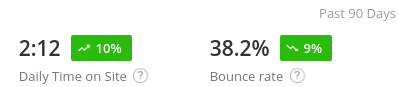
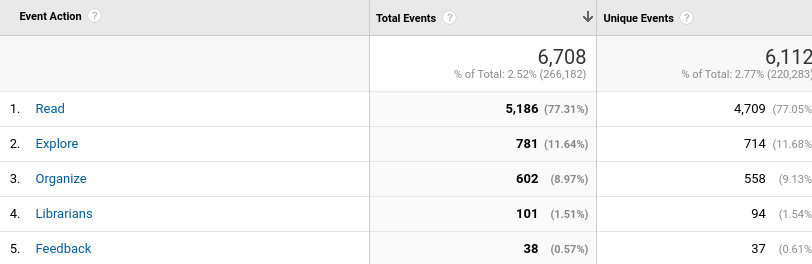
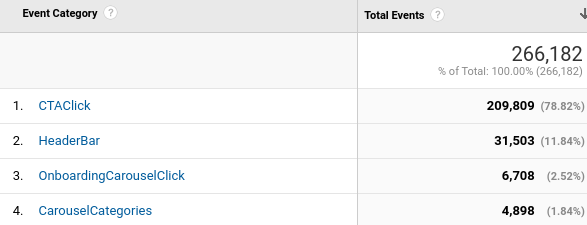
For nearly 15 years Open Library has been giving patrons free access to information about books in its catalog, direct to their computers. But for millions of readers across the globe who rely on their phones for access, this hasn’t always presented the ideal mobile reading experience.
This year, a volunteer within the Open Library community named Mark developed an independent mobile app, an unofficial companion to the website called the Open Library Reader. This lite app, which is available for free from the Apple store and Play store, emphasizes the mobile reading experience and showcases the books within a patron’s Open Library reading log. It’s a great way to take your personal library with you on the go.
While Open Library Reader is an unofficial app which is not maintained or supported by the staff at Internet Archive, we’re ecstatic that talented volunteers within our community are stepping up to design new experiences they wish existed for themselves and others. We applaud Mark, not only for the time he invested and showing what’s possible with our APIs, but — true to the spirit of Open Library — for sharing his app for free with patrons, in such a way which seems to respect patron privacy.
We sat down with Mark for an interview to learn why he created the Open Library Reader and which of its features may be appreciated by book lovers who are on the go.
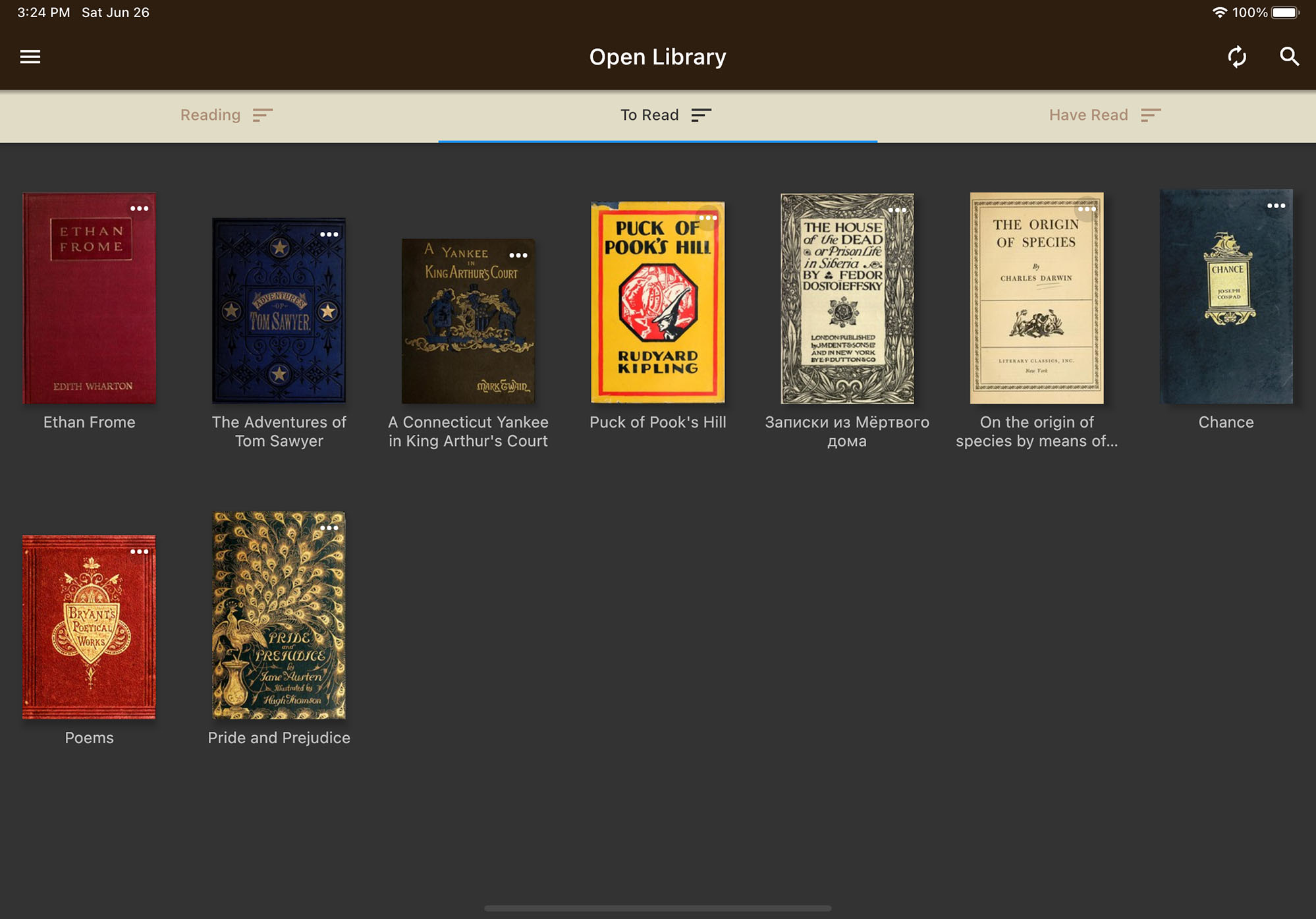
A picture of a patron’s personal library when logged in to the Open Library Reader app
Open Librarian: “Why did you find the need to build an Open Library Reader?”
Mark: I read a lot of books on my iPad, especially old, hard-to-find mystery novels. Open Library has a lot of great reads, but I was getting frustrated trying to manage my Reading Log and read books in the tablet browser. There was a lot of scrolling and clicking around, a tap in the wrong place could send me off somewhere else, and the book I was reading was always surrounded by browser and bookreader controls. I just wanted to sit down and read, and not have to be reminded of the fact that I was looking at a website through a browser.
Open Librarian: What were some of the approaches Open Library Reader used to solve these problems?
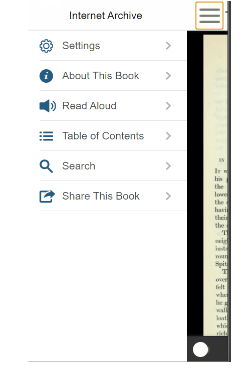
Mark: I thought about some of the good tablet-based reading experiences I’ve had, and imagined what it could look like if the interface were centered around the individual reader and the small set of tools they need to find, manage, and read books. So the Reading Log shelves and the reading interface are the core of the app, and everything else kind of happens at the edges. Everything you need is just one tap away. The reading interface is still the familiar Internet Archive BookReader, but I’ve overlaid some additional functionality. You can hide all the controls with the single tap, and the book expands to completely fill the screen. I also added a swipe gesture, so it’s easy to turn pages if you’re holding your device with one hand on the couch.
Open Librarian: What does it feel like to use? Can we have a tour?
Mark:
Open Librarian: What is your favorite part of the app? I like how it shows the return time
Mark: That is cool — that’s another example of centering the needs of the reader. It’s hard to pick a favorite part. Every feature is the result of me reading in the app every day for months before I released it. Periodically, I’d think “that’s kind of annoying” or “I wish I could…” and I’d go code for a while until I was happy with the experience. But the full-screen reading mode is probably my favorite. With the high-resolution page scans expanded to fill the screen, it’s almost like reading a physical book.
Open Librarian: What was your experience like developing the Reader?
Mark: I’m a retired web developer, so interface design, user experience, APIs and that sort of thing are nothing new, but I’ve never built a native app. After some reading, I picked Google’s Flutter tool, which allows easy cross-platform app development. I was amazed at how fast it was to assemble a simple app with just a few lines of code, and then it was just a matter of layering on the functionality I wanted. I spent a lot of time exploring the Open Library and Internet Archives APIs to figure out the best way to get at the data I needed, and even submitted a few updates to the Open Library codebase to support features I wanted to build. The Open Library team was extremely welcoming and supportive, and really made this app possible.
How can you support Mark’s work?
First, try downloading the Open Library Read App from the Apple store or Play store. If you have a suggestion, question, or feedback for Mark, send him an email to olreader@loomis-house.com. If you appreciate his work, consider rating the app on the app stores and leaving a review so others may discover and enjoy it too. To learn more about Mark and the Open Library Reader, look out for his upcoming interview on the Open Library Community Podcast.
Want to contribute to Open Library too?
See all the ways you can volunteer within the Open Library community!