Earlier this year, the Internet Archive’s Open Library conducted a brief survey to learn more about patrons’ experiences and preferences when borrowing and reading books. As promised, we’ve anonymized the results and are sharing them with you!
The purpose of this survey was to better understand:
If, how, & why Open Library patrons download books
How patron reading preferences align with our offerings
Survey Setup
For one week, starting on Tuesday 2022-02-07, OpenLibrary.org patrons were invited to participate in a brief survey including 7 questions — one of which was a screener to ensure we only included the responses of patrons who have prior experience using the Open Library.
In total, 2,121 patrons participated in the survey and, after screening, 1,118 were included in the results.
Errata: In the original survey, the question asking patrons “When you DON’T DOWNLOAD the books you’ve borrowed from Open Library, what is your primary reason?”, we mistakingly omitted a “N/A – I Don’t typically download” option and we corrected this on day 1 of the survey.
6 Key Learnings
Around half of participants have used adobe content server with DRM to securely download their loaned books
Of participants who download their loans, the top reason (54%) is for offline access
Of participants who download their loans, a quarter do so because they prefer the EPUB text format to the image-based experience of the online bookreader.
Around 42% ofparticipants report difficulty downloading their loans. Of these participants…
69% were unable to locate a download option (or a download option didn’t exist for that book)
31% experienced found a download option but couldn’t get it to work
Around half of participants intentionally opt for BookReader for a variety of reasons:
Its simplicity & convenience; no app installation required
Many teachers can’t download on school computers
Many patrons don’t trust downloads, dislike DRM, or want their reader privacy protected
Some patrons have limited storage space
Around half of participants read for pleasure, the other half for some form of self-learning or research.
What participants said
~150 participants shared their praise, thanks, and personal inspirational stories
~75 participants offered productive critiques for how we could improve our book finding and book reading experiences
Fixing OCR, hiding menu bars while reading, zooming & scrolling, etc
~55 participants expressed concerns about “1 hour” lending duration
Some participants did not like the intrusive, non-dismissable Open Library banner
We heard feedback from the community loud and clear that the implementation of 1-hour loans may not always be ideal for all patrons. The Internet Archive has been exploring and prototyping various tweaks to lending, such as an auto-renewal mechanism, that could extend a loan automatically for a patron if, at the end of the loan period, the book is still actively being read.
I sit here, cosily on a cold winter’s night looking out over the Mississauga cityscape, thinking about the important mission we planned for and set out to accomplish almost a year ago: Empowering you, dear readers, to better search for and discover books on Open Library.
For too many years now you’ve been limited in how books can be found from Open Library’s extensive catalogue. Since the dawn of its existence, Open Library’s goal has been to make one web page for every book ever published. And to make those books accessible! But one problem with having millions and millions of book records, is that finding just the book you need can be difficult. Search is your gateway. Your one way to find what you’re looking for. But what if search can’t get you what you need?
Well for many readers, it was impossible to find what they were looking for. The search experience was plagued with limitations. It was impossible to find books in a certain language, or from a certain publisher. Sometimes, your search queries would even return no results at all — even for books actually in the library!
This past week I’ve been busy rolling out our improved search experience as the default across the site. Here are the previously impossible searches that are now possible!
Find borrowable or readable books in a specific language. Previously, the results wouldn’t guarantee that a borrowable or readable edition of the search result was in the specified language. Now you can! For example, for any fellow readers who are trying to learn German, you can now easily find Borrowable or Readable books in German ! Or… how about Spanish? Japanese? Polish? Take your pick!
Search results now prefer editions matching your language. If you have Open Library’s language set to French and you search for “harry potter”, you will see the French cover and title of Harry Potter first. Try it!
Combinations of edition query fields. Now, queries can filter on edition data as well as work data. All these queries used to be impossible on Open Library:
Search results now show the edition that best matches your query. Now, if you search for “one hundred years of solitude”, because your query is in English (regardless of your display language), the English title One Hundred Years of Solitude will be displayed instead of the original Spanish title, Cien años de soledad. Try it! Previously, searching for “one hundred years of solitude” wouldn’t match the correct book at all!
And for any developers out there, these features are also available via the Search API. You just need to add `editions` to the `fields` parameter to get back a new editions subfield with matching edition data.
Search is a behemoth, and there’s always more to do! Here are some of the tweaks and improvements we have lined up to improve upon this work:
Use this information in more places throughout the site
These changes required an overhaul of our core Solr-based search infrastructure to make search results edition-aware. But now that this information is in our search engine, we just need to add it to more and more places. These are features that readers have long desired for searching Open Library. And now, their expectations are reality! Open Library just got a little easier to use, and a little more accessible and inclusive.
Happy Reading!
Drini (with some generous writing support and photography from Bart Brewinski)
It seems like just the other day when the Open Library welcomed its 2 millionth registered patron in 2018. This year, we zoomed past 6M registered book lovers who collectively in 2022 have borrowed 4.3M books and counting, and who have added more than 4.7M books to their reading logs. Our book catalog expanded to nearly 38M editions and we cleaned up nearly 230k low quality records.
Together, our team released a flurry of features and improvements to the Open Library service including:
Imminently coming is a game changing smart edition-search upgrade, a Yearly Reading Goals feature, support for Web Books, a significantly more usable 1-stop “My Books” page, and design improvements to the Books Page.
In addition to the yearly community celebration, we’ve tried to make end-of-year review posts to give the community transparency into our victories, changes, and planning. In:
In 2021 we did a comprehensive Year-End Review which we’re following this year 😊
Gratitude. Central to these achievements were my fellow staff on the Open Library’s engineering team: Drini Cami, Jim Champ, & Chris Clauss. Equally indispensable to this year’s achievements was Lisa Seaberg from Internet Archive’s Patron Services team. Lisa is both a voice and champion for our patrons as well as the Open Library’s Lead Community Librarian who helps facilitate our community of 500 librarian contributors and our Super Librarians (Daniel, Travis, Onno, et al) who work tirelessly together to keep our library catalog organized. Charles Horn from the openlibraries.online team has been instrumental in keeping MARC records flowing into the catalog and Cari Spivack on policy support. And this year 6 Open Library Fellows — Hayoon Choi, Sam Grunebaum, Dana Fein-Schaffer, Scott Barnes, Constantina Zouni, and Teo Cheng — who selflessly committed several months of their time to improve the Open Library platform for the world, alongside a team of more than 30 volunteer developers from around the globe. Thank you, of course, to Brewster Kahle and all of our patrons and generous donors for believing in us and keeping us funded for another year. And a special thank you to a sorely missed Aaron Swartz, without whom none of this would be possible.
As of last week’s deploy, it’s now possible to search the Open Library for the books in your reading log by navigating to the My Books page, selecting the Currently Reading, Want to Read, or Already Read bookshelf, and typing in a search query.
Keep reading to learn tips and tricks on how to effectively search for books within your reading log.
A Forward by Mek
This year the Open Library has been exceedingly lucky to collaborate with Scott Barnes, a lawyer who has reinvented himself as a very capable software engineer. We had the pleasure of meeting Scott earlier this year while he was scouring the Open Library for old rock climbing guidebooks. Ever since joining one of our community calls, he’s been surmounting challenging technical hurdles as one of our most active 2022 Open Library Fellows. As law professor Lawrence Lessig famously penned in his 1999 book Code: “Code is law”. I guess that’s why we shouldn’t be too surprised how quickly Scott became familiar with the Open Library codebase, at the precision of his work and attention to detail, and his persistence in getting code just right without getting slowed down. We hope you’ll enjoy Scott’s contributions as much as we do and learn at least one new way of using the reading log search to improve your book finding experience.
A Forward by Drini I’m exceedingly pleased to introduce Scott Barnes to the Open Library Blog. I have had the honour of mentoring Scott throughout some of the projects on his fellowship, and have been floored by his love, passion, and skill in all things programming. Whether it’s working on user facing features (such as this one), improving code architecture, investigating performance issues, setting up infrastructure, or keeping up-to-date with new programming techniques by diving into a new programming book or topic, Scott is always excited to dive in, learn, and make an impact. And his code never fails to meet requirements while being well-architected and robust. I am so excited to see what he does next with his programming super powers! Because as far as I can tell, there’s no stopping him. Now without further ado, I’ll hand it off to Scott to talk about:
Reading Log Search
👋 Hi, my name is Scott Barnes. This year as a 2022 Open Library Fellow I collaborated with Drini Cami to develop reading log search. In this post, I’ll show different ways of effectively using the new reading log search feature, as well as technical insight into how it was engineered behind the scenes.
3 Ways of Searching your Reading Log using a Web Browser
Natural language search
The most common way to use search your reading log is by entering a natural, free-form search query, just like you might using your favorite search engine. From the Currently Reading, Want to Read, or Already Read page, you can search for your books on that reading log shelf by submitting text describing the book’s title, author name, ISBN, or publisher. An example could be “Lord of the Rings by J.R.R Tolkien”.
Keyword search
If you want greater control, you can also harness the power of Apache Solr, the underlying technology which powers the Open Library search engine.
Let’s say, for example, that you’d like to find books on your reading log by a specific author named “King” but using the Natural Language mode instead returns books with “King” in the title. Using keyword search, you could search for author: king to see only books by authors named “King” (while not seeing books with “King” in the title). On the other hand, if you only want to find titles matching “King” and not the author, you could instead search for the keyword title: king. Want to find your horror books? Try subject:Horror.
Reading log search, like the main Open Library search, supports boolean operators, specifically AND, OR, and NOT, along with wildcards such as * and ? to match multiple characters and a single character respectively. Therefore, to search for all books matching “climb”, “climber’s”, “climbs”, etc., that were published by Sierra Club Books that you want to read, you could visit Want to Read and search for title: climb* AND publisher: sierra club books.
NOTE: the boolean operators are CaSe sensitive, so AND will work as expected, but and will not. The actual search terms themselves are not CaSe sensitive, however, so “king” and “KiNg” will return the same results.
Now for the technical details! Reading log search was added in pull request #7052. In exploring how reading log search might be accomplished, two key things leapt to our attention:
Reading log records are stored in the database, and work and edition data (i.e. “books”) are stored in Solr; and
To work with the split data, we were probably doing more queries than we needed to, both in the back end itself, and within the templates that make up the pages.
The goal then was to add the ability to search the reading log, ideally while reducing the number of queries, or at least not increasing the number.
Changing the back end
Most of the heavy lifting was done in core/bookshelves.py. The challenge here was addressing the reading log records being in one database, and the edition data being in Solr.
The solution was to query the reading log database once, and then use those results to query Solr to get all the information we’d need for the rest of the process. Then we could simply pass the data around in a Python dataclasses, and then ultimately pass the results through to the templates to render for display in patrons’ browsers.
As mentioned, having the data in two places had led to some excess querying, which manifested itself in the templates where we re-queried Solr to get additional data to properly display books to patrons.
However, because we had gathered all of that information at the outset, we just had to change the templates to render the query results we passed to them, as they no longer had to perform any queries.
How you can help
Volunteers not only help make Open Library special, but they help make it even more awesome. Check out Volunteering @ Open Library.
Few aspects of a website have greater impact and receive less recognition than good navigation. If done well, a site’s main navigation is almost invisible: it’s there when patrons need it, out of the way when they don’t, and it zips patrons to the right place without making them overthink. Over the years, we’ve attempted improvements to our navigation but we haven’t had the design bandwidth to conduct user research and verify that our changes solved our patrons problem. It turns out, we still had several opportunities for improvement. That’s why this year we were incredible lucky to have collaborated with Open Library UX Design Fellow Dana Fein-Schaffer, who recently transitioned into design from a previous role as a neuropsychological researcher. Dana’s formal education and experience links a trifecta of complimentary fields — computer science, psychology, and design — and has resulted in unique perspective as we’ve endeavored to redesign several of Open Library’s core experiences: the website’s main navigation and the desktop version of our My Books page.
As an Open Library UX Design Fellow, Dana has been in charge of design direction, conducting user interviews, figma mockups, feedback sessions, and communicating decisions to stakeholders. In addition to her skill prototyping and notable problem solving capabilities, Dana’s warmth with the community, affinity for collaboration, and enthusiasm for the project has made teaming up with her a gift. While we’d rather the fellowship not end, we endorse her work with great enthusiasm and highly recommend organizations which share our values to view Dana’s portfolio and engage her for future design opportunities.
The Design Process
Hello, I’m Dana Fein-Schaffer, and I’ve been working as a UX Design Fellow with Open Library over the past several months. I’m currently transitioning into UX Design because after gaining professional experience in both psychology research and software engineering, I’ve realized that UX is the perfect blend of my skills and interests. I’ve been enjoying growing my UX skillset, and working with Open Library has been a perfect opportunity for me to gain some formal experience because I love reading and was hoping to work on a book-related project. Moving forward, I’m particularly excited about working as a UX designer for an organization that focuses on social good, especially in the literary, education, or healthcare spaces! If you have a role that may be a good fit, or if you work in one of those industries and are interested in connecting, please feel free to reach out. You can also learn about me from my portfolio.
Problem
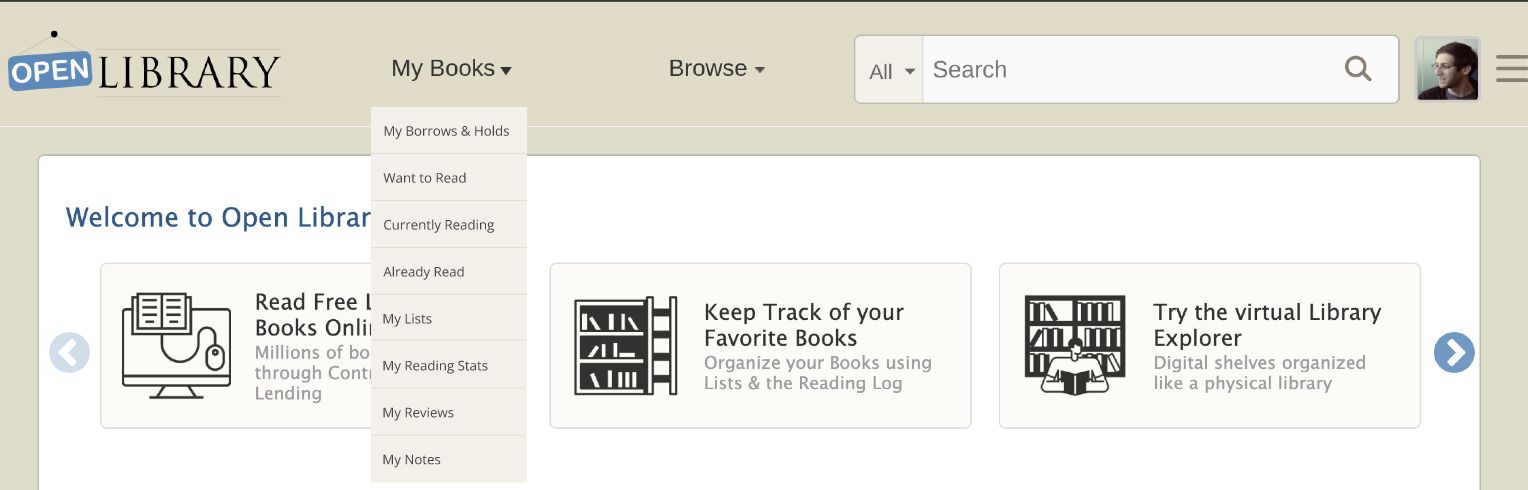
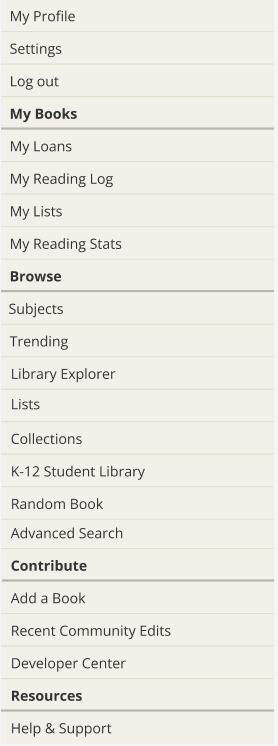
At the beginning of my project, the current navigation bar and hamburger menu looked like this:
I met with members of the Open Library team to identify three key areas of concern:
The label “more” was not descriptive, and it was unclear to patrons what this meant
The hamburger menu was not consistent with the navigation bar items
The hamburger menu was confusing for patrons, especially new patrons, to navigate
Approach
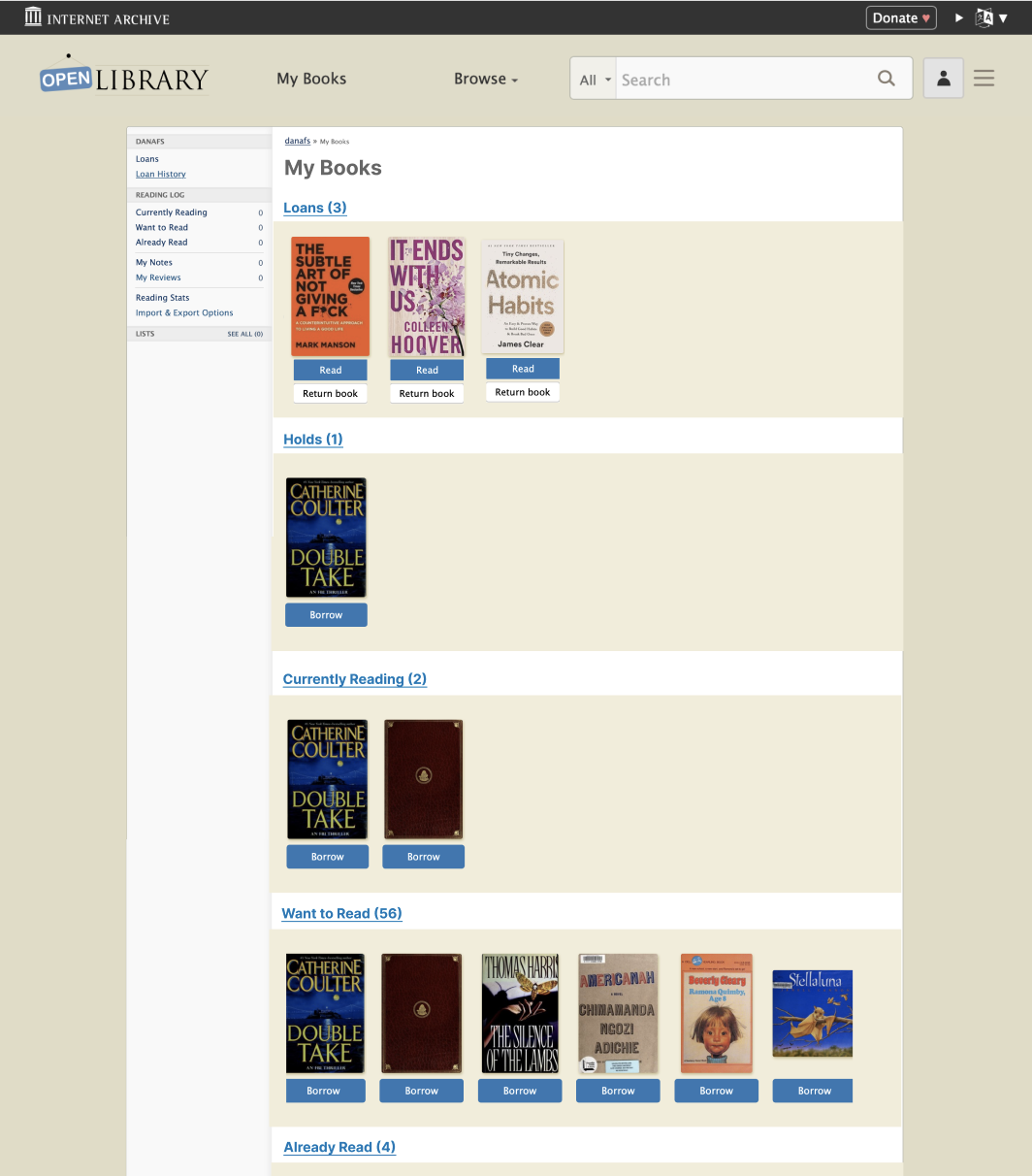
Before I began my project, the Open Library team decided to implement an interim solution to the first point above. To address the concern with the “more” label, the navigation menu was changed to instead include “My Books” and “Browse.” The website analytics showed that patrons frequent their Loans page most, so for now, the “My Books” page brings patrons to the Loans page.
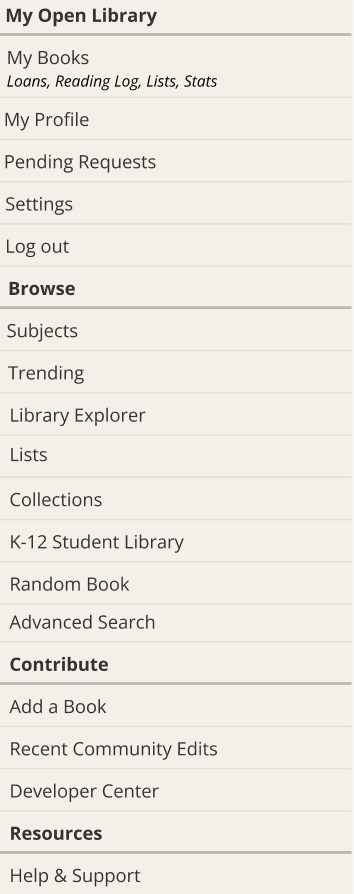
To begin redesigning the main site navigation, I first created a prototype in Figma with some potential solutions that built off of this updated navigation menu:
I created a dropdown menu for “My Books” that would allow patrons to select the specific page they would like to go to, rather than automatically going to the Loans page
I reorganized the hamburger menu to be consistent with the navigation menu and to use the subheadings of “Contribute” and “Resources” instead of “More.” I felt that these changes would make the hamburger menu easier to navigate for both new and long-time patrons.
After creating the prototype, my next goal was to get feedback from patrons, so I scheduled user interviews with volunteers.
User Interviews
I conducted user interviews via Zoom with four patrons to answer the following questions:
How do users feel about the My Books dropdown?
Are users using My Books and Browse from the navigation menu or hamburger menu?
Are users able to effectively use the hamburger? Do they find it easier or harder to find what they’re looking for using the reorganized hamburger?
Results & Findings
Three out of the four patrons preferred the dropdown, and the fourth user didn’t have a preference between the versions. The patrons enjoyed having the control to navigate to a specific section of My Books.
All users used the navigation menuat the top of the page to navigate, rather than the hamburger menu, which supported the switch to “My Books” instead of “More.” This finding also highlighted the need to make sure patrons could access the pages they wanted to access from the top navigation menu.
Finally, all four patrons found the existing hamburger menu confusing and preferred the reorganized hamburger. Some patrons specifically mentioned that the reorganized hamburger was more compact and that they felt that the headings “contribute” and “resources” were more clear than “more.”
Synthesis and a New Direction
After learning from the user interviews that patrons preferred increased granularity for accessing My Books and a more concise hamburger menu, the Open Library team began discussing the exact implementation. We wanted to keep the navigation and hamburger menus consistent; however, we also wanted to provide many options in the My Books dropdown, which made the hamburger menu less concise.
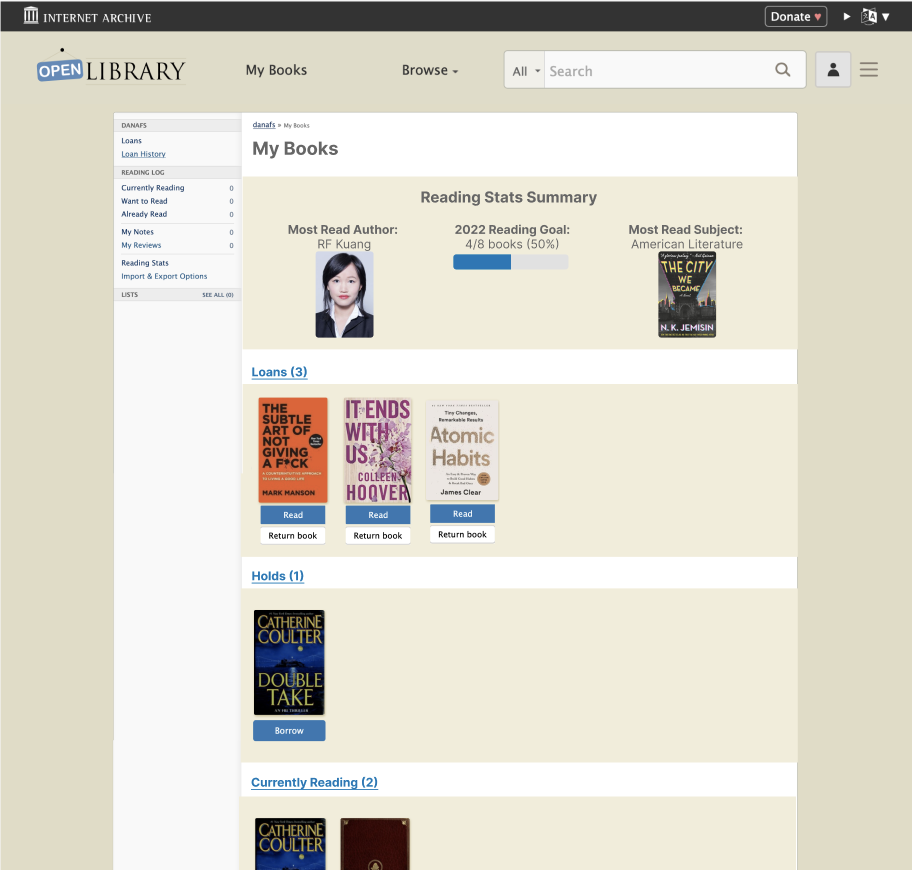
At the same time that we were debating the pros and cons of various solutions, another Open Library UX Design fellow, Samuel G, was working on designing a My Books landing page for the mobile site. Inspired by his designs, I created mockups for a desktop version of the My Books page. Having a My Books page that summarizes patrons’ loans, holds, and reading log at a glance allows patrons to still have increased control over My Books navigation while keeping the hamburger menu concise, since all of the individual My Books items can now be condensed into one link.
Furthermore, having a My Books landing page opens the door for more ways for patrons to interact with their reading through Open Library. For instance, I’ve created a mockup that includes a summary of a patron’s reading stats and yearly reading goal at the top of the page.
As we work towards implementing this design, I’m looking forward to getting feedback from patrons and brainstorming even more ways to maximize the use of this page.
Reflections
Working with the Open Library team has been an amazing experience. I’m so grateful that I got to lead a UX project from start to end, beginning with user research and ending with final designs that are ready to be implemented. Working with such a supportive team has allowed me to learn more about the iterative design process, get comfortable with sharing and critiquing my designs, and gain more experience with design tools, such as Figma. It was also a great learning experience that sometimes your projects will take an unexpected turn, but those turns help you eventually come to the best possible design solution. Thank you to everyone who provided feedback and helped me along the way, especially Mek, who was a wonderful mentor, and Sam, who was a great collaborator on our My Books mobile and desktop project!
About the Open Library Fellowship Program
The Internet Archive’s Open Library Fellowship is a flexible, self-designed independent study which pairs volunteers with mentors to lead development of a high impact feature for OpenLibrary.org. Most fellowship programs last one to two months and are flexible, according to the preferences of contributors and availability of mentors. We typically choose fellows based on their exemplary and active participation, conduct, and performance within the Open Library community. The Open Library staff typically only accepts 1 or 2 fellows at a time to ensure participants receive plenty of support and mentor time. Occasionally, funding for fellowships is made possible through Google Summer of Code or Internet Archive Summer of Code & Design. If you’re interested in contributing as an Open Library Fellow and receiving mentorship, you can apply using this form or email openlibrary@archive.org for more information.