
by Tabish Shaikh & Mek
OpenLibrary.org,the world’s best-kept library secret: Let’s make it easier for book lovers to discover and get started with Open Library.
Hi, my name is Tabish Shaikh and this summer I participated in the Google Summer of Code program with Open Library to develop improvements which will help book lovers discover and use OpenLibrary.org.
My Journey into Open Source
When I got to college, I could tell classes would not be enough to help me get the hands on experience I would need to gain confidence in my programming abilities. I heard from friends and professors within my university that open source projects presented a great opportunity to work with established engineers in the field to gain hands-on experience.
In the past, I tried contributing to a few well known open source projects, like Wikipedia. I selected Wikipedia because the community is large, active, and well established, there’s a lot of documentation, and the project is in a programming language I know well.
I quickly became overwhelmed. Wikipedia may be well established, but a project of that size felt difficult to navigate without a mentor to guide me. I was able to successfully set up my environment, but then I had trouble finding an appropriate first issue to work on and hit a dead end as I tried to familiarize myself with the code. I found myself wishing for a chance to work more closely with the community.
One evening in March of 2018, I was searching for a free algorithms book on Google and discovered Open Library. I had trouble finding the exact book I was looking for, but I could tell Open Library was an important library resource for accessing free books online and I noted their dated design as a big opportunity for improvement. So I bookmarked the page in my browser and was surprised to discover a “Help Us” button. I clicked the button and landed on a github issue which mentions their community calls. This gave me confidence there was a community which could help me get started and answer my questions, so I decided to give it a shot.
The community calls gave me a guided path for positively improving the experience of patrons using the service. During the community calls, members present what they’ve completed, what they’re working on, and what they may be stuck with. In reality, this is a way to be seen for your achievements, update others, and receive help. Having this type of structure helped me discover which appropriate opportunities exist, how to approach and plan to solve the problem.
This experience was really special to me because it was the first time I had been part of an international community and all of the members were aligned toward a common goal of universal access to knowledge.
In the first few months of volunteering I redesigned the website footer and made several pull requests. I also noticed Salman was participating in Google Summer of Code (GSoC) in 2018. I applied to work with Open Library for GSoC in 2019 and was disappointed to learn the Internet Archive didn’t have enough slots for Open Library to participate. Fortunately, I worked with Mek, Open Library’s program lead, who recognized my contributions and arranged an “Internet Archive Summer of Code” (IASoC) internship program where we accomplished a major victory of releasing the sponsorship program which empowers the community to make meaningful, diverse books more available to borrow. You can read the blog post here which was picked up by BoingBoing and Gizmodo.
Noticing a Problem
During my years volunteering, we recognized several indicators that Open Library could be better serving its mission by distributing to a larger audience. Open Library, which has millions of free books to borrow, has an international alexa rank of #11,079, compared to Goodreads which is a top #300 website without having books to borrow. The data also showed many patrons would drop off at the registration page because it didn’t offer immediate field validation and the fields would be cleared upon submit if, e.g. an email was already registered. The book pages, our most frequently viewed pages, were also very slow to load, causing patrons to drop-off. Also the experience of the book pages was confusing because there were separate views for Works and Editions. Because of all these factors, only around 6% of the Internet Archive’s books were checked out, meaning 94% of the catalog remained underutilized.
I applied to GSoC 2020 with a plan, “Adoption By Book Lovers” to resolve some of these key issues, help more people like myself discover and derive value from the Open Library, and hopefully improve their first experience in the process.
Placing our bets
In the service of helping more patrons discover Open Library, increasing our utilization and engagement, and decreasing confusion and bad experiences, we made 5 key bets:
- Improving Sign Up
- Book Page Redesign
- Shareable Profiles & Public Reading Log
- Imports & Exports
- Twitter Bot
There’s a common saying, “the first impression is the last impression”. This has certainly been true for many patrons attempting to sign up for an Open Library account. The easiest, surest way to help more patrons derive value from the Open Library platform is by Improving Sign Up; reducing the friction and early negative first impressions during account creation.
Open Library’s mission for 2019 was “Reducing bad experiences, confusion, & dead-ends”. By combining our Works and Editions pages into a single more performant Book Page Redesign we believed we’d reduce the confusion of users searching for their favourite books and in turn, also increase distribution. The DoubleClick study by Google shows that 53% of patrons drop off if page load is exceeds 3 seconds and this carries significant SEO penalties. While redesigning our Book Page, a key consideration was page-load performance because we knew this would increase our rank in search engine results and increase retention through the lending and registration funnels.
Finally, by betting on social features, like shareable profiles and public-by-default reading logs, the ability to import books from Goodreads, and a twitter @borrowbot to help patrons discover which books are available to read and borrow on Open Library, we felt confident we could increase the number of patrons that may discover and adopt OpenLibrary.org.
Improving Signup
In 2018, we coincidentally, hit a regression #1431 to our account creation page which presented itself as a server error for patrons trying to register a new account when their username or email was already taken.
Because of this bug, our daily registered users dropped from ~2300 to ~1700 (-500). Through this, we discovered that nearly 1/5 of patrons (i.e. 500 a day) who attempted registration would hit some validation issue when creating their account (e.g. email or username invalid or taken, recaptcha broken). Even after solving the #1431 regression, we hypothesized that many of these 500 patrons were hitting error-cases which refreshed the page and cleared their form inputs, causing patrons to bounce. An easy solution was adding real-time validation to ensure emails, usernames, passwords, and recaptcha are valid before submitting the form.
In order to implement real time validation, we planned Epic #1433 which included two pieces:
- #2053 – update backend API endpoints
- #2055 – Add real-time field validation for email, username, password to show errors before submission.
While we do not have great analytics on how conversion increased, we do know from our support channels that these changes have anecdotally resulted in a significant decrease in support emails around patron signup.
- Try it out 👉
- Issue:
- Pull Request:
Book Page Redesign
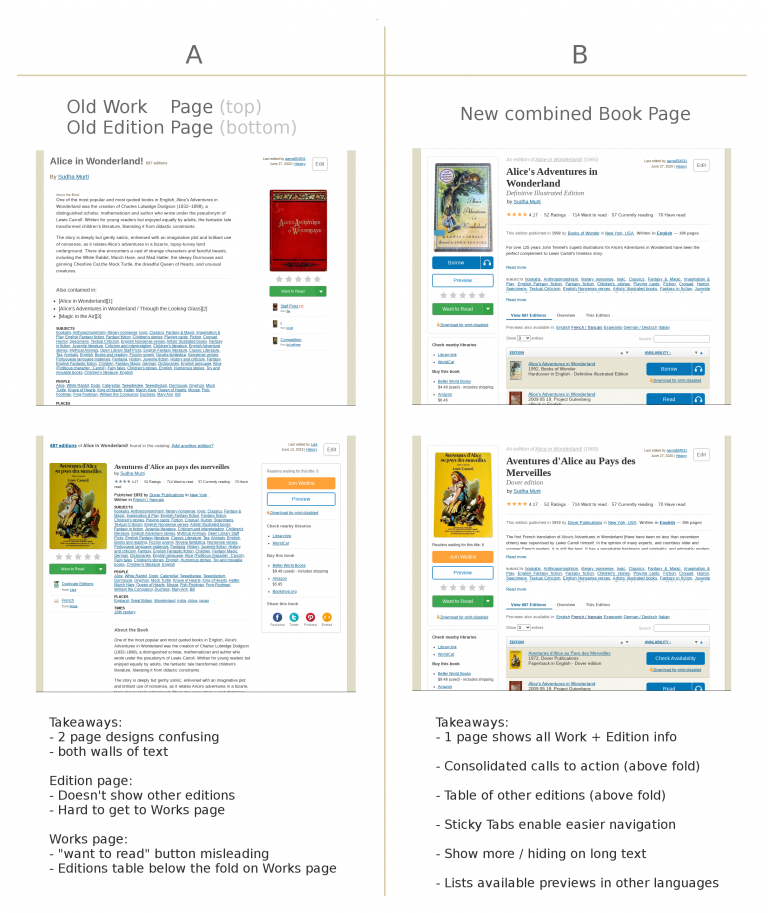
User interviews and surveys have taught us that most patrons who visit Open Library are trying to find a “Book”. Many patrons report that the terms Work and Edition may confuse their experience. This confusion is increased because a user can unpredictably be dropped into either a Work page or an Edition page which have different designs.
Our goal in redesigning the books page was to increase clarity of the experience and improve page loading times. To improve clarity and simplify the experience, we merged the work and edition pages to a single book page where patrons may find all the information about a work and learn about the availability of various editions without having to navigate multiple pages.
When redesigning the Book Page, we made the following changes:
- Editions table. We made the editions table front-and-center to enable readers to quickly switch between the different editions. We also feature editions by availability and language, and allow patrons to change how many results are shown at a time. We added a new search box to enable patrons to find relevant editions without reloading.
- Navigation tabs. We have bucketed the work’s information into an “Overview” tab and the current Edition’s information in the “This Edition” tab. The tab bar always sticks to the top of the page for easy access to different sections of the page.
- Expandable descriptions. In previous designs, long text descriptions made it difficult to see all important book information at a glance. There are now “Read more” links to expand and collapse long descriptions.
- Clearer buttons. All the favorite actions of readers such as borrowing, searching inside, adding books to one’s reading log, and book star ratings have been grouped together and moved right below the book cover. It’s hopefully more clear now that the “Want to Read”
- Load times. We know page speed is a priority for readers. The new Books Page should be significantly faster (Lazy Loading of Related Works Carousel).
Considerations. We tried to change as little as possible and were careful not to remove existing functionality:
- URLs: Developers and partners will be happy to hear that /works and /books urls and APIs will continue to work as expected without change. Both the work and edition pages will simply appear to use the same consistent design.
- Lists: While admittedly slightly less convenient, you can still add Works to Lists by clicking the “Use this Work” checkbox as shown below. By default, Lists will use Editions.
I had always worked in small teams with not a lot of stakeholders and no clash of ideas. The Books Page Redesign was one in which the issue was open for 3 years and it was being stalled due to clash of interests in how we should display our pages. Completing this issue was a major milestone in my GSoC program where I learned to cooperate and compromise on some aspects of our design so that all stakeholders were happy.
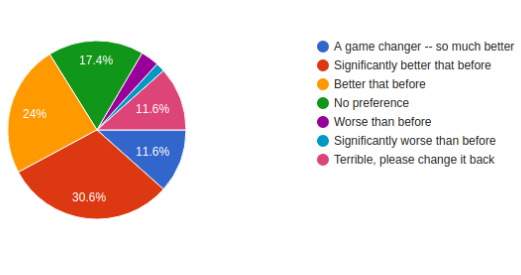
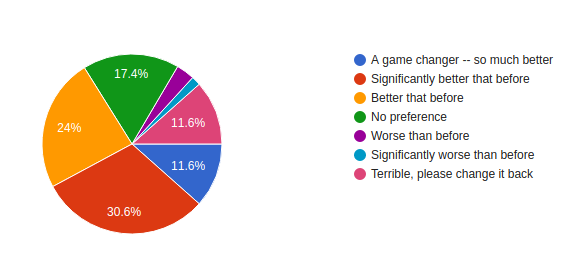
The feedback we received from our patrons was that ~65% patrons found the New Books Page a step forward, ~17% did not have any preference and ~22% found the change a step backward. Therefore we think our hypothesis was correct and this feature would improve user experience and reduce user confusion.
Read more about the Book Page Redesign: https://blog.openlibrary.org/2020/07/08/re-thinking-open-librarys-book-pages/
- Try it out 👉
- Issues:
- Pull Request:
Additional Book Page improvements
After completing the Book Page redesign, we made two major improvements to help our Librarian community and to improve performance and load times: a better book /edit experience and Lazy Loading of expensive book page components (e.g. related works carousels).
Book Page Editor. We redesigned the Books Page Editor to enable our librarians edit book metadata with ease.
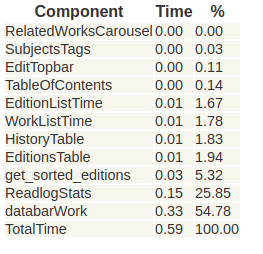
Lazy Loading of Related Carousels. To improve the page loading time we firstly created a list of components and their timings and noticed that the Related Works and Author Works took the most time to load thereby slowing down the page for up to 10%. Therefore our hypothesis was to lazy load related works carousel which would then enable our newly designed books pages to load faster.
The impact of this change was that now pages load up to 10% faster:
- Issues:
Shareable Profiles & Public Reading Logs
We noticed that very few patrons share their reading logs or even know they can be shared. However, we know patrons on Goodreads share their reading logs frequently. And also, lists on Open Library are shared all the time. Why is this?
In 2017, when Open Library announced the new Reading Log feature, it was set to be private by default. We expected many patrons would change their reading logs to be public, but because it wasn’t public by default and difficult to discover, patrons didn’t know the feature existed and had no reason to make it public.
In the spirit of being an open platform, we wanted patrons to have the opportunity to make their reading logs public to patrons with similar interests. As a result, we decided to make Reading Logs public by default for new accounts created after 2020-05, with the option for any patron to set their reading logs to private. Even after making this change, we noticed patrons trying to share their generic /account/books page, however this page always reflects the content of the currently logged in user.
By always redirecting /account/books to the publicly shareable /people/username url, we are able to move in a direction which enables patrons to freely share their reading logs and paves the way for other features like “following”, which we’re interested in exploring next year.
Enabling these change required:
- Modifying the user registration page (front-end) + https://github.com/internetarchive/openlibrary/blob/master/openlibrary/plugins/upstream/account.py#L203 (back-end) to support enabling this setting from the account creation form.
- For enabling redirects – Adding a redirect from /account/books page to /people/username and dealing with conditions for public/private reading log.
This change simplified how users share their reading log and profile pages publicly paving a path for more social additions to Open Library.
- Try it out 👉
- Issues:
- Pull Requests:
Imports & Exports
Goodreads provides a way to download/export a list of books from one’s bookshelves. This feature would allow a user to take an exported dump of their reading log from Goodreads and then add each of these books to their Open Library account.
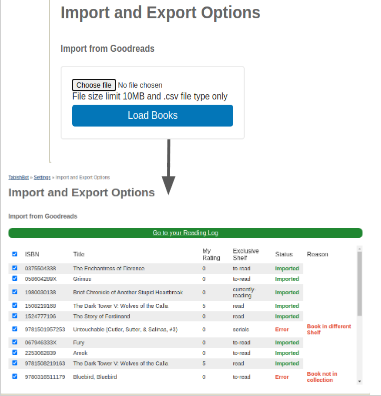
The export options enables patrons to download a list of Open Library book identifiers from their reading log.
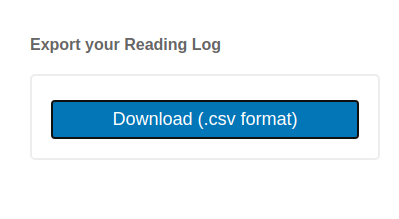
- Try it out 👉
- Issue:
- Pull Request:
Twitter Bot
Our objective for this task was how do we reach more patrons/readers and help them discover more books on openlibrary.org? According to the hashtag analytics audit done on tweetbinder.com on hashtags #books #amazon using the free version the analytics show that in a 7 day period the number of original tweets(excluding retweets) was approx. 140 with a number impact of 11M. Therefore this is a great opportunity for making our bookshelves discoverable.
Whenever a user tweets out a book with the amazon link/ an ISBN, the twitter @borrowbot would retweet the book with the link from Open Library if it is available. The book will be tweeted only once.
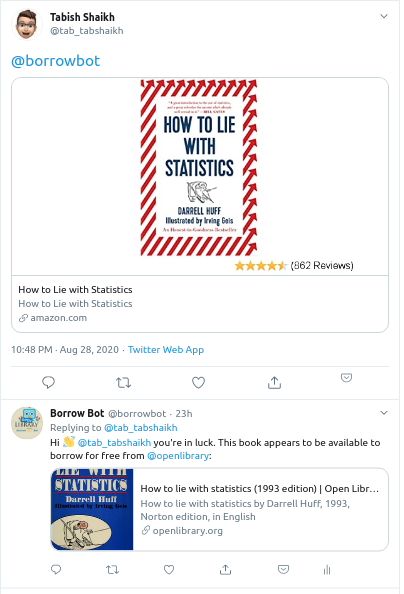
- Try it out 👉
- tweet @borrowbot ISBN/ Amazon link
- Related Issue:
- Code:
Impact
- In no small part because of the bets we made, our international Alexa rank improved by 10% from #11,079 to #9,893.
- Our Book Page load times improved on average by ~10%.
- 2 out of 3 of our patrons approved of our Book Page redesign, with 11% celebrating it as game changer.
- More than 5,000 books have already been imported through the Goodreads import tool
- Support team reports significant decrease in account creation support emails
What I learned
I always looked for ways to improve my work and have always loved constructive feedback from my mentor Mek who helped me learn how to estimate time for tasks, effectively identify stakeholders and include them in the process (reaching consensus on decisions was a lot harder than I anticipated), and how to communicate problems and achievements in a way which everyone may understand. Also, writing takes a long time and it’s easy to want to code until the deadline. As our founder Brewster Kahle says, “work backwards from the blog post”.
I also had the privilege of applying what I’ve learned to be a mentor for both Sachin Naik (#3627 #3622 ) and Fatima (#3454) within our community and helping them submit some of their first pull requests for Open Library