading Levels?
In the same way a library-goer may be interested in finding a book on a specific topic, like vampires, they may also be interested in narrowing their search for books that are within their reading level. The readability of a book may be scored in numerous ways, such as analyzing sentence lengths or complexity, or the percentage of words that are unique or difficult, to name a few.
For our purposes, we choose to incorporate Lexile scores—a proprietary system developed by MetaMetrics®. Lexile scores are widely used within school systems and have a reliable scoring system that is accessible and well documented.
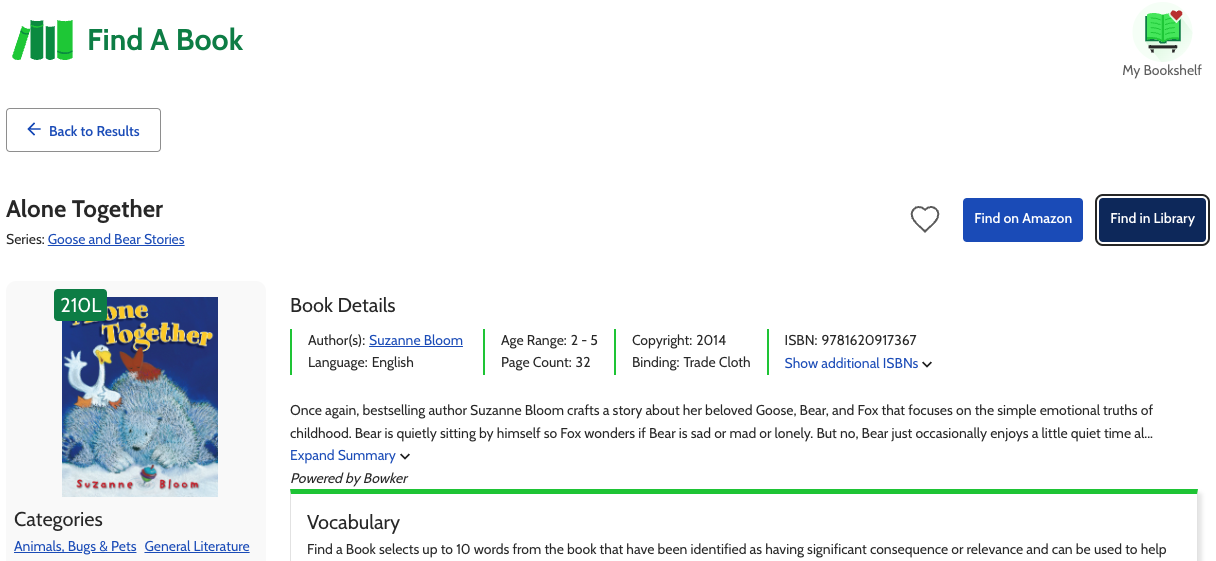
While the goal of our initiative was to add reading levels specifically for borrowable K-12 books within the Open Library catalog, Lexile also offers a fantastic Find a Book hub where teachers, parents, and students may search more broadly for books by Lexile score. We’re grateful that Lexile features “Find in Library” links to the Open Library so readers can check nearby libraries for the books they love!
Before Reading Levels
Before Open Library had reading level scores, the system used subject tags to identify books according to grade level. Many of these categories were noisy, inaccurate, and had high overlap, making it difficult to find relevant books. Furthermore, with grade level bucketing, there was no intuitive way to search for books across a range of reading levels.
Searching for Books by Reading Level
Now, lexile score ranges like “lexile:[500 TO 900]” can be used flexibly in search queries to find the exact books that are right for a reader, with results being limited by grade levels. https://openlibrary.org/search?q=lexile%3A%5B700+TO+900%5D
Putting It All Together
By utilizing these lexile ranges, we’ve been able to develop a more coherent and expansive K-12 portal experience where there are fewer duplicate books across grade levels.
We expect this improvement will make it easier for K-12 students and teachers to find appropriate books to satisfy their reading and learning goals. You can explore the newly improved K-12 student collection at http://openlibrary.org/k-12.
What Do You Think?
Is there something you miss from the previous K-12 page? Is the new organization more useful to you? Share your thoughts on bluesky.
Credits
This reading level import initiative was led by Mek, the Open Library program lead, with assistance from Drini Cami, Open Library senior software engineer. The project received support from Jordan Frederick, an Open Library intern who shadowed this project as part of her Master’s in Library and Information Science (MLIS) degree.
A core aspect of Open Library’s mission is making the published works of humankind accessible to all readers, regardless of age, ability, or location. In service of this goal, the Internet Archive participates in a special access program to serve patrons who have certified print disabilities that impact their ability to read standard printed text. Individuals certified by qualifying authorities can access materials in accessible formats through their web browser or via protected downloads. These affordances are offered in accordance with the Marrakesh Treaty, which exists to “facilitate access to published works for persons who are blind, visually impaired or otherwise print disabled.”
The first hurdle individuals with print disabilities must clear before getting the access they require is discovering which organizations, like the Internet Archive, participate in special access programs. Previously, patrons would have to perform a google search or the Internet Archive’s help pages in order to learn about the special access offerings and the next steps for certification. The Internet Archive is excited to announce a new, streamlined process where patrons with qualifying print disabilities may apply for special access while registering for their free OpenLibrary.org account.
How to Request Special Print Disability Access
Starting May 15th, 2025, patrons who register for a free Internet Archive Open Library account will be presented with a checkbox option to “apply for special print disability access through a qualifying program.”
A screenshot showing the new checkbox on the registration page for patrons to request special print disability access.
Once this box is checked, the patron is prompted to select which qualifying program will certify the patron’s request for special access. This will be an organization like BARD, BookShare, ACE, or a participating university that has a relationship with the patron and can qualify their request.
A select box enables patrons to select the program through which they qualify for special print disability access.
Once the patron completes registration and logs in, they will receive an email with steps to either immediately apply their BARD or ACE credentials, or connect with their qualifying program to complete the certification process.
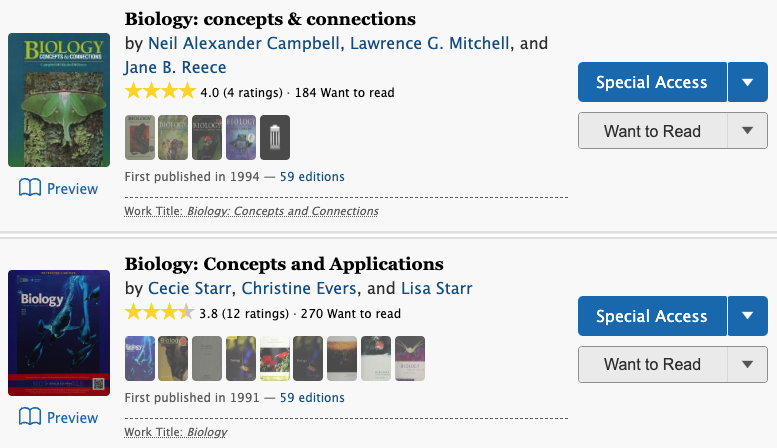
Once certified, print disabled patrons will have special access to a digital repository of more than 1.5 million accessible titles.
An example search result for “biology textbooks,” which shows blue Special Access buttons for patrons with certified print disabilities.
We hope these improvements will make our offerings more discoverable to those who need them and reduce unnecessary steps hindering access.
The Open Library team is committed to improving the enrollment process and accessibility offerings available to those with qualified print disabilities. If you find something about the experience difficult or confusing, or you have suggestions for how the process may be improved, please don’t hesitate to contact us. Navigate here for more information on the Internet Archive’s print disability special access program.
A special thank you to Open Library staff engineer Jim Champ for leading the development of these improvements.
By Jordan Frederick AKA Tauriel063 (she/her), Canada
When deciding where to complete my internship for my Master’s in Library and Information Science (MLIS) degree, Open Library was an obvious choice. Not only have I been volunteering as an Open Librarian since September 2022, but I have also used the library myself. I wanted to work with people who already knew me, and to work with an organisation whose mission I strongly believe in. Thus, in January 2025, I started interning at Open Library with Lisa Seaberg and Mek Karpeles as my mentors.
At the time of writing this, I am three courses away from completing my MLIS through the University of Denver, online. During my time as both a student and Open Librarian, I gained an interest in both cataloguing and working with collections. I decided to incorporate both into my internship goals, along with learning a little about scripting. Mek and Lisa had plenty of ideas for tasks I could work on, such as creating patron support videos and importing reading levels into the Open Library catalogue, which ensured that I had a well-rounded experience (and also never ran out of things to do).
The first few weeks of my internship centered largely around building my collection, for which I chose the topic of Understanding Artificial Intelligence (AI). Unfortunately, I can’t take credit for how well-rounded the collection looks presently, as I quickly realised that my goal to learn some basic coding was more challenging than I expected. If you happen to scroll to the bottom and wonder why there are over 80 revisions to the collection, that was because I spent frustrated hours trying to get books to display using the correct codes and repeatedly failed. It is because of Mek’s and Jim Champ’s coding knowledge that the collection appears fairly robust, although I suggested many of the sections within the collection, such as “Artificial Intelligence: Ethics and Risks” and “History of Artificial Intelligence.” However, Mek has informed me that the AI collection will likely continue to receive attention by the community for the remainder of the year, as part of the project’s yearly goals. I hope to see it in much better shape by the time of our annual community celebration in October.
The Artificial Intelligence Collection.
I successfully completed several cataloguing tasks, including adding 25 AI books to the catalogue. With the help of Scott Barnes, an engineer at the Internet Archive, I made these books readable. I also separated 36 incorrectly merged Doctor Who books and merged duplicate author and book records. Another project involved addressing bad data, where hundreds of book records had been imported into the catalogue under the category “Non renseigné,” with minimal information provided for each. While I was able to fix the previously conflated Doctor Who records, there are still over 300 records listed as “Non renseigné.” As such, this part of the project will extend beyond the scope of my internship.
I am particularly proud of this patron support video I created as part of my internship. It shows patrons how to create bookmarks and notes within a book they are reading, as well as how to search certain phrases or words within a book. I also created a video on how to use the audiobook feature in Open Library. Projects like these, assigned by Lisa, tie directly into my MLIS education, allowing me to put my education in meeting patrons’ needs to use. Lisa also asked me to look at the Open Library’s various “Help” pages and identify any issues such as broken links, misleading/inaccurate information, and more. This task allowed me to practice working with library documentation and to advocate for patrons’ needs by examining the pages through the perspective of a patron rather than that of a librarian.
First patron support video created.
I created a survey to determine patrons’ needs and wants regarding the AI collection. This, in the library profession, is referred to as a “patron needs assessment,” which is vital when building a collection. While it would certainly have been fun for me to create a collection purely based on my own interests, there is little point in developing a collection of interest to only one person. Mek gently reminded me of this, so I thought about how an AI collection may benefit patrons. Some potential uses for the collection I came up with were:
Understanding AI
The History of AI as a field
Leveraging AI for work
Ethics of AI
In order to determine patron perspectives on the collection, I developed a Google Forms survey, which asks questions such as:
In your own words, tell us what types of books you would like to see in an AI collection (some examples might include scientific research, effects on the future, and understanding AI).
What are you likely to use an AI collection for (eg. academic research, understanding how to use it, light reading)?
Do you have any recommendations for the collection?
Once this survey is made live, those involved in the collection will have a better idea of how to meet patrons’ needs.
While I had initially assumed that the collection would allow me to build up some collection-building skills and would hopefully benefit patrons with an interest in AI, Mek has since informed me that this collection ties in with the library’s yearly goals. In particular, the AI collection aligns with the goal of having “at least 10 librarians creating or improving custom collection pages” [2025 Planning]. Additionally, I have spent some time bulk-tagging various books (well over 100 by now), which also ties into the team’s 2025 goals. It’s gratifying to know my efforts during my internship will have far-reaching effects.
As with the AI collection, using reading levels to enhance the K-12 collection is still a work in progress. As I worked with Mek over the course of the last nine weeks, I learned more about the JSON data format than I ever knew before (which was nothing at all), what “comment out” means when running a script, and a general idea of what a key and a value are in a dictionary. So far, we’ve been able to match more than 11,000 ISBNs from Mid-Columbia library’s catalogue to readable items in the Open Library, allowing us to import reading levels for these titles and add them to the search engine.
Finally, I was offered the chance to work on my leadership skills when both Mek and Lisa asked me to lead one of our Tuesday community calls. While initially caught off guard, I rose to the challenge and led the call successfully. I certainly fumbled a few times and had to be reminded about what order to call on people for their updates (and ironically forgot Lisa before a few community members reminded me to give her a chance to speak). But I appreciated the chance to take on a more active role in the call and may consider doing so again in the future.
The last nine weeks have been both intense and highly educational. I am grateful I was able to complete my internship through Open Library, as I believe strongly in the organisation’s mission, enjoy working with people within its community, and intend to continue contributing for as long as possible. I would like to thank Mek and Lisa for making this internship possible and offering their guidance, Jim Champ for his help in coding the AI collection, and Scott Barnes for taking time out of his evening and weekend to assist me with JSON scripting (and patiently answering questions).
I look forward to continuing contributing to Open Library. If you’re interested in an even more in-depth view of the work I did during my internship, feel free to read my final paper.
This is a technical post regarding a breaking change for developers whose applications depend on the /search.json endpoint that is scheduled to be deployed on January 21st, 2025.
Description: This change reduces the default fields returned by /search.json to a more restrictive and performant set that we believe will meet most clients’ metadata needs and result in faster, higher quality service for the entire community.
Change: Developers are strongly encouraged to now follow our documentation to set the fields parameter on their requests with the specific fields their application requires. e.g:
Those relying on the previous behavior can still access the endpoint’s previous, full behavior by setting fields=* to return every field.
Reasoning: Our performance monitoring at Open Library has shown a high number of 500 responses related to search engine solr performance. During our investigation, we found that some endpoints, like search.json, return up to 500kb of payload and often return fields with large lists of data that are not frequently used by many clients. For more details, you can refer to the pull request implementing this change: https://github.com/internetarchive/openlibrary/pull/10350
As always, if you have questions or comments, please message us on x/twitter @openlibrary, bluesky, open an issue on github, or contact mek@archive.org.