Open Library is powered by a global community of volunteers, a small team of staff, and several extraordinary, handpicked volunteer fellows who are picked to work alongside staff to tackle ambitious, high impact projects. This week, we’re featuring the work of Engineering Fellow Ben Deitch, who has made a dramatic impact on the Open Library initiative since 2024.
Ben’s numerous engineering contributions have strengthened Open Library’s experience for hundreds of thousands of patrons. With the mentorship of senior staff engineer Drini Cami, Ben wrote code that enables patrons to:
Find exact book editions from their Reading Logs
Search which books were read within any given year
Discover interesting books based on a sophisticated reddit-style trending algorithm
Mark books as “Want to Read” from author pages
Prior to Ben’s work, reading logs would show works instead of editions. Ben added the ability to view editions on a reading log. This enables users to track the precise editions of books they have read. The log will also show the right cover for each edition.
Ben also implemented a basic “fuzzy search” for the Solr Search engine, making the overall search system much more tolerant of spelling errors and bringing it closer to modern standards for search engines so that patrons don’t hit dead ends.
In another project, Ben coded in a new, image-based preview for user created book lists, which appears on users’ My Books pages. This feature also enables patrons to see the first few books in a list at a glance.
Historically, search results and book pages have featured a “Want to Read” button that patrons can click to keep track of books of interest. Ben extended book results so patrons can also click “Want to Read” from the author’s page.
In the past, when carousels were rendered for the homepage, facets were included – like language – that were accidentally being dropped when additional results were loaded. Ben fixed this issue so books results were relevant even when loading multiple pages.
Ben’s work can be found across the Open Library – from the search page, to the home page, the author’s page, and the my books page. We are grateful to Ben and couldn’t be more proud of his contributions to our Open Library.
This summer, continuing a years-long tradition, Open Library and the Internet Archive took part in Google Summer of Code (GSoC), a Google initiative focused on bringing new contributors into open source software development. This year, I was lucky enough to mentor Sandy, a long-time Open Library volunteer, on an exciting project to increase the accessibility of our books with real-time translations. We have invited Sandy to speak about her experience here as we reach the culmination of the GSoC period. It was a pleasure getting to work on this exciting project with you Sandy! – Drini
My name is Sandy Chu and I am a 2025 Google Summer of Code (GSoC) candidate who had the opportunity to work with the amazing Internet Archive engineering team. Prior to participating in the GSoC program, I had contributed as a volunteer software engineer for the Open Library open source repo. As someone who grew up using local libraries as a place to supplement my education and read books that my school could not afford, I was drawn to the Open Library’s mission to empower book lovers and provide a free, valuable resource to all. You can view my initial proposal here.
Coming soon in September, the Open Library will be able to better serve its global audience to access books that were previously not available due to a lack of localization. With the help of open source projects such as the Mozilla Firefox Translation Models and Bergamot Translator library, a new BookReader plugin will have the ability to leverage a user’s browser and hardware resources to toggle translations from a book’s original language to a translation in their language. Additionally, the translated text will also work with the ReadAloud feature to read books in the translated language.
The “Real-Time In-Browser Book Translation w/ Read Aloud (TTS)” project closely aligns with the Open Library’s 2025 goal of providing more with less. Although the Internet Archive hosts and provides its patrons with hundreds of thousands of publicly available works, patrons are limited to a subset of works that were published in their native language. Due to the unique image based implementation of the BookReader application, default browser translator options are not viable for many readers, so this project presents an opportunity to make a big impact for international audiences.
Currently in internal beta, the translation plugin allows patrons to quickly initiate a local translator on-their device and translate the book’s text in just a few seconds per page. With nine distinct languages available for translation from English (and potentially over 40 as we update to Mozilla’s latest models), this project will make countless works more accessible for patrons.
The primary goals of this project were:
Translating a book’s original text content to the patron’s desired language with minimal delay or disruption
Creating a visually seamless experience to maintain the immersive experience of reading a book without having to go back and forth between a translator and the book
Redirecting the existing TTS plugin to use the translated text when the BookReader is in translation mode
Language
Total Readable Books on OL
% of All Readable / Borrowable Books (out of 4,526,060)
Native Speakers Globally
(in millions)
English
3,034,445
67.04%
390
French
332,052
7.33%
74
German
180,341
3.98%
76
Spanish
120,516
2.66%
484
Chinese
90,531
2.00%
1,158
Korean
5,384
0.11%
81
Arabic
2,415
.000533%
142
Retrieved from Wikipedia, which references Ethnologue as its source. Chinese and Arabic dialects are grouped together since they both have a unified written system.
Translations
At the center of the translation plugin are the Neural Machine Translation (NMTs) models provided by Mozilla Foundation’s Firefox Translation Models project. These files contain the lexical and vocabulary conversions from the original language to the target language; these compact models are essential to the real-time, browser-side aspect of this project. Since we are currently using an older subset of models, the translation feature is still considered in the “alpha” stage of maturity and accuracy.
When the translation plugin is enabled by the user, the language registry and model files are fetched from a server within the Internet Archive. After the models have successfully loaded into the user’s browser, we are able to use the Bergamot Translator project scripts to create a dedicated Web Worker, which is initialized to handle the translation tasks in a separate background thread. The Web Worker immediately retrieves the text content within the text selection layer for the currently visible page(s) for translation. Pages that have been rendered but not visible in the BookReader are given a lower priority and translated after the queue of visible content is completed.
An unmodified page in the BookReader.
The translation plugin script feeds the text within the text selection layer into the model for processing and prepares the stage for the translated output by covering the original image and text selection layer with a beige background. [Pull Request #1410]
The translation plugin has initialized and is providing the original text to the language model.
Once the translation is completed by the dedicated Web Worker, the output is then used as the text content for its respective paragraph chunk and appears as if the work is actually written in the target translation language.
The translation has completed and is now on the page!
Images with captions are also carefully handled so that the translated text box occupies nearly the same space as the text selection layer itself.
Each translated paragraph is stored in a cache with a unique key to prevent the browser from re-translating recently viewed content [Pull Request #1410/commit]. To prevent readers from having to wait for the translation when “flipping” to the previous/next page, the translation plugin targets the visible pages on the screen then works to complete the translations for the non-visible but loaded pages. If a user decides to flip far from their current page in the work, the translation plugin will detect the newly rendered page and translate / populate the translated text layer while adjusting to a new page on the fly.
The text selection layer has been adjusted to appear in red.The translation layer occupies roughly the same height and width by copying the text selection layer’s properties.
Fine-tuning the visual presentation and behind-the-scenes functionality of the plugin were the main challenges for this portion of the project. Ensuring that the translations for each text chunk were done without depending on a previous chunk was an essential behavior we identified in the early stages of the project. Both asynchronous and synchronous behavior is implemented within the code to ensure that users do not have to wait for longer than needed for paragraphs to complete their translations. The translation plugin utilizes event listeners within the BookReader to detect when a newly rendered text layer is created, which then triggers a translation call to the text content from the upcoming page.
Styling the translated text layer also proved to be difficult. Although it is possible to reuse the style properties on the existing (and invisible) selection text layer, additional adjustments were needed to ensure that the visible translation text would not overlap or go beyond the bounds of the original paragraph. In the early phases of the translation plugin development, there were many instances of text chunks exceeding the boundaries set for the translation layer, which resulted in scrollbars appearing within paragraph elements or not aligning properly with the text on the page.
A screen capture from an earlier version of the translate plugin. A scrollbar can be seen in the 2nd paragraph element of the left page.
Another styling issue that caught us off guard was a pre-existing bug that was only visible in the Chrome browser. Since Drini and I were both using Firefox as our default browser, we later learned during a demo that there was an element scaling issue that was immediately visible when the translation plugin was activated. [Pull Request #1421/commit]
ReadAloud
The next major piece of this project was to connect the translation plugin to the ReadAloud feature and allow users to hear the translated text read aloud.
The normal flow of the TTS (Text-to-Speech) plugin calls a server-side API to retrieve chunks of text and bounding rectangles based on the page and paragraph index. However, since we have the translated text available within the BookReader locally, the extra network calls to the server were dropped in favor of feeding the translated text lines into the TTS engine directly. Tweaking the pre-existing functionality of the TTS plugin to interact with the content generated by the translate plugin required a substantial amount of investigation to figure out where the adjustments needed to be made for the translation plugin to gracefully take over.
When the TTS plugin is activated, it checks whether or not the translation plugin is enabled within the BookReader. If the translation plugin is active, the TTS plugin retrieves the translated text on the page to use as its text input for the voice engine.
Voice overs are also automatically adjusted as soon as the TTS begins to streamline the reading process. By checking the source language from the work’s metadata, the default voice of the TTS reader is automatically adjusted to the target language that was set within the translate plugin. The voice menu is also re-rendered to allow users to more easily switch between the source, target, or other languages for the TTS reader. [Pull Request #1430/commit]
The ReadAloud voices menu as it is seen without the translation plugin activated.Voices are categorized by the source language, target language, and other languages detected on a user’s system.
Visual parity between the original TTS and translated TTS was maintained as well by highlighting the entire translated paragraph section. Since network info containing the bounding rectangles for a text chunk were no longer available, I was able to use a paragraph element’s offset properties to highlight the text being actively read by the TTS reader [Pull Request #1431/commit].
The BookReader highlights chunks of text that are actively being dictated by the ReadAloud plugin.With a few tweaks, the ReadAloud highlighting feature can also be used to highlight the translated text being dictated by the voice over.
Although this stage of the project did not require as much new code, we encountered a relatively complex issue that would cause the TTS reader to not progress if the translation plugin is activated in a part of a book that contained one or more blank pages. The translation adjusted implementation of the TTS plugin would wait for a new page to be loaded and rendered within the browser but remain stuck on a page due to a synchronization issue. After two weeks of extensive investigation and testing, we were able to resolve the issue by utilizing an existing method that returns all pages that have been loaded but not rendered in the DOM yet [Pull Request #1431/commit] and consolidating the asynchronous translation call with Promise.all().
Next Steps
For now, this feature is currently scheduled to be released for internal testing before being released for full public use. While the majority of goals were completed within the project timespan, there are many additional improvements and expansions that are planned in the future as the BookReader’s translate plugin becomes more mature. The next major steps for this project involve expanding the number of available translation pairs by integrating the latest models from Mozilla’s Translation Model project, receiving and implementing feedback from a round of internal testing, and continually improving the UI of the plugin. Unit tests and offline testing environments are also part of the project’s future goals to help improve the troubleshooting process for developers.
Conclusion
I would like to express my thanks once again to my GSoC mentor Drini for his guidance. The first few weeks of this project felt especially daunting, but the patience and advice that I was given throughout this program helped me realize that this big intimidating project was easier to manage as a number of small tasks were taken step-by-step. I am very glad that I had the chance to be challenged in new ways while being able to leverage my existing JavaScript skills.
I am extremely grateful that I was able to participate in the GSoC program and to help contribute to a high-impact feature for both the Internet Archive and Open Library. Though my time as a GSoC contributor has officially ended, I intend to continue my work as a contributor with the Open Library team to expand on the functionality of this feature and help increase the availability of published works to a wider global community.
By Jordan Frederick AKA Tauriel063 (she/her), Canada
When deciding where to complete my internship for my Master’s in Library and Information Science (MLIS) degree, Open Library was an obvious choice. Not only have I been volunteering as an Open Librarian since September 2022, but I have also used the library myself. I wanted to work with people who already knew me, and to work with an organisation whose mission I strongly believe in. Thus, in January 2025, I started interning at Open Library with Lisa Seaberg and Mek Karpeles as my mentors.
At the time of writing this, I am three courses away from completing my MLIS through the University of Denver, online. During my time as both a student and Open Librarian, I gained an interest in both cataloguing and working with collections. I decided to incorporate both into my internship goals, along with learning a little about scripting. Mek and Lisa had plenty of ideas for tasks I could work on, such as creating patron support videos and importing reading levels into the Open Library catalogue, which ensured that I had a well-rounded experience (and also never ran out of things to do).
The first few weeks of my internship centered largely around building my collection, for which I chose the topic of Understanding Artificial Intelligence (AI). Unfortunately, I can’t take credit for how well-rounded the collection looks presently, as I quickly realised that my goal to learn some basic coding was more challenging than I expected. If you happen to scroll to the bottom and wonder why there are over 80 revisions to the collection, that was because I spent frustrated hours trying to get books to display using the correct codes and repeatedly failed. It is because of Mek’s and Jim Champ’s coding knowledge that the collection appears fairly robust, although I suggested many of the sections within the collection, such as “Artificial Intelligence: Ethics and Risks” and “History of Artificial Intelligence.” However, Mek has informed me that the AI collection will likely continue to receive attention by the community for the remainder of the year, as part of the project’s yearly goals. I hope to see it in much better shape by the time of our annual community celebration in October.
The Artificial Intelligence Collection.
I successfully completed several cataloguing tasks, including adding 25 AI books to the catalogue. With the help of Scott Barnes, an engineer at the Internet Archive, I made these books readable. I also separated 36 incorrectly merged Doctor Who books and merged duplicate author and book records. Another project involved addressing bad data, where hundreds of book records had been imported into the catalogue under the category “Non renseigné,” with minimal information provided for each. While I was able to fix the previously conflated Doctor Who records, there are still over 300 records listed as “Non renseigné.” As such, this part of the project will extend beyond the scope of my internship.
I am particularly proud of this patron support video I created as part of my internship. It shows patrons how to create bookmarks and notes within a book they are reading, as well as how to search certain phrases or words within a book. I also created a video on how to use the audiobook feature in Open Library. Projects like these, assigned by Lisa, tie directly into my MLIS education, allowing me to put my education in meeting patrons’ needs to use. Lisa also asked me to look at the Open Library’s various “Help” pages and identify any issues such as broken links, misleading/inaccurate information, and more. This task allowed me to practice working with library documentation and to advocate for patrons’ needs by examining the pages through the perspective of a patron rather than that of a librarian.
First patron support video created.
I created a survey to determine patrons’ needs and wants regarding the AI collection. This, in the library profession, is referred to as a “patron needs assessment,” which is vital when building a collection. While it would certainly have been fun for me to create a collection purely based on my own interests, there is little point in developing a collection of interest to only one person. Mek gently reminded me of this, so I thought about how an AI collection may benefit patrons. Some potential uses for the collection I came up with were:
Understanding AI
The History of AI as a field
Leveraging AI for work
Ethics of AI
In order to determine patron perspectives on the collection, I developed a Google Forms survey, which asks questions such as:
In your own words, tell us what types of books you would like to see in an AI collection (some examples might include scientific research, effects on the future, and understanding AI).
What are you likely to use an AI collection for (eg. academic research, understanding how to use it, light reading)?
Do you have any recommendations for the collection?
Once this survey is made live, those involved in the collection will have a better idea of how to meet patrons’ needs.
While I had initially assumed that the collection would allow me to build up some collection-building skills and would hopefully benefit patrons with an interest in AI, Mek has since informed me that this collection ties in with the library’s yearly goals. In particular, the AI collection aligns with the goal of having “at least 10 librarians creating or improving custom collection pages” [2025 Planning]. Additionally, I have spent some time bulk-tagging various books (well over 100 by now), which also ties into the team’s 2025 goals. It’s gratifying to know my efforts during my internship will have far-reaching effects.
As with the AI collection, using reading levels to enhance the K-12 collection is still a work in progress. As I worked with Mek over the course of the last nine weeks, I learned more about the JSON data format than I ever knew before (which was nothing at all), what “comment out” means when running a script, and a general idea of what a key and a value are in a dictionary. So far, we’ve been able to match more than 11,000 ISBNs from Mid-Columbia library’s catalogue to readable items in the Open Library, allowing us to import reading levels for these titles and add them to the search engine.
Finally, I was offered the chance to work on my leadership skills when both Mek and Lisa asked me to lead one of our Tuesday community calls. While initially caught off guard, I rose to the challenge and led the call successfully. I certainly fumbled a few times and had to be reminded about what order to call on people for their updates (and ironically forgot Lisa before a few community members reminded me to give her a chance to speak). But I appreciated the chance to take on a more active role in the call and may consider doing so again in the future.
The last nine weeks have been both intense and highly educational. I am grateful I was able to complete my internship through Open Library, as I believe strongly in the organisation’s mission, enjoy working with people within its community, and intend to continue contributing for as long as possible. I would like to thank Mek and Lisa for making this internship possible and offering their guidance, Jim Champ for his help in coding the AI collection, and Scott Barnes for taking time out of his evening and weekend to assist me with JSON scripting (and patiently answering questions).
I look forward to continuing contributing to Open Library. If you’re interested in an even more in-depth view of the work I did during my internship, feel free to read my final paper.
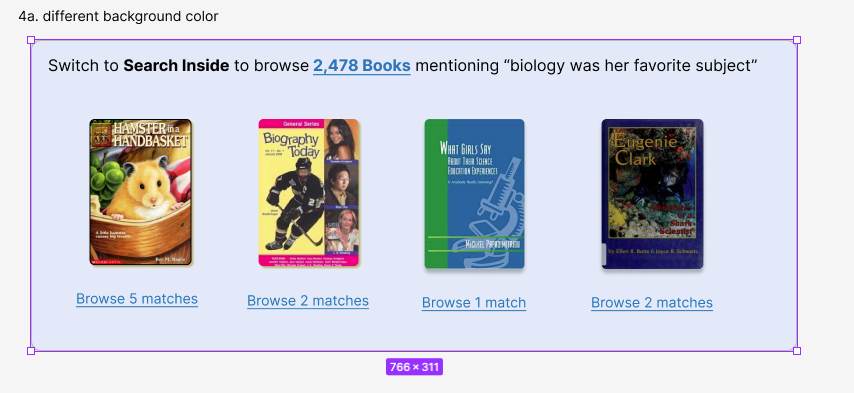
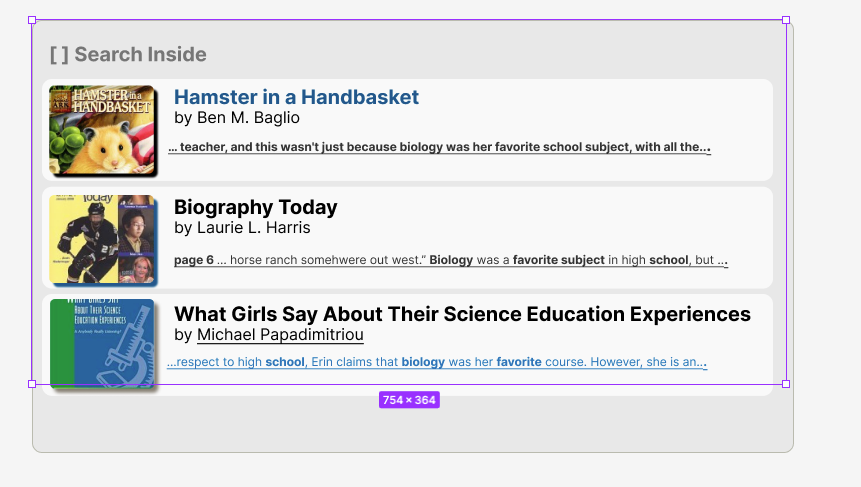
Thanks to the work of 2024 Design & Engineering Fellow Meredith White, the Open Library search page now suggests Search Inside results any time a search fails to find books matching by title or author.
Before:
After:
The planning and development of this feature were led by volunteer and 2024 Design & Engineering Fellow, Meredith White who did a fantastic job bringing the idea to fruition.
Meredith writes: Sooner or later, a patron will take a turn that deviates from what a system expects. When this happens, the system might show a patron a dead-end, something like: ‘0 results found’. A good UX though, will recognize the dead-end and present the patron with options to carry on their search. The search upgrade was built with this goal in mind: help patrons seamlessly course correct past disruptive dead-ends.
Many patrons have likely experienced a case where they’ve typed in a specific search term and been shown the dreaded, “0 results found” message. If the system doesn’t provide any next steps to the patron, like a “did you mean […]?” link, then this is a dead-end. When patrons are shown dead-ends, they have the full burden of figuring out what went wrong with their search and what to do next. Is the item the patron is searching for not in the system? Is the wrong search type selected (e.g. are they searching in titles rather than authors)? Is there a typo in their search query? Predicting a patron’s intent and how they veered off course can be challenging, as each case may require a different solution. In order to develop solutions that are grounded in user feedback, it’s important to talk with patrons
In the case of Open Library, interviewing learners and educators revealed many patrons were unaware that the platform has search inside capabilities.
“Several interviewees were unaware of Open Library’s [existing] full-text search, read aloud, or note-taking capabilities, yet expressed interest in these features.”
Several patrons were also unaware that there’s a way to switch search modes from the default “All” to e.g. “Authors” or “Subjects”. Furthermore, several patrons expected the search box to be type-agnostic.
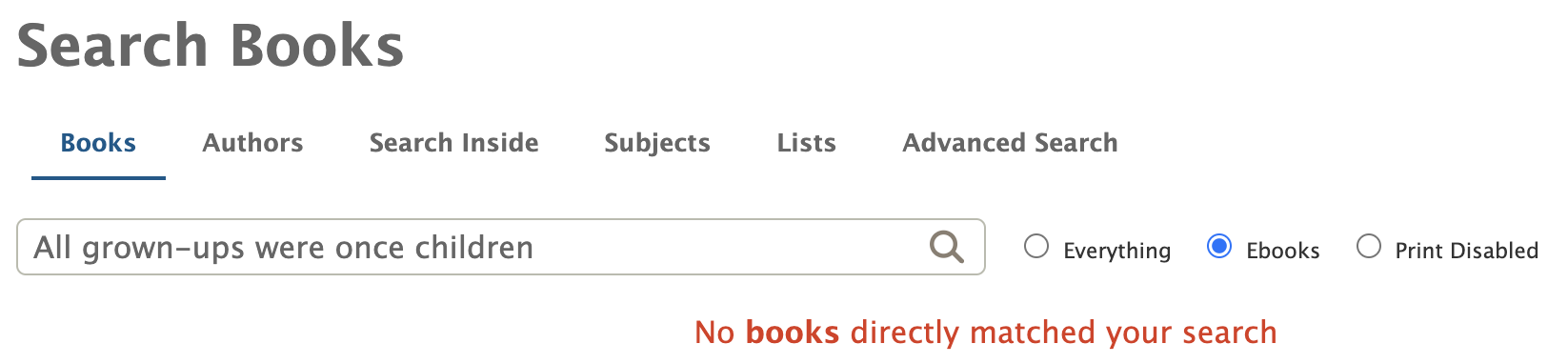
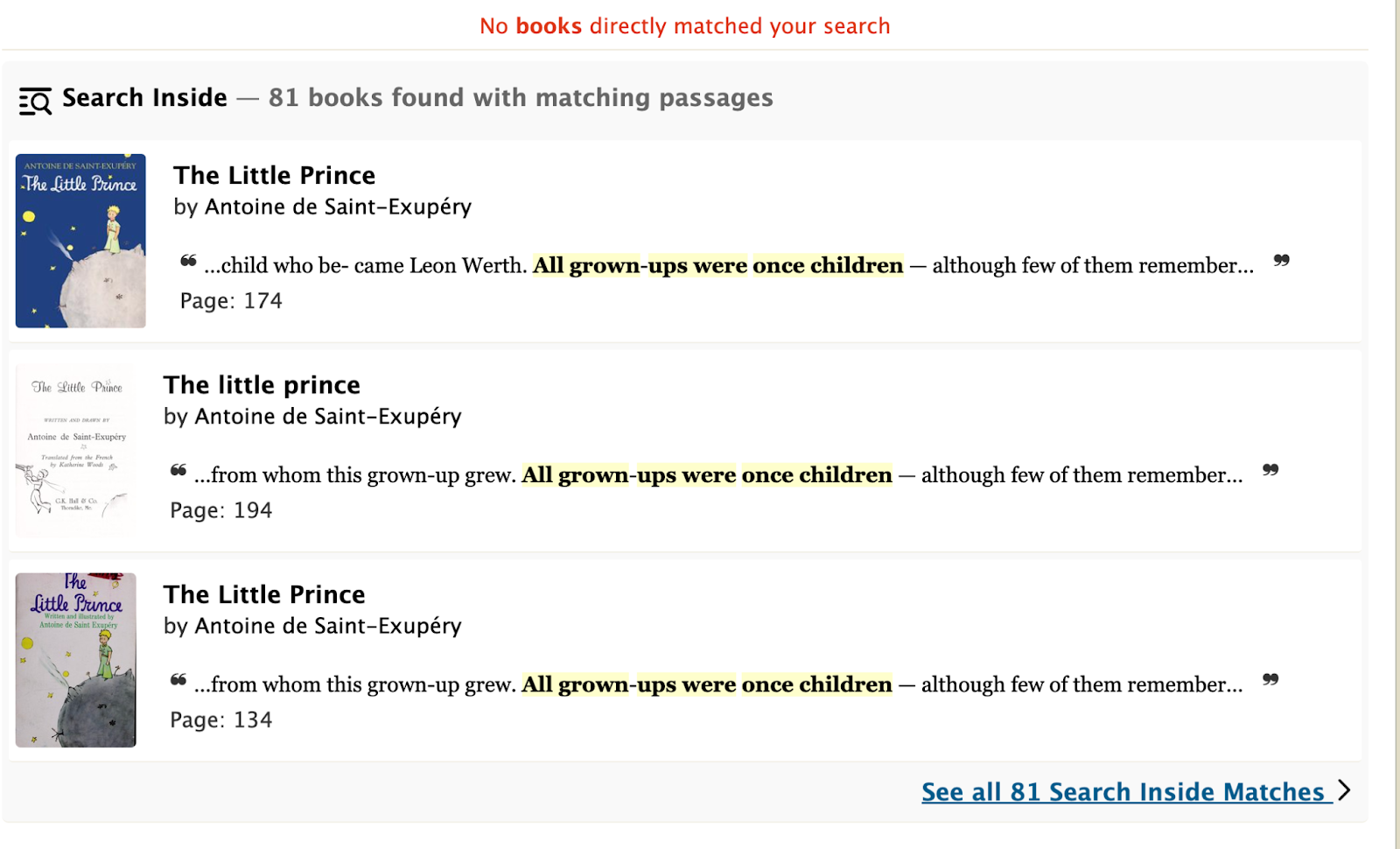
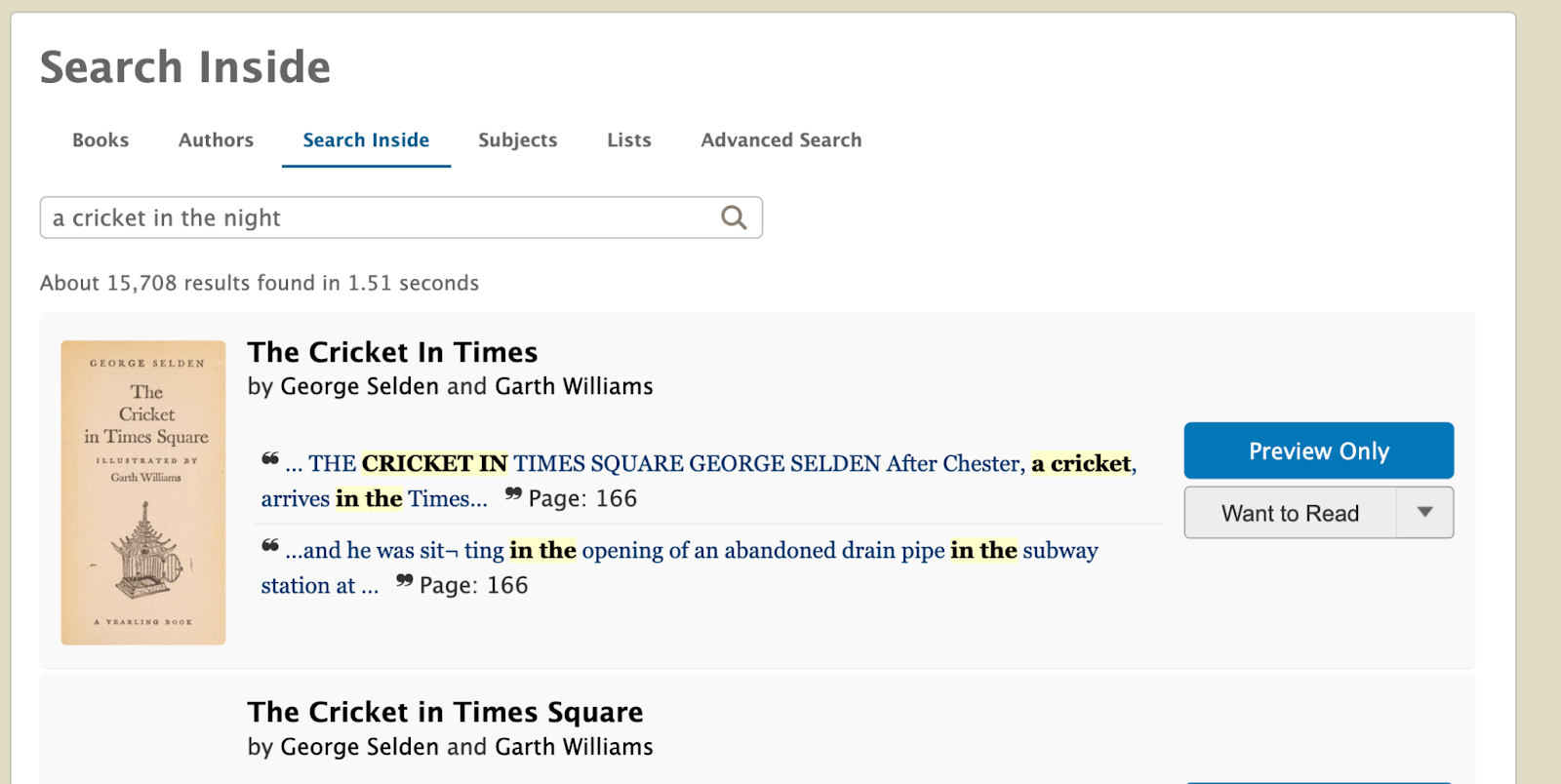
From our conversations with patrons and reviewing analytics, we learned many dead-end searches were the result of patrons trying to type search inside queries into the default search, which primarily considers titles and authors. What does this experience look like for a patron? An Open Library patron might type into the default book search box, a book quote such as: “All grown-ups were once children… but only a few of them remember it“. Unbeknownst to them, the system only searches for matching book titles and authors and, as it finds no matches, the patron’s search returns an anticlimactic ‘No results found’ message. In red. A dead-end.
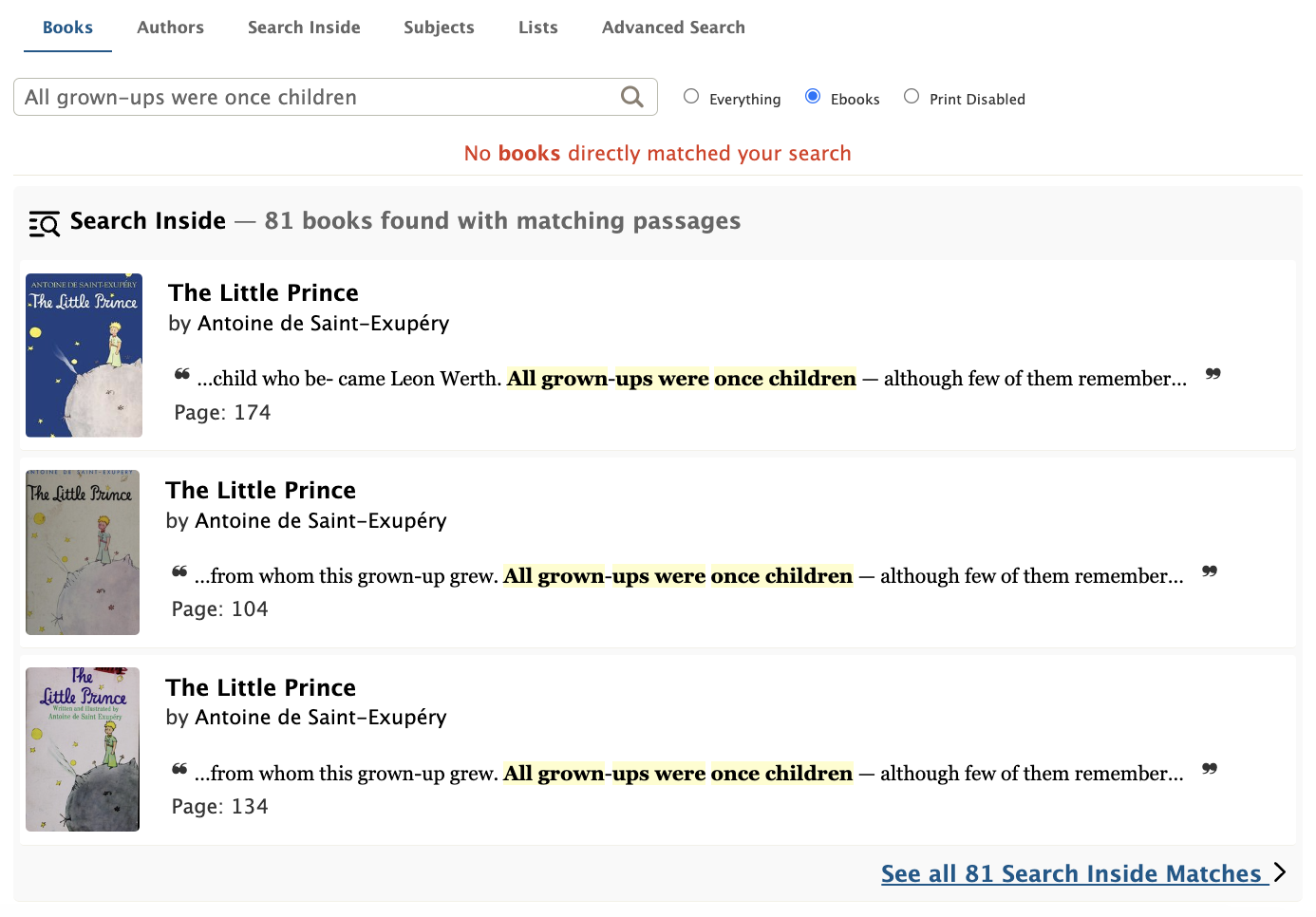
As a Comparative Literature major who spent a disproportionate amount of time of my undergrad flipping through book pages while muttering, “where oh where did I read that quote?”, I know I would’ve certainly benefitted from the Search Inside feature, had I known it existed. With a little brainstorming, we knew the default search experience could be improved to show more relevant results for dead-end queries. The idea that emerged is: display Search Inside results as a “did you mean?” type suggestion when a search returns 0 matches. This approach would help reduce dead-ends and increase discoverability of the Search Inside feature. Thus the “Search Inside Suggestion Card” was born.
The design process started out as a series of Figma drawings:
Discussions with the design team helped narrow in on a prototype that would provide the patron with enough links and information to send them on their way to the Search Inside results page, a book page or the text reader itself, with occurrences of the user’s search highlighted. At the same time, the card had to be compact and easy to digest at a glance, so design efforts were made to make the quote stand out first and foremost.
After several revisions, the prototype evolved into this design:
Early Results
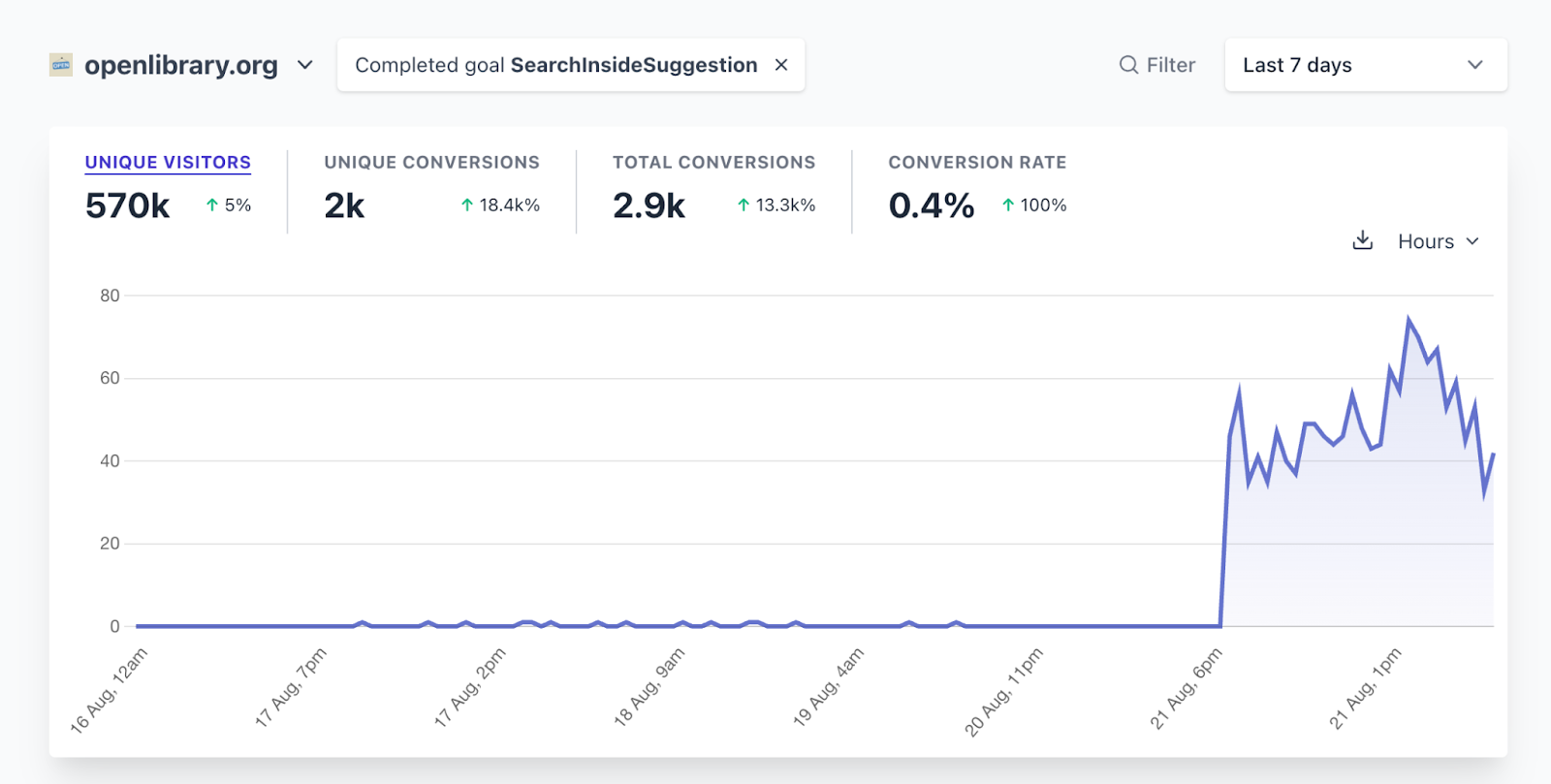
The Search Inside Suggestion card went live on August 21st and thanks to link tracks that I rigged up to all the clickable elements of the card, we were able to observe its effectiveness. Some findings:
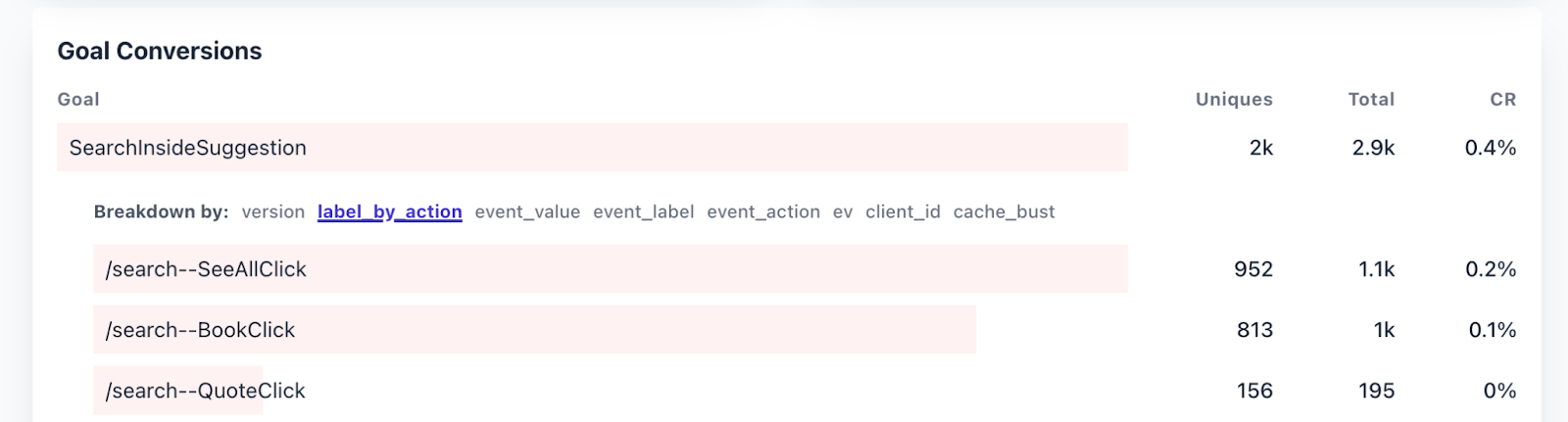
In the first day, 2k people landed on the Search Inside Suggestion card when previously they would have seen nothing. That’s 2,000 dead-end evasion attempts!
Of these 2,000 users, 60% clicked on the card to be led to Search Inside results.
40% clicked on one of the suggested books with a matching quote.
~8% clicked on the quote itself to be brought directly into the text.
I would’ve thought more people would click the quote itself but alas, there are only so many Comparative Literature majors in this world.
Follow-up and Next Steps
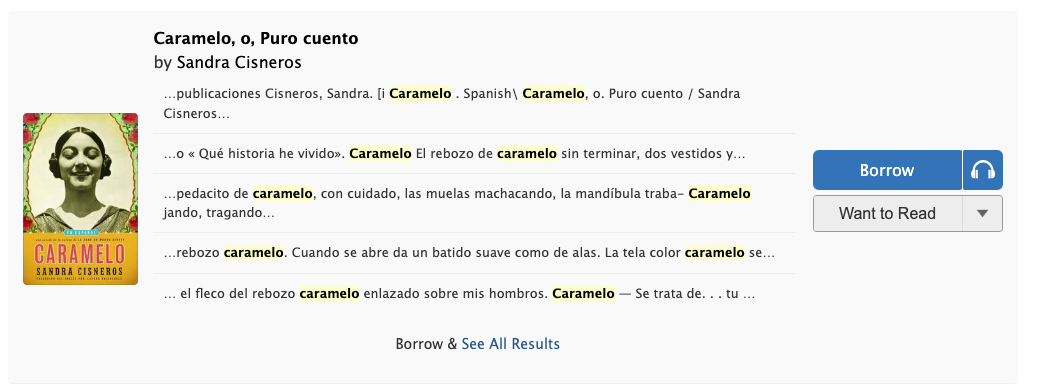
To complement the efforts of the Search Inside Suggestion card’s redirect to the Search Inside results page, I worked on re-designing the Search Inside results cards. My goal for the redesign was to make the card more compact and match its styling as closely as possible to the Search Inside Suggestion card to create a consistent UI.
Before:
After:
The next step for the Search Inside Suggestion card is to explore weaving it into the search results, regardless of result count. The card will offer an alternate search path in a list of potentially repetitive results. Say you searched ‘to be or not to be’ and there happens to be several books with a matching title. Rather than scrolling through these potentially irrelevant results, the search result card can intervene to anticipate that perhaps it’s a quote inside a text that you’re searching for. With the Search Inside Suggestion card taking the place of a dead-end, I’m proud to report that a search for “All grown-ups were once children…” will now lead Open Library patron’s to Antoine de Saint-Exupéry’s The Little Prince, page 174!
Technical Implementation
For the software engineers in the room who want a peek behind the curtain, working on the “Search Inside Suggestion Card” project was a great opportunity to learn how to asynchronously, lazy load “parts” of webpages, using an approach called partials. Because Search Inside results can take a while to generate, we decided to lazy load the Search Inside Suggestion Card, only after the regular search had completed.
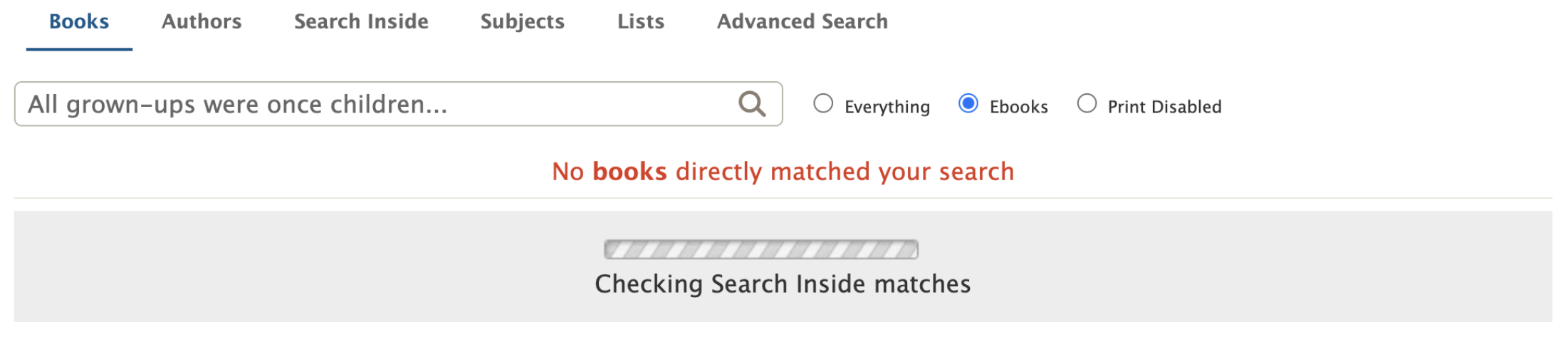
If you’ve never heard of a partial, well I hadn’t either. Rather than waiting to fetch all the Search Inside matches to the user’s search before the user sees anything, a ‘No books directly matched your search’ message and a loading bar appear immediately. The loading bar indicates that Search Inside results are being checked, which is UX speak for this partial html template chunk is loading.
So how does a partial load? There’s a few key players:
The template (html file) – this is the page that initially renders with the ‘No books directly matched your search’ message. It has a placeholder div for where the partial will be inserted.
The partial (html file) – this is the Search Inside Suggestion Card
The Javascript logic – this is the logic that says, “get that placeholder div from the template and attach it to an initialization function and call that function”
More Javascript logic – this logic says, “ok, show that loading indicator while I make a call to the partials endpoint”
A Python class – this is where the partials endpoint lives. When it’s called, it calls a model to send a fulltext search query to the database. This is where the user’s wrong turn is at last “corrected”. Their initial search in the Books tab that found no matching titles is now redirected to perform a Search Inside tab search to find matching quotes.
The data returned from the Python class is sent back up the line and the data-infused partial is inserted in the template from step 1. Ta-da!
About the Open Library Fellowship Program
The Internet Archive’s Open Library Fellowship is a flexible, self-designed independent study which pairs volunteers with mentors to lead development of a high impact feature for OpenLibrary.org. Most fellowship programs last one to two months and are flexible, according to the preferences of contributors and availability of mentors. We typically choose fellows based on their exemplary and active participation, conduct, and performance within the Open Library community. The Open Library staff typically only accepts 1 or 2 fellows at a time to ensure participants receive plenty of support and mentor time. Occasionally, funding for fellowships is made possible through Google Summer of Code or Internet Archive Summer of Code & Design. If you’re interested in contributing as an Open Library Fellow and receiving mentorship, you can apply using this form or email openlibrary@archive.org for more information.
A forward by Drini Cami Drini Cami here, Open Library staff developer. It’s my pleasure to introduce Rebecca Shoptaw, a 2024 Open Library Engineering Fellow, to the Open Library blog in her first blog post. Rebecca began volunteering with us a few months ago and has already made many great improvements to Open Library. I’ve had the honour of mentoring her during her fellowship, and I’ve been incredibly impressed by her work and her trajectory. Combining her technical competence, work ethic, always-ready positive attitude, and her organization and attention to detail, Rebecca has been an invaluable and rare contributor. I can rely on her to take a project, break it down, learn anything she needs to learn (and fast), and then run it to completion. All while staying positive and providing clear communication of what she’s working on and not dropping any details along the way.
In her short time here, she has also already taken a guidance role with other new contributors, improving our documentation and helping others get started. I don’t know how you found us, Rebecca, but I’m very glad you did!
And with that, I’ll pass it to Rebecca to speak about one of her first projects on Open Library: improving our translation/internationalization pipeline.
Improving Open Library’s Translation Pipeline
Picture this: you’re browsing around on a site, not a care in the world, and suddenly out of nowhere you are told you can “cliquez ici pour en savoir plus.”
Maybe you know enough French to figure it out, maybe you throw it into Google Translate, maybe you can infer from the context, or maybe you just give up. In any of these cases, your experience of using the site just became that much less straightforward.
This is what the Open Library experience has been here and there for many non-English-speaking readers. All our translation is done by volunteers, so with over 300 site contributors and an average of 40 commits added to the codebase each week, there has typically been some delay between new text getting added to the site and that text being translated.
One major source of this delay was on the developer side of the translation process. To make translation of the site possible, the developers need to provide every translator with a list of all the phrases that will be visible to readers on-screen, such as the names of buttons (“Submit,” “Cancel,” “Log In”), the links in the site menu (“My Books,” “Collections,” “Advanced Search”), and the instructions for adding and editing books, covers, and authors. While updates to the visible text occur very frequently, the translation “template” which lists all the site’s visible phrases was previously only updated manually, a process that would usually happen every 3-6 months.
This meant that new text could sit on the site for weeks or months before our volunteer translators were able to access it for translation. There had to be a better way.
And there was! I’m happy to report that the Open Library codebase now automatically generates that template file every time a change is made, so translators no longer have to wait. But how does it work, and how did it all happen? Let’s get into some technical details.
How It Began
Back in February, one of the site’s translators requested an update to the template file so as to begin translating some of the new text. I’d done a little developer-side translation work on the site already, so I was assigned to the issue.
I ran the script to generate the new file, and right away noticed two things:
The process was very simple to run (a single command), and it ran very quickly.
The update resulted in a 2,132-line change to the template file, which meant it had fallen very, very out of date.
I pointed this out to the issue’s lead, Drini, and he mentioned that there had been talk of finding a way to automate the process, but they hadn’t settled on the best way to do so.
I signed off and went to make some lunch, then ran back and suggested that the most efficient way to automate it would be to check whether each incoming change includes new/changed site text, and to run the script automatically if so. He liked the idea, so I wrote up a proposal for it, but nothing really came of it until:
The Hook
In March, Drini reached back out to me with an idea about a potentially simple way to do the automation. Whenever a developer submits a new change they would like to make to the code, we run a set of automatic tests, called “pre-commit hooks,” mostly to make sure that their submission does not contain any typos and would not cause any problems if integrated into the site.
Since my automation idea had been to update the translation template each time a relevant change was made, Drini suggested that the most natural way to do that would be to add a quick template re-generation to the series of automated tests we already have.
The method seemed shockingly simple, so I went ahead and drafted an implementation of it. I tested it a few times on my own computer, found that it worked like a charm, and then submitted it, only to encounter:
The Infinite Loop of Failure
Here’s where things got interesting. The first version of the script simply generated a new template file whether or not the site’s text had actually been changed – this made the most sense since the process was so fast and if nothing actually had changed in the template, the developer wouldn’t notice a difference.
But strangely enough, even though my changes to the code didn’t include any new text, I was failing the check that I wrote! I delved into the code, did some more research into how these hooks work, and soon discovered the culprit.
The process for a simple check and auto-fix usually works as follows:
When the change comes in, the automated checks run; if the program notices that something is wrong (i.e. extra whitespace), it fixes any problems automatically if possible.
If it doesn’t notice anything wrong and/or doesn’t make any changes, it will report a success and stop there. If it notices a problem, even if it already auto-fixed it, it will report a failure and run again to make sure its fix was successful.
On the second run, if the automatic fix was successful, the program should not have to make any further changes, and will report a success. If the program does have to make further changes, or notices that there is still a problem, it will fail again and require human intervention to fix the problem.
This is the typical process for fixing small formatting errors that can easily be handled by an automation tool. But in this case, the script was running twice and reporting a failure both times.
By comparing the versions of the template, I discovered that the problem was very simple: the hook is designed, as described above, to report a failure and re-run if it has made any changes to the code. The template includes a timestamp that automatically lists when it was last updated down to the second. When running online, because more pre-commit checks are run than when running locally, pre-commit takes long enough that by the time it runs again, enough seconds have elapsed that it generates a new timestamp, causing it to notice a one-line difference between the current and previous templates (the timestamp itself), and so it fails again. I.e.:
The changes come in, and the program auto-updates the translation template, including the timestamp.
It notices that it has made a change (the timestamp and any new/changed phrases), so it reports a failure and runs again.
The program auto-updates the translation template again, including the timestamp.
It notices that it has made a change (the timestamp has changed), and reports a second failure.
And so on. An infinite loop of failure!
We could find no way to simply remove the timestamp from the template, so to get out of the infinite loop of failure, I ended up modifying the script so that it actually checks whether the incoming changes would affect the template before updating it. Basically, the script gathers up all the phrases in the current template and compares them to all the incoming phrases. If there is no difference, it does nothing and reports a success. If there is a difference, i.e. if the changes have added or changed the site’s text, it updates the template and reports a failure, so that now:
The changes come in, and the program checks whether an auto-update of the template would have any effect on the phrases.
If there are no phrase changes, it decides not to update the template and reports a success. If there are phrase changes, it auto-updates the template, reports a failure and runs again.
The program checks again whether an auto-update would have any effect, and this time it will not (since all the new phrases have been added), so it does not update the template or timestamp, and reports a success.
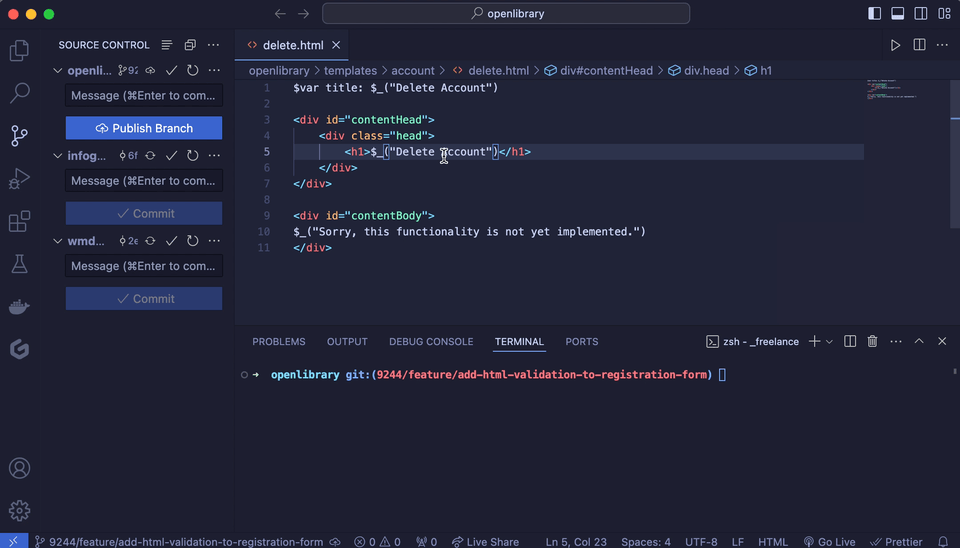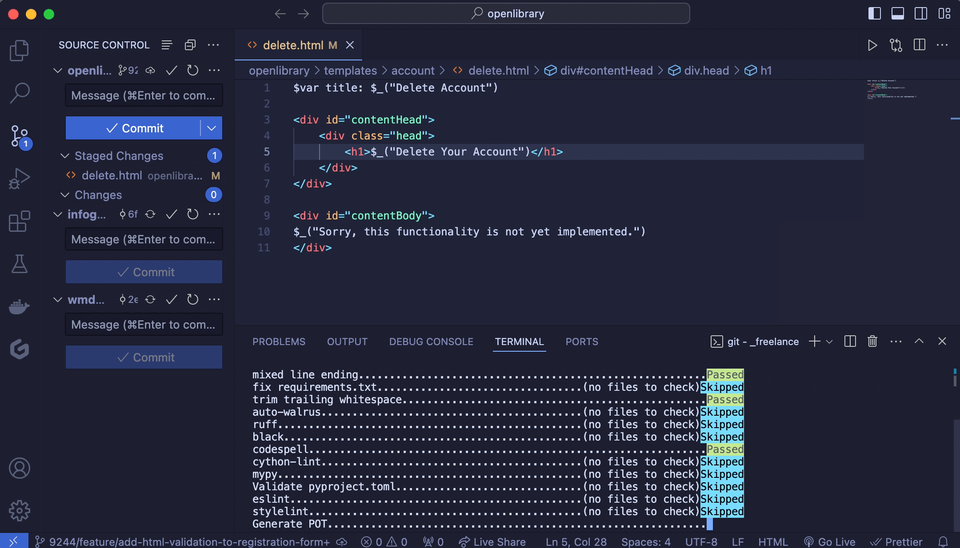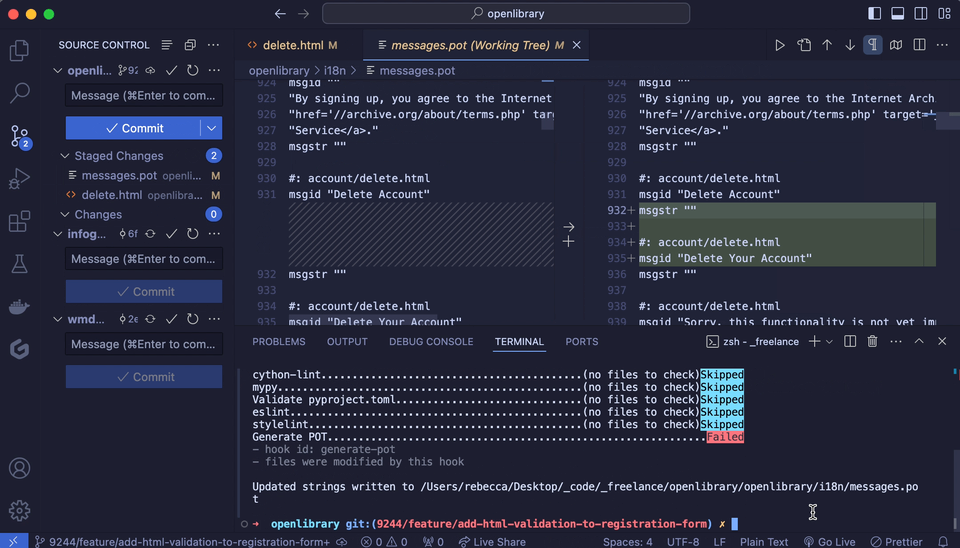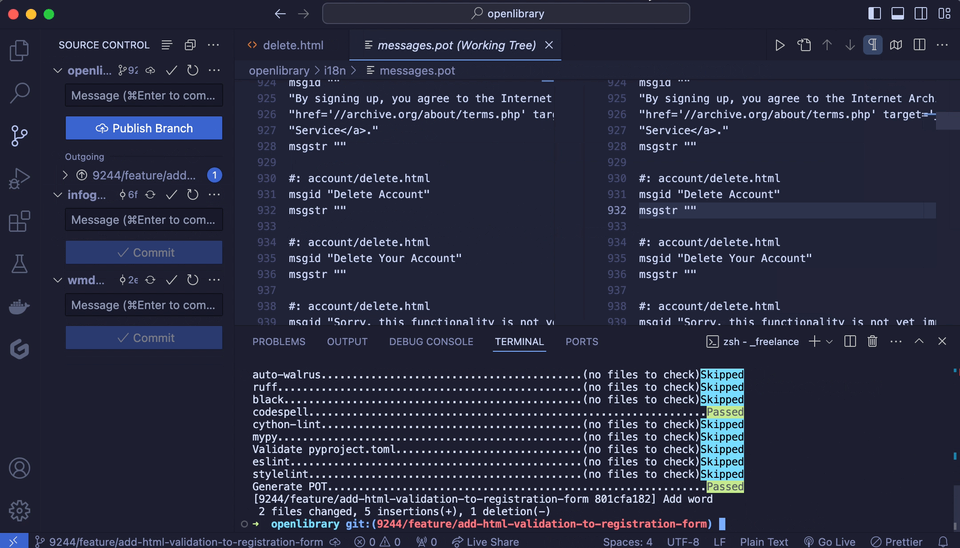
What it looks like locally:
I also added a few other options to the script so that developers could run it manually if they chose, and could decide whether or not to see a list of all the files that the script found translatable phrases in.
The Rollout
To ensure we were getting as much of the site’s text translated as possible, I also proposed and oversaw a bulk formatting of a lot of the onscreen text which had previously not been findable by the template-updating function. The project was heroically taken on by Meredith (@merwhite11), who successfully updated the formatting for text across almost 100 separate files. I then did a full rewrite of the instructions for how to format text for translation, using the lessons we learned along the way.
When the translation automation project went live, I also wrote a new guide for developers so they would understand what to expect when the template-updating check ran, and answered various questions from newer developers re: how the process worked.
The next phase of the translation project involved using the same automated process we figured out to update the template to notify developers if their changes include text that isn’t correctly formatted for translation. Stef (@pidgezero-one) did a fantastic job making that a reality, and it has allowed us to properly internationalize upwards of 500 previously untranslatable phrases, which will make internationalization much easier to keep track of for future developers.
When I first updated the template file back in February of this year, it had not been updated since March of the previous year, about 11 months. The automation has now been live since May 1, and since then the template has already been auto-updated 35 times, or approximately every two to three days.
While the Open Library translation process will never be perfect, I think we can be very hopeful that this automation project will make une grosse différence.