
By: Nolan Windham & Mek
I’m Nolan Windham, an incoming freshman at Claremont McKenna College. This summer I participated in my first Google Summer of Code with the Internet Archive. I’ll be sharing the achievements I’ve made with the Open Book Genome Project sequencer, an open source tool which extracts structured data from the contents of the Internet Archive’s massive digitized book collection.
The purpose of the Open Book Genome Project to create “A Literary Fingerprint for Every Book” using the Internet Archive’s 5 million book digital library. A book’s fingerprint currently consists of 1gram (single word) and 2gram (two word) term frequency, Flesch–Kincaid readability level, referenced URLs, and ISBNs found within the book.
Try it out!
Anyone can try running the OBGP Sequencer on an Internet Archive open access book using the new OBGP Sequencer™ Google Colab Notebook. This interactive notebook runs directly within the browser, no installation required. If you have any questions, please email us.
If you are interested in seeing the source code or contributing check out the GitHub. If this project sounds fascinating to you and you’d like to learn more or keep the project going, please talk to us!
How I got involved
I first found the Internet Archive in high school where I used the Wayback Machine for research and Open Library for borrowing books. As I found out more about the Archive’s services and history, I became more and more interested in its operation and its mission: to provide “Universal Access to All Knowledge”. Once I heard this mission, I was hooked and knew I wanted to help. During a school trip to San Francisco, I joined one the Archive’s Friday physical tours (which I highly recommend). The tour guide was impressed with the amount of information this high-schooler knew about the Archive’s operation and took me aside after the tour and showed me Book Reader’s read aloud feature and answered some questions about the book derive process. The tour guide then invited me to join the Open Library community chat where developers, librarians, and patrons discuss all things Open Library. This tour guide turns out to be Mek, my project mentor, Open Library Program Lead, and Citizen of The World.
I started attending the weekly Open Library community calls to learn more about how Open Library works, the issues the project faced, and how I could help. After months of showing up to calls, learning about open source, and developing my programming skills, Mek showed me an interesting prototype called the Open Book Genome Project.
Background
The Open Book Genome Project (OBGP) is a public good, community-run effort whose mission is to produce, “open standards, data, and services to enable deeper, faster and more holistic understanding of a book’s unique characteristics.” It was based on a previous effort led by a group in 2003 called the Book Genome Project, to “identify, track, measure, and study the multitude of features that make up a book.” Think of it as Pandora’s Music Genome Project but for books. Apple acquired and discontinued the Book Genome Project in 2014, leaving a gap in the book ecosystem which the Open Book Genome Project community now hopes to help fill for the public benefit.
The Open Book Genome Project is one of many efforts facilitated by members of the Internet Archive’s Open Library community. Their flagship service, OpenLibrary.org is a non-profit, open-source, public online library catalog founded by the late Aaron Swartz, which allows book lovers around the world to access millions of the Internet Archive’s digital books using Controlled Digital Lending (CDL). Open Library hopes the Open Book Genome Project may help patrons discover and learn more about books in some of the ways the Book Genome Project originally aimed to accomplish.
You can learn more about the history of the Open Book Genome Project in an upcoming blog post. You can also learn more about the other half of the Open Book Genome Project called Community Reviews in this blog post.
Here’s where we started
When I began working on the OBGP Sequencer, the general code structure and a few features were in place. The sequencer could extract a book’s N-gram term frequency and identify its copyright page number. There were many features in the product development pipeline, but no one dedicated to implement them. Over the past few months, I led development to add and improve the Sequencer’s functionality, created an automated pipeline to process books in volume, and deployed this pipeline to production on the Archive’s corpus of books.
One challenging part of the development process was getting ISBN extraction working accurately. The ISBN extractor works by first finding what it thinks is the book’s copyright page and then checking for a valid ISBN checksum in every number sequence. Although this approach works, there are often a lot of strange edge cases usually having to do with poor optical character recognition. To address this, I was manually spot checking books for ISBN’s that were detected and missed, and investigating why to iteratively improve the extraction process. Here is a screenshot of my process.
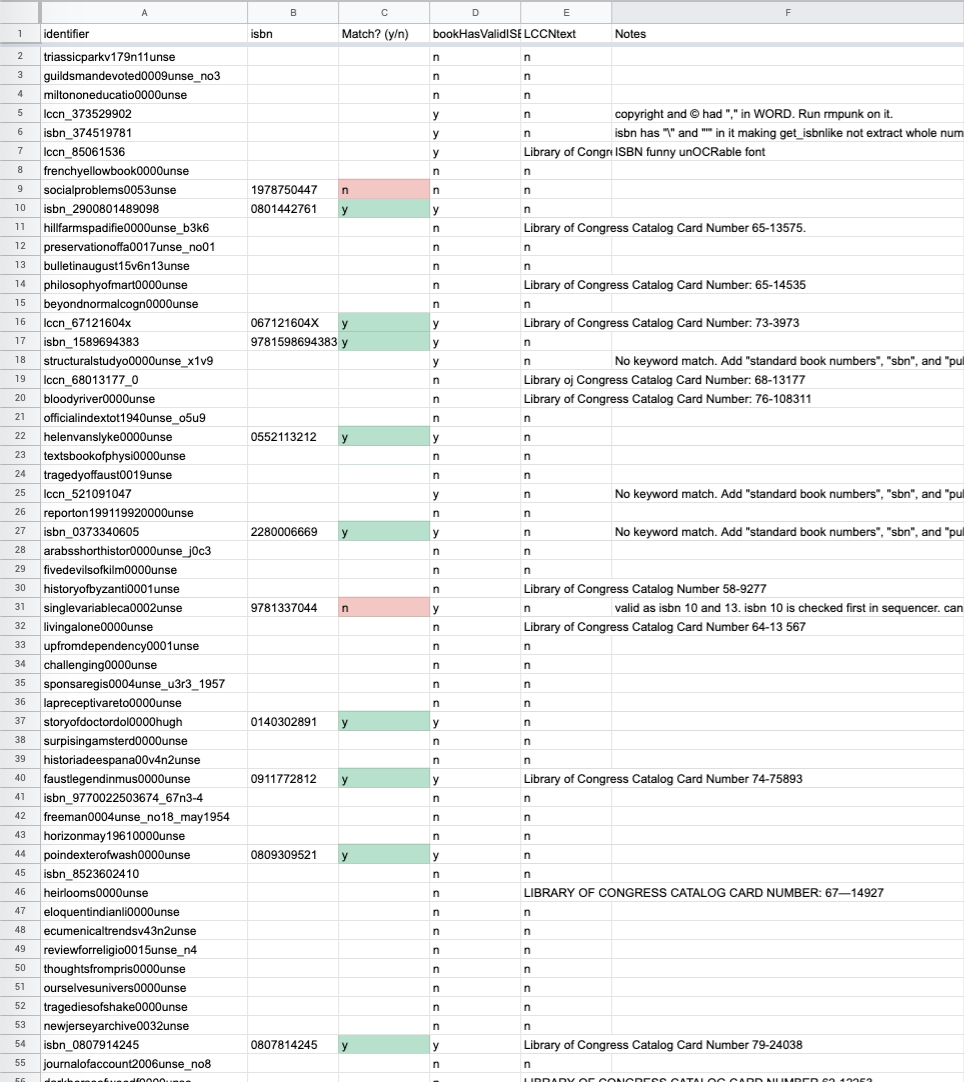
Another challenge later on in the development process was getting books processed at scale. With a collection as large as the Archive’s, parallelization of processing is an essential component of scaling the sequencer up. I taught myself to use some of Python’s parallelization libraries and implemented them. Another challenge was getting parallelization working with the database. I addressed this by making the file system and directory layout database because modern file systems are built to work well with parallel I/O.
Here’s what we were able to accomplish with OBGP
- Make more books borrowable to patrons
- Add reading levels for thousands of books
- Identify & save urls found within books
- Produce a large public dataset of book insights
Making Books Lendable
Nearly 200,000 books digitized by the Internet Archive were missing key metadata like ISBN. The ISBN is used to look up all sorts of book information which is helpful for determining whether a book is eligible for the Internet Archive’s lending program. The absence of this key information was thus preventing tens of thousands of eligible books from.
As of writing, the Open Book Genome Project sequencer has extracted ISBN’s for 25,705 books that were previously unknown. 12,700 of those are newly lendable to patrons. Take a look at them here!
These books now have identifying information and are linked to Open Library Records. Open Library pages that had no books available now have borrowable books. Here is a before and after screenshot.
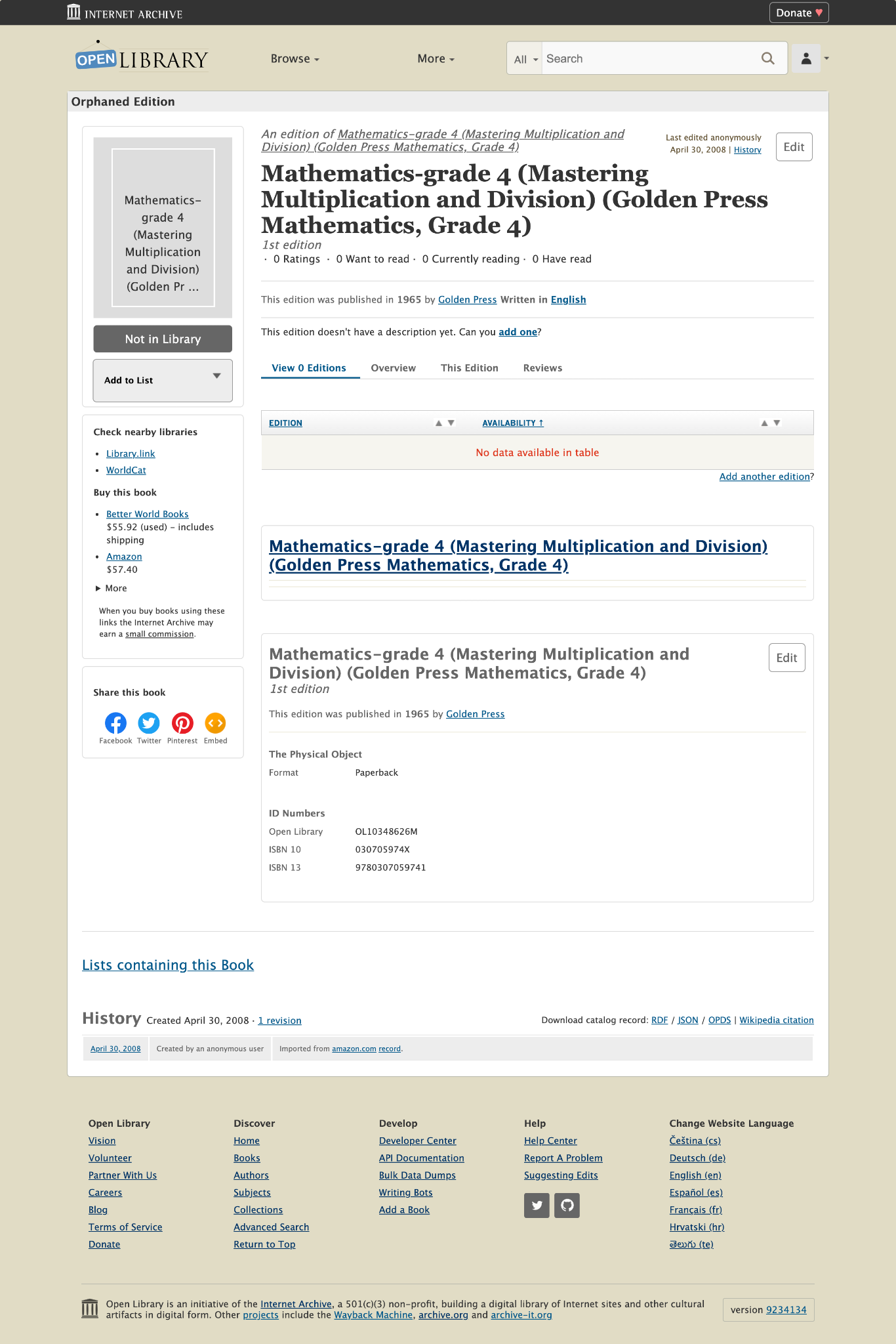
Before
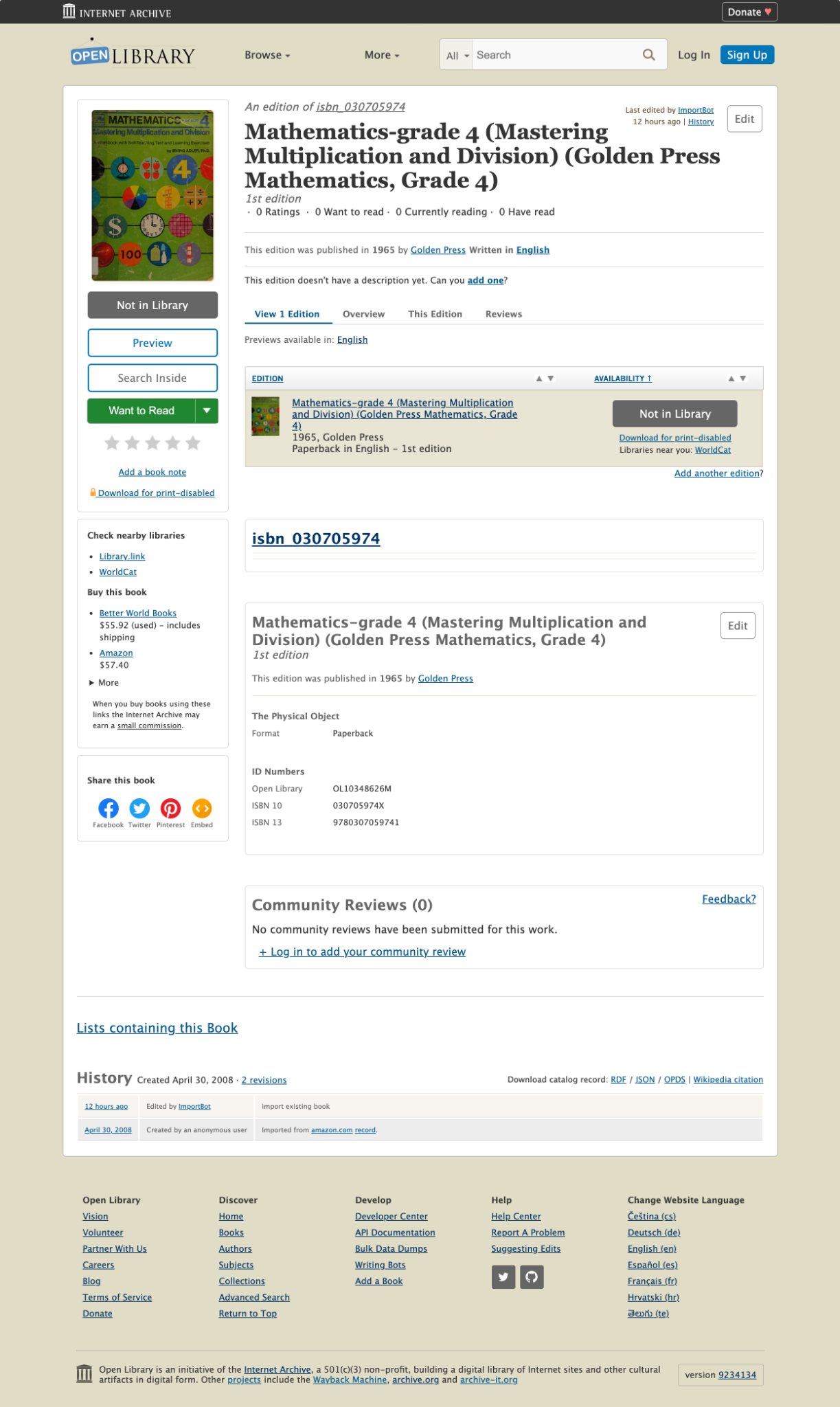
After
Adding reading levels
It’s often difficult to identify age-appropriate materials for students and children. By adding reading level information to Internet Archive’s book catalog, we’re able to make age-appropriate books more accessible.
The Sequencer now performs a Flesch–Kincaid readability test on each book on which it is run. This resulting Flesch–Kincaid grade level estimation allows students, parents, and teachers to filter their searches for books which include appropriate reading levels.
Preserving URLs
Open Library is aware of more than 1M books containing urls. These mentions by credible authors are like a vote of confidence of their relevance and usefulness. These websites are at risk of link rot and without preservation could be lost forever. But given the average webpage only lasts 100 days, it’s only a matter of time before millions of URLs found in millions of books will be preserved for future generations.
As of writing, URLs have been successfully extracted from more than 13,000 books, which will soon be preserved on the Wayback Machine. Many of the high quality references found in published books have not yet been preserved and now will be.
Producing public datasets
The original goal of OBGP was to produce an open, public data set of book insights capable of powering the open web. As of writing, the Open Book Genome Project sequencer has uploaded genomes for 180,642 books. For every book sequenced, a book genome is made publicly accessible that provides insights into the book without needing to borrow it. The goal of this is to increase the quantity and quality of publicly available descriptive information available for every book, so that readers and researchers can make better informed decisions and glean deeper insights about books. This supports readers, researchers, book sellers, libraries, and beyond.
Personal Development
I really enjoyed participating in GSoC with the Internet Archive because I was able to build programming foundations and gain industry experience that will prove invaluable in my future. I developed my project management skills, became more comfortable programming in Python and using new software libraries, and advanced my knowledge of dev-ops tools like Docker.
The future of the project
If you may be interested in contributing or learning more about the Open Book Genome Project sequencer, please send us an email.
Although we made a lot of progress with this projects development, there is still a lot more to be done. Here is a quick list of possible future features to get you excited about the possibilities of this project:
- Make URL’s clickable
- Identifying meaningful semantic elements in books, like Entities and Citations
- increase the number of previewed pages & volume of previewable content.
- Clickable Chapters in Table of Contents
- Library of Congress Catalog Number extraction
- Copyright information (Publisher, copyright date) extraction
- Book and chapter Summarization and Topic Classification