

by Mek
Today Joe Alcorn, founder of readng, published an article (https://joealcorn.co.uk/blog/2020/goodreads-retiring-API) sharing news with readers that Amazon’s Goodreads service is in the process of retiring their developer APIs, with an effective start date of last Tuesday, December 8th, 2020.

The topic stirred discussion among developers and book lovers alike, making the front-page of the popular Hacker News website.

The Importance of APIs
For those who are new to the term, an API is a method of accessing data in a way which is designed for computers to consume rather than people. APIs often allow computers to subscribe to (i.e. listen for) events and then take actions. For example, let’s say you wanted to tweet every time your favorite author published a new book. One could sit on Goodreads and refresh the website every fifteen minutes. Or, one might write a twitter bot which automatically connects to Goodreads and checks real-time data using its API. In fact, the reason why Twitter bots work, is that they use Twitter’s API, a mechanism which lets specially designed computer programs submit tweets to the platform.
As one of the more popular book services online today, tens of thousands of readers and organizations rely on Amazon’s Goodreads APIs to lookup information about books and to power their book-related applications across the web. Some authors rely on the data to showcase their works on their personal homepages, online book stores to promote their inventory, innovative new services like thestorygraph are using this data to help readers discover new insights, and even librarians and scholastic websites rely on book data APIs to make sure their catalog information is as up to date and accurate as possible for their patrons.
For years, the Open Library team has been enthusiastic to share the book space with friends like Goodreads who have historically shown great commitment by enabling patrons to control (download and export) their own data and enabling developers to create flourishing ecosystems which promote books and readership through their APIs. When it comes to serving an audience of book lovers, there is no “one size fits all” and we’re glad so many different platforms and APIs exist to provide experiences which meet the needs of different communities. And we’d like to do our part to keep the landscape flourishing.
“The sad thing is it [retiring their APIs] really only hurts the hobbyist projects and Goodreads users themselves.” — Joe Alcorn

At Open Library, our top priority is pursuing Aaron Swartz‘s original mission: to serve as an open book catalog for the public (one page for every book ever published) and ensure our community always has free, open data to unlock a world of possibilities. A world which believes in the power of reading to preserve our cultural heritage and empower education and understanding. We sincerely hope that Amazon will decide it’s in Goodreads’ best interests to re-instate their APIs. But either way, Open Library is committed to helping readers, developers, and all book lovers have autonomy over their data and direct access to the data they rely on.

Imports & Exports
In August 2020, one of our Google Summer of Code contributors Tabish Shaikh helped us implement an export option for Open Library Reading Logs to help everyone retain full control of their book data. We also created a Goodreads import feature to help patrons who may want an easy way to check which Goodreads titles may be available to borrow from the Internet Archive’s Controlled Digital Lending program via openlibrary.org and to help patrons organize all their books in one place. We didn’t make a fuss about this feature at the time, because we knew patrons have a lot of options. But things can change quickly and we want patrons to be able to make that decision for themselves.
For those who may not have known, Amazon’s Goodreads website provides an option for downloading/exporting a list of books from one’s bookshelves. You may find instructions on this Goodreads export process here. Open Library’s Goodreads importer enables patrons to take this exported dump of their Goodreads bookshelves and automatically add matching titles to their Open Library Reading Logs.
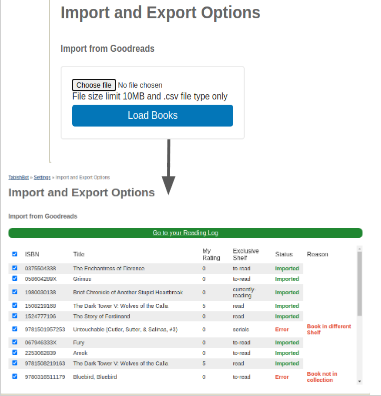
Known issues. Currently, Open Library’s Goodreads Importer only works for (a) titles that are in the Open Library catalog and (b) which are new enough to have ISBNs. Our staff and community are committed to continuing to improve our catalog to include more titles (we added more than 1M titles this year) and we plan to improve our importer to support other ID types like OCLC and LOC.
APIs & Data
Developers and book overs who have been relying on Amazon’s Goodreads APIs are not out of luck. There are several wonderful services, many of them open-source, including Open Library, which offer free APIs:
- Wikidata.org (by the same group who brought us Wikipedia) is a treasure trove of metadata on Authors and Books. Open Library gratefully leverages this powerful resource to enrich our pages.
- Inventaire.io is a wonderful service which uses Wikidata and Openlibrary data (API: api.inventaire.io)
- Bookbrainz.org (by the group who runs Musicbrainz) is a up-and-coming catalog of books
- WorldCat by OCLC offers various metadata APIs
Did we miss any? Please let us know! We’d love to work together, build stronger integrations with, and support other book-loving services.
Open Library’s APIs. And of course, Open Library has a free, open, Book API which spans nearly 30 million books.
Bulk Data. If you need access to all our data, Open Library releases a free monthly bulk data dump of Authors, Books, and more.
Spoiler: Everything on Open Library is an API!

One of my favorite parts of Open Library is that practically every page is an API. All that is required is adding “.json” to the end. Here are some examples:
Search
https://openlibrary.org/search?q=lord+of+the+rings is our search page for humans…
https://openlibrary.org/search.json?q=lord+of+the+rings is our Search API!
Books
https://openlibrary.org/books/OL25929351M/Harry_Potter_and_the_Methods_of_Rationality is the human page for Harry Potter and the Methods of Rationality…
https://openlibrary.org/books/OL25929351M.json is its API!
Authors
https://openlibrary.org/authors/OL2965893A/Rik_Roots is a human readable author page…
https://openlibrary.org/authors/OL2965893A.json and here is the API!
Did We Mention: Full-text Search over 4M Books?
Major hat tip to the Internet Archive’s Giovanni Damiola for this one: Folks may also appreciate the ability to full-text search across 4M of the Internet Archive’s books (https://blog.openlibrary.org/2018/07/14/search-full-text-within-4m-books) on Open Library:
You can try it directly here:
http://openlibrary.org/search/inside?q=thanks%20for%20all%20the%20fish
As per usual, nearly all Open Library urls are themselves APIs, e.g.:
http://openlibrary.org/search/inside.json?q=thanks%20for%20all%20the%20fish
Get Involved
Questions? Open Library is an free, open-source, nonprofit project run by the Internet Archive. We do our development transparently in public (here’s our code) and our community spanning more than 40 volunteers meets every week, Tuesday @ 11:30am Pacific. Please contact us to join our call and participate in the process.
Bugs? If something isn’t working as expected, please let us know by opening an issue or joining our weekly community calls.
Want to share thanks? Please follow up on twitter: https://twitter.com/openlibrary and let us know how you’re using our APIs!
Thank you
A special thank you to our lead developers Drini Cami, Chris Clauss, and one of our lead volunteer engineers, Aaron, for spending their weekend helping fix a Python 3 bug which was temporarily preventing Goodreads imports from succeeding.
A Decentralized Future
The Internet Archive has a history cultivating and supporting the decentralized web. We operate a decentralized version of archive.org and host regular meetups and summits to galvanize the distributed web community.
In the future, we can imagine a world where no single website controls all of your data, but rather patrons can participate in a decentralized, distributed network. You may be interested to try Bookwyrm, an open-source decentralized project by Mouse, former engineer on the Internet Archive’s Archive-It team.
Pingback: Report: “Goodreads Plans to Retire API Access, Disables Existing API Keys” | LJ infoDOCKET
Pingback: Goodreads Is Retiring Its Current API, and Book-Loving Developers Aren’t Happy - Cosmos Magazine