Back in 2020, we started the tradition of hosting an annual Community Celebration to honor the efforts of volunteers across the globe who help make the Open Library project possible.
Tomorrow, Tuesday, October 31st at 9am Pacific, we warmly invite the public to join us in a small gathering to celebrate the hardworking humans who keep the website going, see demonstrations of their accomplishments, and get a glimpse into our direction for 2024 — Halloween Edition!
During this online celebration, you may look forward to:
Announcements of Our Latest Developments: Discover the impact of our recent initiatives and how they’re making a difference.
Opportunities to Participate: Learn how you can get involved and become an active member of our volunteer community.
A Sneak Peek Into Our Future: Get an exclusive glimpse of what lies ahead in 2024 and how we’re shaping the future together.
For all the latest updates leading up to the event, be sure to follow us on Twitter by visiting https://twitter.com/openlibrary. Looking for ways to get involved?
Mark your calendars, spread the word, and get ready for an event that’s all about our incredible community. We can’t wait to see you there!
Earlier this year, the Internet Archive’s Open Library conducted a brief survey to learn more about patrons’ experiences and preferences when borrowing and reading books. As promised, we’ve anonymized the results and are sharing them with you!
The purpose of this survey was to better understand:
If, how, & why Open Library patrons download books
How patron reading preferences align with our offerings
Survey Setup
For one week, starting on Tuesday 2022-02-07, OpenLibrary.org patrons were invited to participate in a brief survey including 7 questions — one of which was a screener to ensure we only included the responses of patrons who have prior experience using the Open Library.
In total, 2,121 patrons participated in the survey and, after screening, 1,118 were included in the results.
Errata: In the original survey, the question asking patrons “When you DON’T DOWNLOAD the books you’ve borrowed from Open Library, what is your primary reason?”, we mistakingly omitted a “N/A – I Don’t typically download” option and we corrected this on day 1 of the survey.
6 Key Learnings
Around half of participants have used adobe content server with DRM to securely download their loaned books
Of participants who download their loans, the top reason (54%) is for offline access
Of participants who download their loans, a quarter do so because they prefer the EPUB text format to the image-based experience of the online bookreader.
Around 42% ofparticipants report difficulty downloading their loans. Of these participants…
69% were unable to locate a download option (or a download option didn’t exist for that book)
31% experienced found a download option but couldn’t get it to work
Around half of participants intentionally opt for BookReader for a variety of reasons:
Its simplicity & convenience; no app installation required
Many teachers can’t download on school computers
Many patrons don’t trust downloads, dislike DRM, or want their reader privacy protected
Some patrons have limited storage space
Around half of participants read for pleasure, the other half for some form of self-learning or research.
What participants said
~150 participants shared their praise, thanks, and personal inspirational stories
~75 participants offered productive critiques for how we could improve our book finding and book reading experiences
Fixing OCR, hiding menu bars while reading, zooming & scrolling, etc
~55 participants expressed concerns about “1 hour” lending duration
Some participants did not like the intrusive, non-dismissable Open Library banner
We heard feedback from the community loud and clear that the implementation of 1-hour loans may not always be ideal for all patrons. The Internet Archive has been exploring and prototyping various tweaks to lending, such as an auto-renewal mechanism, that could extend a loan automatically for a patron if, at the end of the loan period, the book is still actively being read.
Hello, I am Jayden Teoh, a student from Singapore, and this year I participated as a 2023 Google Summer of Code contributor with the Internet Archive’s Open Library project to improve the site’s performance and supercharge subject pages.
If you are an Open Library patron, you have likely encountered times where certain pages seem to take and eternity to load. The Open Library team understands the importance of a smooth browsing experience and empathizes with how degraded site performance affects patrons. This is why we prioritized site performance as a key focus for our 2023 GSoC roadmap. As strongly as we felt about improving the core performance of the current website, we also wanted to push the boundaries of Open Library’s capabilities by releasing community-powered subject pages we hope will help patrons more easily showcase and discover books they’ll love. I’m excited to share more about what we accomplished and next steps in our plans.
Improving Site Performance
According to Browserstack,”40% of visitors will leave a website if it takes longer than three seconds to load”. But how do we measure which pages are slow or fast? How do we determine if a slow load time is an anomaly or a systemic pattern? Do we care about improving the average load time for a page or eliminating the most egregious case where pages load especially slowly?
Identifying site performance issues can be a challenging task. In order to effectively address this issue, Mek, a GSoC mentor for the project, suggested the use of performance tracking tools such as Sentry, as well as considering Google’s Core Web Vitals metrics, using Google’s PageSpeed Insights (PSI) reports and running Lighthouse audits.
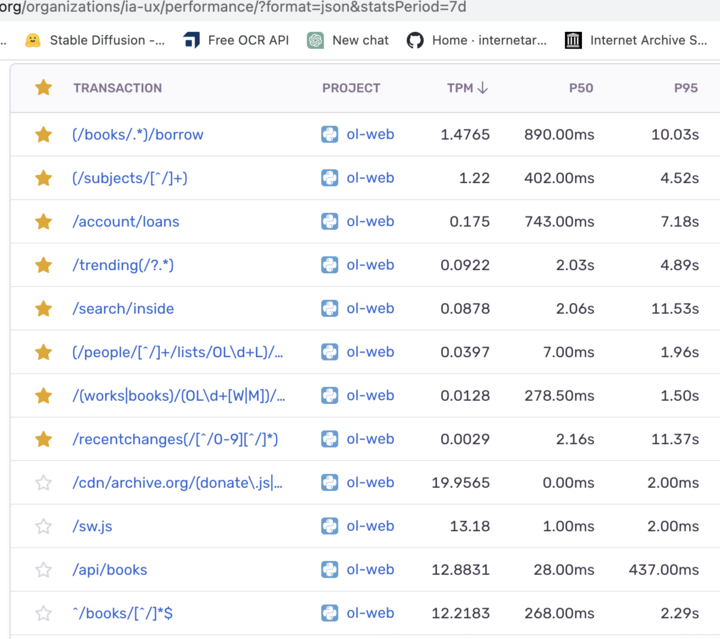
Sentry, a visual dashboard often used for error monitoring, has a “Performance” mode we were able to use to identify and rank pages according to metrics called P50 and P95 — the upper bound number of seconds at which 50% (P50) and 5% (P95) of transaction took to complete. For example, a P95 score of 5 seconds tells us that 95% of such requests completed within 5 seconds (and perhaps 5% were slower). Once we ranked pages in consideration of these metric, it became clearer just how bad certain pages could be in worst case scenarios. We coupled this information with our own domain expertise about which pages are most important to the average patron’s experience and then embarked on a journey with the aspiration of reducing the average load time of key pages by at least half.
For each row in Sentry’s performance dashboard, one can “drill in” to the page to see stack tracebacks and detailed breakdowns about which functions were participating most to the slow response.
Our research revealed 2 opportunities:
The “Search Inside” page was taking more than 11 seconds and an average of more than 2 seconds because the response was making redundant archive.org metadata request on each search result match on the page to determine each book’s availability, rather than computing the availability of all the books in a single request.
Several of the slow pages had a common slow component — the LoanStatus borrow button — which we could speed up by caching and thus “feed two birds with one scone”.
By the end of the 12 weeks of this program, we manage to reduce the load times of several key pages significantly. One of my proudest achievements was the reduction of the ‘search/inside’ page by over 500%. This feature is important to patrons because it allows them to search for content within books, rather than just searching based on the author and title so I am glad we were able to make this feature faster and thus more accessible.
Editor’s note: We are still collecting metrics and plan to add before-and-after graphs of the search inside page speeds. Our changes to the borrow button are in the process of being staged and tested and we’re excited to update this blog post with metrics in the future. Hopefully you have noticed the improvements since it was launched a few weeks ago!
Unleashing the Power of Subject Tags
Empowering Librarians and Expanding Book Categorization at Open Library
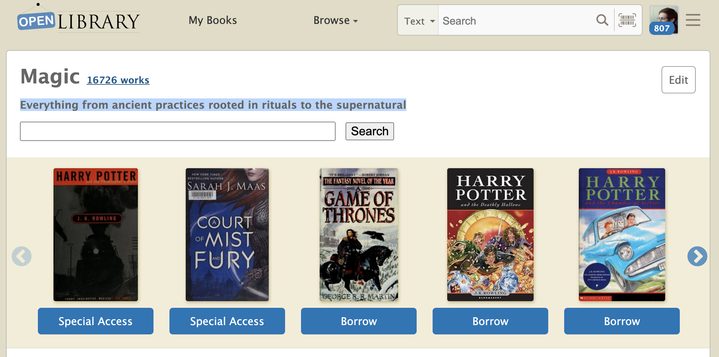
For almost a decade, the Open Library has had basic subject pages that give readers a way to browse or search for books on a given topic, see books with similar subjects, and discover prolific authors of a genre. It may surprise you to learn that the whole page experience is generated based on the name of the subject. For instance, when one visits the “Magic” subject page, one may notice a carousel of books that is populated using a query based on its name: “subject:magic“. This approach gives us a simple formula for creating millions of subject pages on-the-fly, but it also has significant shortcomings.
Namely, subject pages are incapable of storing additional metadata about a given subject and the current subject pages is limited to showcasing a single carousel of books. If the subject is overly vague, like “textbooks“, the reader may often not be shown a useful set of books and there’s no affordance provided that helps the reader narrow their search further, e.g. to design textbooks. If we search for a subject called “design textbooks“, we are informed no matching subjects exist. However, if we do an intersecting search for books that are subject:textbooks AND subject:”industrial design”, there are a few interesting results! The problem is, there’s currently no mechanism which allows librarians to extend Open Library subjects and specify which book collections should show up.
My primary objective through GSoC was to give librarians the ability to enrich and edit any subject page on Open Library so each page may be as beautiful and thoughtfully curated as a library or bookstore showcase. Our solution was to give librarians the ability to create a new “Tag” document for any subject page and load it with custom logic to extend how that subject page should be rendered. Tags serve as a catalyst for librarians to provide more precise categorizations within broad subjects. By leveraging Subject tags, librarians can dive deeper into specific areas of interest, allowing readers to discover a rich array of sub-subjects. For instance, librarians might choose to add new rules into the Tag document for the Cooking subject featuring carousels for vegan and budget cooking, in order to make it more useful for readers. This granularity opens up a world of possibilities, enabling readers to explore their preferred niches and discover hidden gems within subjects they cherish. Just like how a physical library may rotate their bookshelves with new categories every month, Subject Tags grant librarians more freedom to curate interesting subject topics that may suit patrons, allowing for a more personal and humane touch to the book discovery process.
By now, I hope you are able to understand just how pertinent Subject Tags will be to our Open Library and why it is a privilege for me to be working on such an important feature. Although the idea is clear, the implementation certainly is not. Open Library’s database is built using our own niche and complex Wiki engine called Infogami. To create a new class of data, we would have to create a new Infogami type. Here’s the catch: there has not been a new Infogami type created in the last 13 years and there is no existing documentation for doing so. Navigating any new code architecture can be a tedious task for any programmer and now I had to miraculously work with an arcane technology that no one knows how to use? What could go wrong?
Thankfully, I had the support of a wonderful community and amazing mentors like Mek, Jim, and Drini. They provided me with a lot of guidance throughout the process of reverse engineering the creation of an Infogami type. And after months of work, I was able to successfully incorporate a new Subject Tags Infogami type into the Open Library architecture. Especially since Open Library is an open-source project, I decided to write a tutorial and document the unintuitive technical aspects of implementing a new Infogami type, as a gift to help future developers who may wish to extend the functionality of the platform in similar ways. The tutorial can be found here.
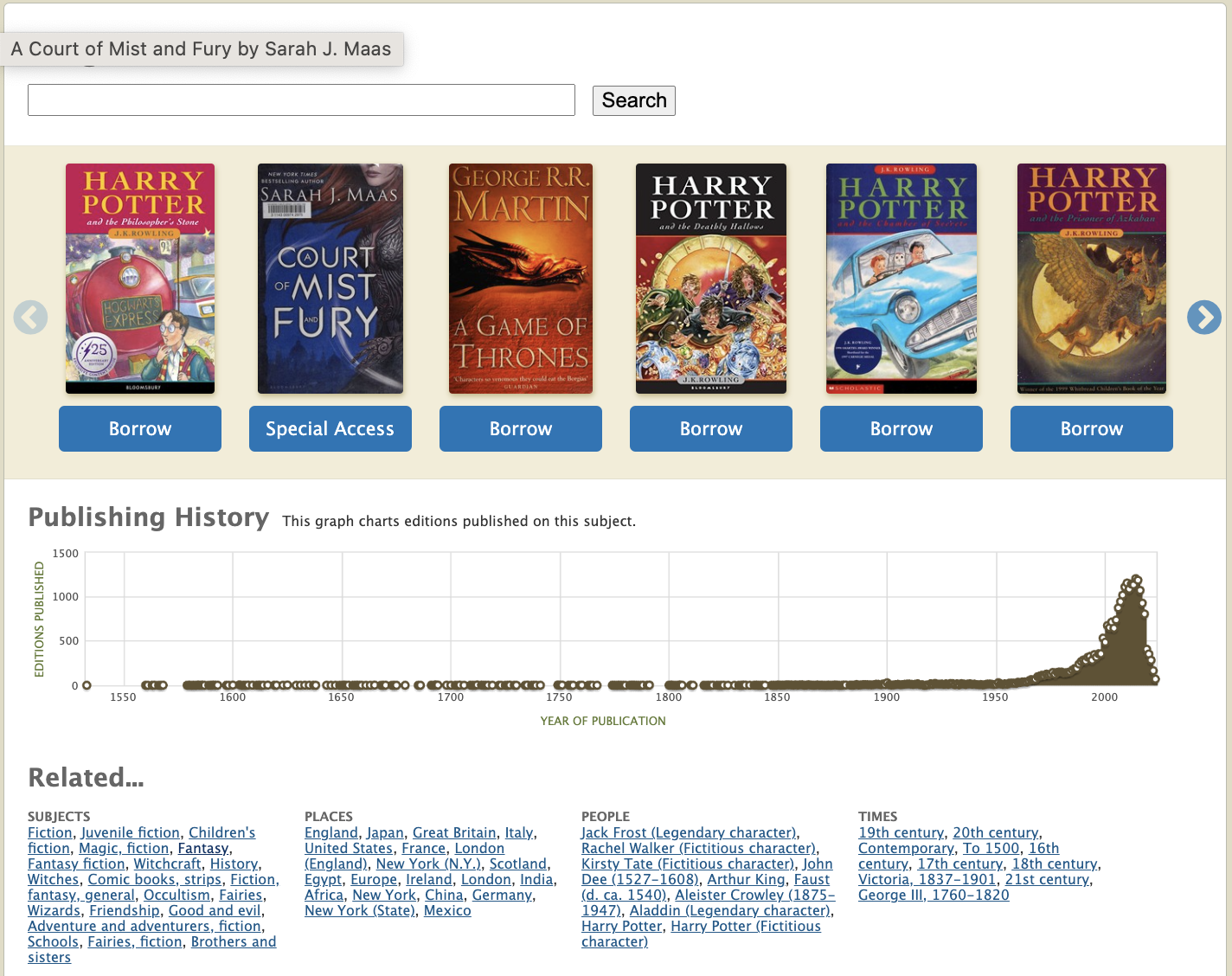
Now, let me show you the power of Subject Tags and how they can be used to enrich the Open Library’s Subject pages. Let’s use the ‘Magic’ subject page as an example. This is how it looks right now.
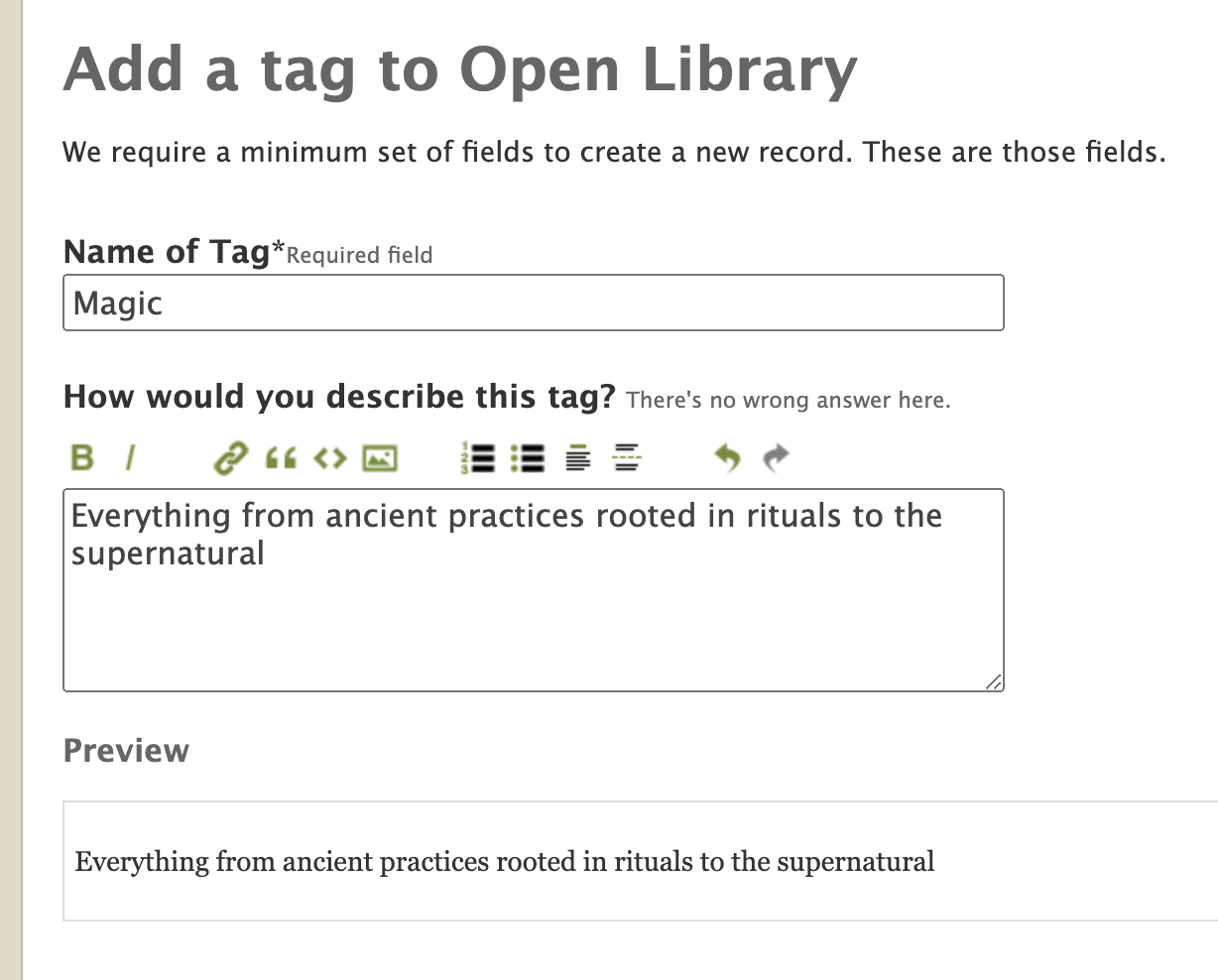
As you can see, currently the subject page is plain with no description about what the subject is about. That’s not very informative is it? Prior to Subject Tags, we are unable to store more information about subjects because they are just strings with no capabilities to store other metadata. However, now with the Subject Tags, we can do that! Let me show you how. First, let’s add a new Subject Tag into the Open Library for the ‘Magic’ subject.
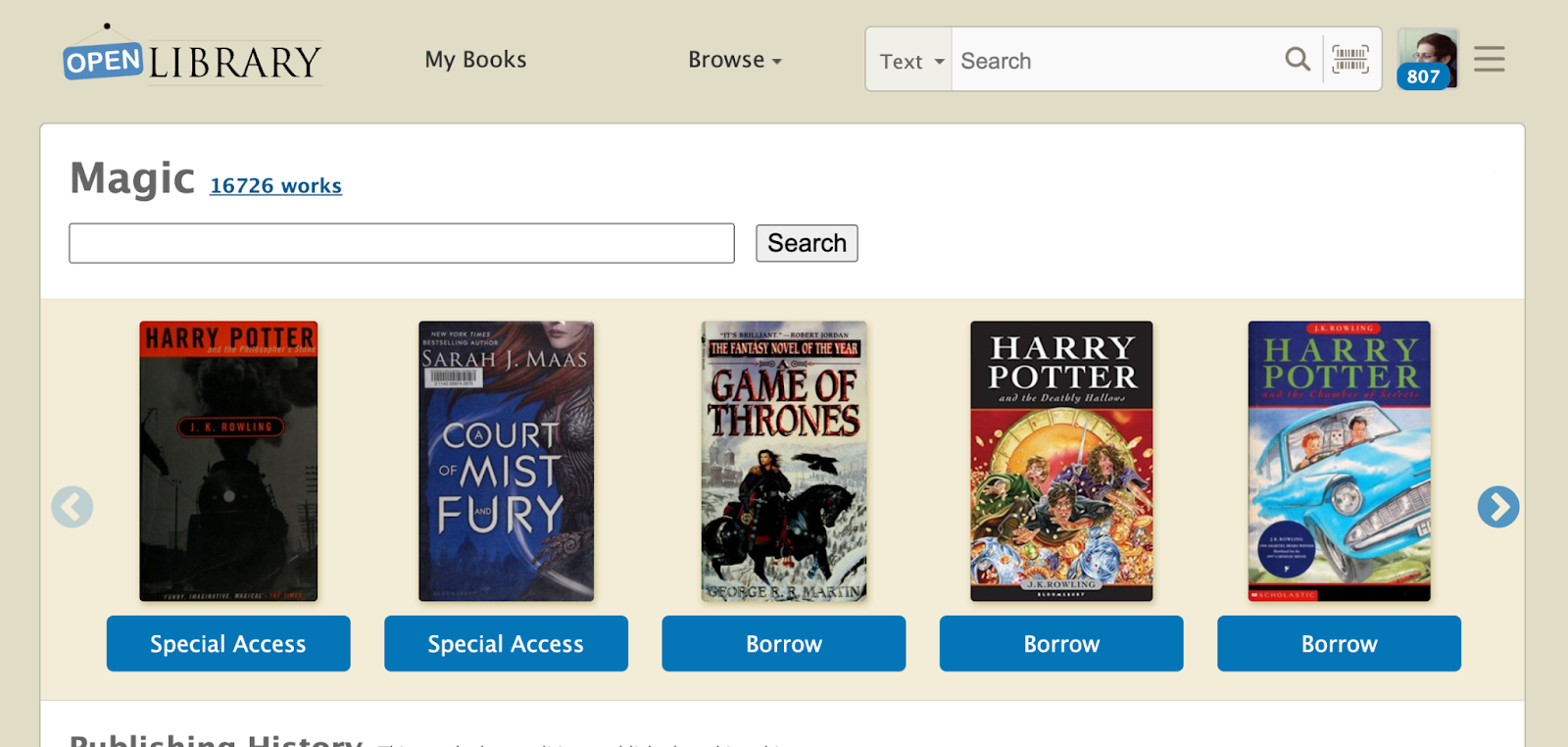
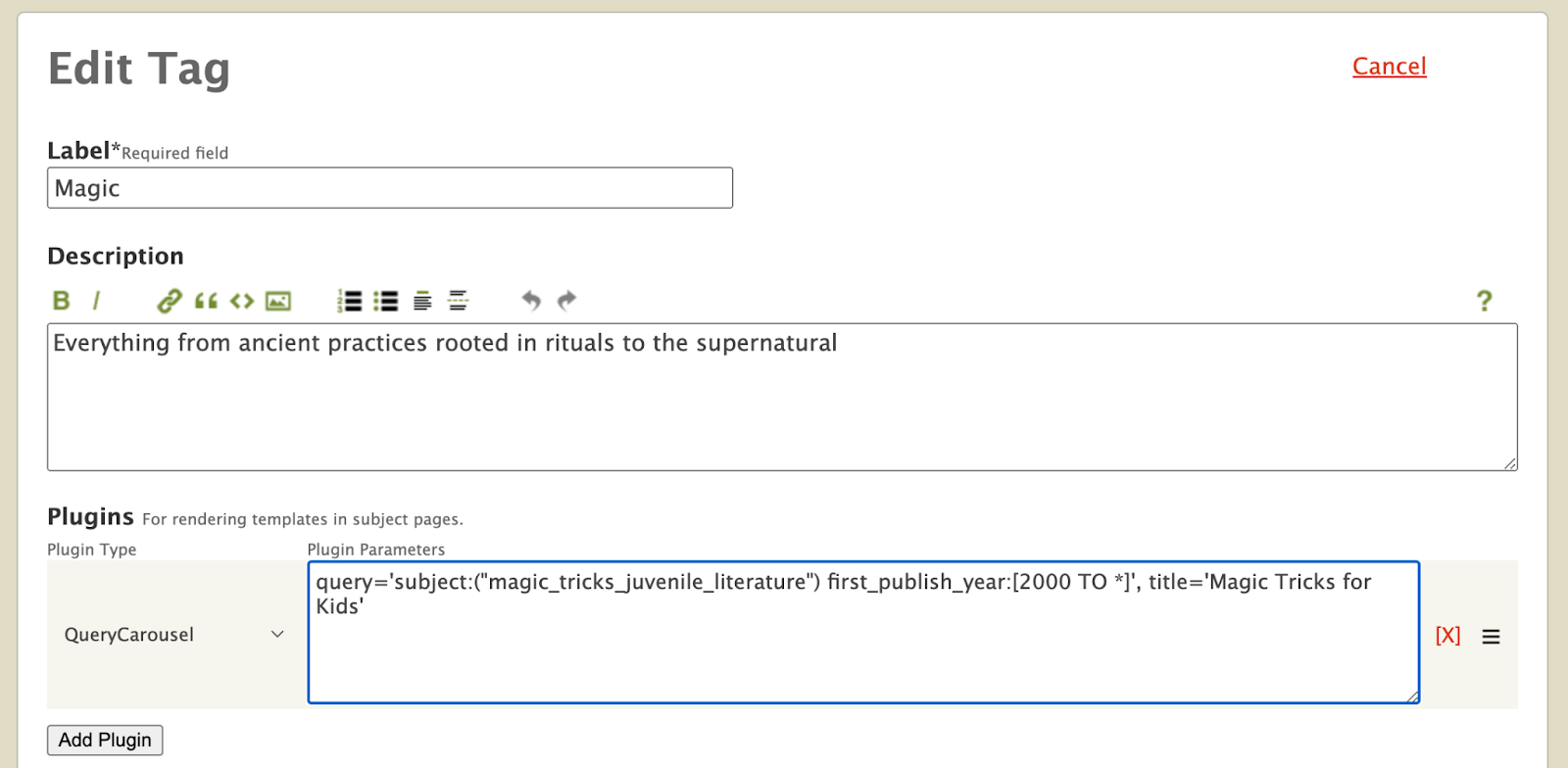
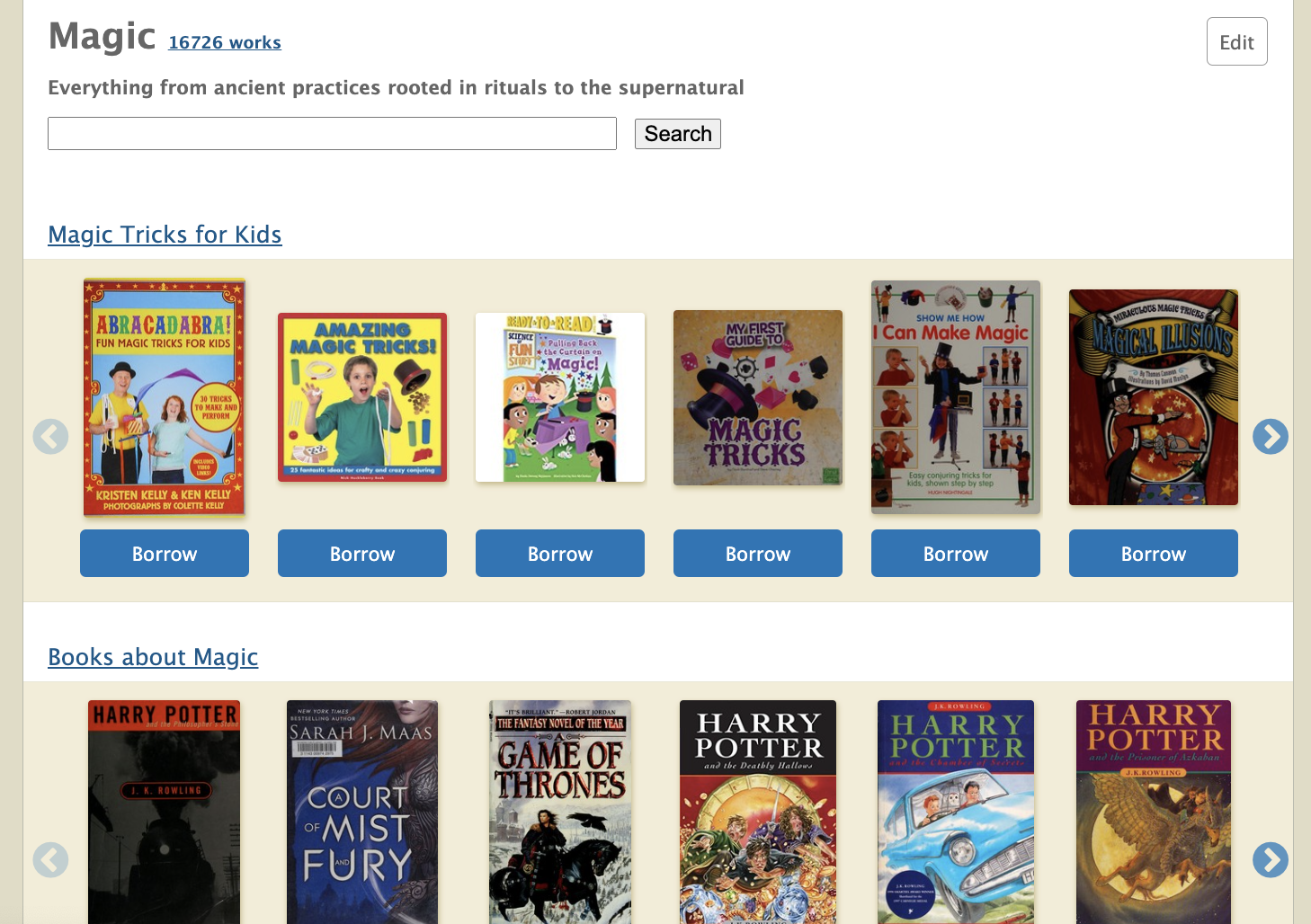
The Subject Tag creation form allows us to store metadata about the ‘Magic’ subject, including its description. After we’ve created the Subject Tag, let’s head back to the ‘Magic’ subject page. Tada, we can now see the newly added description in the subject page.
You are probably still not convinced of the utility of Subject Tags. Let me give you a deeper glimpse into the realm of possibilities that Subject Tags offer. Currently on the Magic page, we are only able to display a carousel with books that have the subject ‘Magic’. What if we want to include a carousel displaying books about ‘Magic Tricks for Kids’? Well, with Subject Tags, now we can! As a librarian, we can edit the ‘Magic’ Subject Tag and use the experimental Plugin to define a new carousel. Right now, the interface is quite advanced, is still being prototyped, and is intended for expert librarians who know how to compose queries, but in the future we aim to make it easy for any librarian to extend the functionality of subject pages using Tags.
Plugins allow subject pages to load custom templates within our system and utilizes them to enrich the subject page. For example, in the Plugins field of the Subject Tag edit form above, we included a new QueryCarousel Plugin that allows the ‘Magic’ subject page to search for all books with the “magic tricks juvenile literature” subject and display them in a template carousel. Let’s take a look at the ‘Magic’ subject page again.
Fascinating isn’t it? Subject Tags have enabled the enhancement of the previously one-dimensional subject pages. Through Subject Tags, librarians are now equipped to curate and display information that can enrich the book discovery experience of patrons.
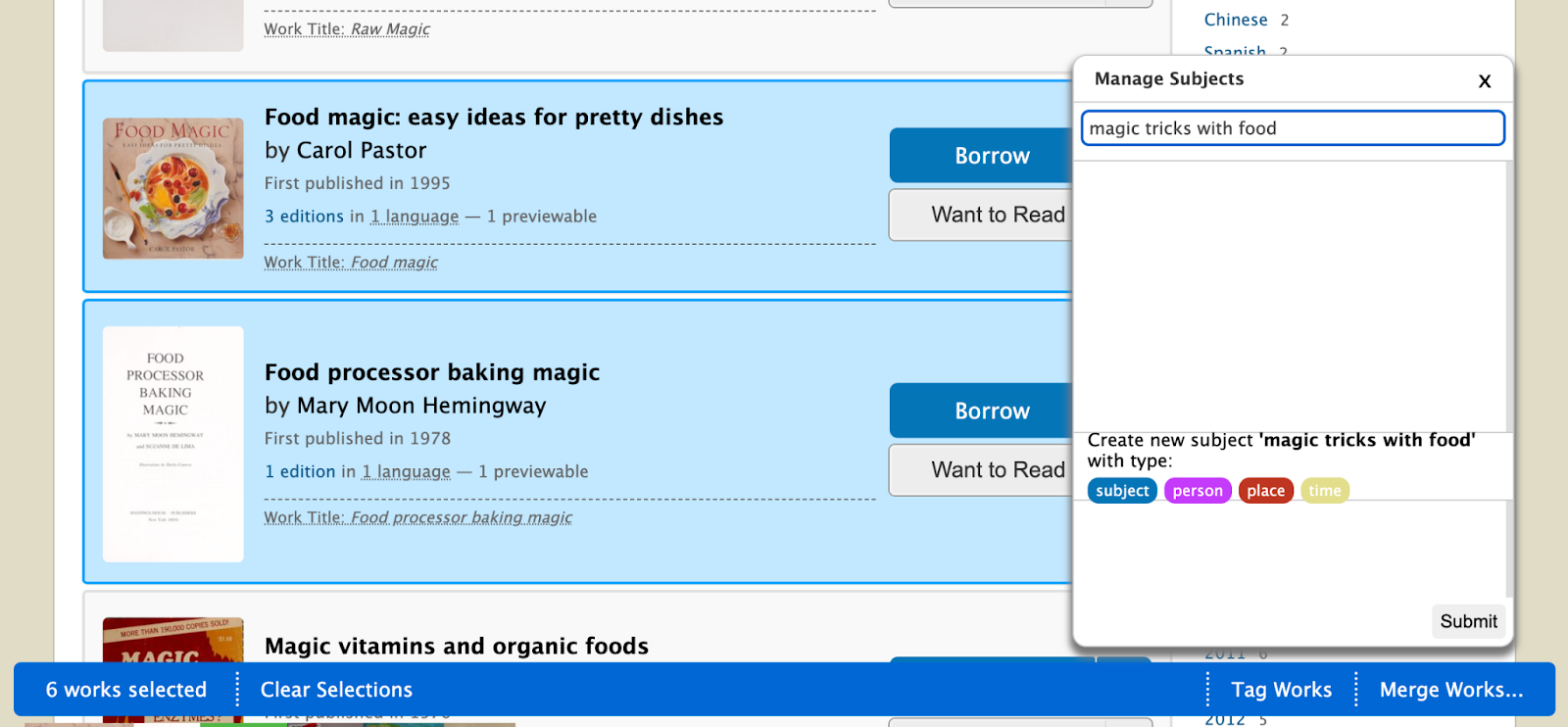
What happens when librarians want to add a new carousel of books to a subject page but the books haven’t been labeled with subjects? When we developed the Tag feature, adding a subject to books had to be done one book at a time. To aid librarians in the process of curating books and subjects, I also implemented a Bulk Tagging tool that enables librarians to add subjects to multiple books simultaneously.
Subject Tags are still in beta so we can time our time understanding the needs of our patrons and the librarians who will use these new tools. As a next step, we have decided to do research on where this feature can have the most impact and will focus our efforts on enriching a small handful of specific subject pages using Tags. One subject we’re excited to prototype with is ‘Cooking’. The team has been curating the best cooking-related information to showcase using Subject Tags and testing new features to launch alongside Subject Tags. Here is a mockup by Roya, a fellow in our design community, showing one possible UI we have in mind:
When Subject Tags are launched, we hope you can visit the ‘Cooking’ page and provide us with input on what we can improve on and what you would like to explore in a Subject page. With your feedback, librarians will have a better understanding on how to enhance your book exploration process with personally curated topics. Moving forward, we will utilize Subject Tags to enrich other subject pages on the Open Library and slowly phase out the mundane subject pages we have currently.
Ending note
Thank you to the incredible Open Library community for their unwavering support over these past months. A special shout-out goes to Mek, whose mentorship has been nothing short of exceptional. Not only has Mek dedicatedly guided me through the program, but also gone the extra mile to make sure I’ve had the most enriching learning journey. Lastly, my deepest thanks to the Internet Archive and Google Summer of Code for making it possible for me to be a part of this life-changing experience. This is an experience that I’ll never forget.
Hello, I’m Nick Norman – I volunteer as the Lead Communications Fellow at the Internet Archive’s Open Library.
The Open Library provides readers with free, digital access to millions of library books, but we can only help readers who know we exist. My mission is to cultivate an inclusive communications program that helps even the most remote readers discover and access our free services, learn about new features, and stay informed about the latest library news. In the service of achieving this goal, I’ve spent the past several months designing a strategic communications plan for OpenLibrary.org.
In this post I’ll share my personal story. I’ll also teach why effective communication is essential to helping patrons, explain how we’re structuring our communications strategy, and share what we’ve achieved so far.
For me, volunteering was always in the books
Open Library’s mission of being a free, public, open source catalog of books is personal to me because my parents were both librarians and my mother was a writer. Growing up, my library card was one of my most prized possessions and I seldom left home without it. In 2020, I took my library card digital by participating in an Open Library hackathon – a unique social event where volunteers of all backgrounds joined together for a few intense hours with the shared goal of improving the website together.
During this event, I felt supported by a passionate community of designers, engineers, and librarians. It was the Open Library community’s emphasis on inclusivity that truly resonated with me and motivated me to apply and become an Open Library Fellow. As someone who has felt personally marginalized and overlooked, the community’s commitment to equity and inclusion holds deep significance to me.
Empowered by these experiences, I’m proud to direct my expertise in communications to help bridge the gap between the many overlooked readers who need access to books and the bountiful books lining Open Library’s digital shelves.
The Importance of Communications
The greatest minds may develop the world’s greatest ideas and still fail to reach the minds of others. Some of Nikola Tesla‘s most brilliant inventions ended up being coopted by more effective communicators; his invention of Alternating Current was capitalized by Thomas Edison and his Tesla Coil, which proved the concept of wireless transmission, was popularized by Guglielmo Marconi who applied the technology to produce the iconic radio.
Since connecting with other humans through storytelling is such an important aspect of effective communication, here is a story of a renowned scientist named James Hutton, who in 1785 failed to excite those at the Royal Society of Edinburgh, despite making the groundbreaking (pun intended) discovery of tectonic plates. You can probably guess why based on this excerpt from Hutton’s writing recounted in Bill Bryson’s book, “A Short History of Nearly Everything”:
A practitioner may architect the grandest service with every bell and whistle, but if it doesn’t reach the right audience and get presented in a way that resonates with their needs, it’s unlikely to stick. It’s a sentiment perfect captured by Dr. George Berkeley in his proverbial question, “If a tree falls in a forest and no one is around to hear it, does it make a sound?”
So how might a project go about communicating a message effectively? What does effective communication look like and what does it achieve? At Open Library, we start with a desired outcome, like teaching patrons about a new feature, and then gain additional clarity by applying a framework to answer 5 Ws:
For Whom is the message intended (audience)?
Why is the message being broadcast (purpose)?
What is the strategy, tone, and approach for the message (content)?
When will the message be broadcast (timing)?
Where & howwill the message be broadcast (distribution)?
Within each of these 5 W’s, there are opportunities for experimentation and testing to measure and improve success. Where did readers prefer to receive our messages — on twitter or our email distribution channel? Was broadcasting a message when it was 2pm better for readers than 5pm? Was what we sent out engaging to readers? For those who read the news, were we able to reach librarians or did we reach teachers instead? As we systematically break down communications into smaller problems and a framework for testing and improving success, we begin to see that it’s a lot of work. The more news there is to publish, the more features to announce, and the broader the audience, the more challenging it can be to effectively coordinate answers to each of these questions.
Communications Challenges at Open Library
Open Library’s growth over the past several years, driven both by the challenges of the COVID pandemic as well as a continuous torrent of new features, has led to increased demand by patrons looking for resources to guide their experience. The absence of a formal communications program has made it challenging to produce content at this large a volume and frequency — particularly articles for our blog. No one person could do it well and so our first objective has been to explore streamlined processes for coordinating the production and distribution of high quality content.
The production of each blog post involves multiple stages: ideation, research, graphics, writing, editing, promoting, and evaluating impact. With a small team, one could only produce a few quality articles a month. Scaling this process requires first having a formal process for producing a single blog post and then understanding where the bottlenecks are, which tasks may be parallelized, and developing effective training tools for a volunteer community where contributors are likely to come and go based on their busy schedules. In a scenario where multiple blog posts are being authored at once, we also needed a system for coordinating progress and needs across blog posts.
Solution: Our Communications Program
To address the challenge of not having a communications program in place, we initiated a period of planning and strategizing which has led to some amazing achievements. One notable accomplishment is the successful implementation of a dedicated Slack channel, serving as a space for our communications team to work together on a diverse range of projects. Additionally, our communications channel fosters cross-functional collaboration by allowing leads from within Open Library to join and contribute to the progress of intersecting projects.
Another significant accomplishment is the creation of our communications homebase, providing a central location for our communications efforts. Within the homebase, volunteers can access information about active projects and stay updated on the latest strategies being developed. Additionally, the homebase serves as a valuable resource for understanding our communication guidelines, community rituals that foster inclusion, and policies that shape our collaborative environment. By establishing a dedicated communications homebase, we have successfully tackled the challenges associated with showcasing active communications projects and onboarding volunteers at varying engagement paces. The homebase also plays an important part in keeping everything organized, streamlining volunteer contributions into our Slack space and ensuring everyone’s impact is truly felt.
Another achievement by our communications team is the implementation of a bi-weekly communications video call. This gives us balance between working on projects in our Slack space and having real time check-ins to connect and share updates, provide support, and engage in discussions around intensive aspects of projects such as our blog program, a project that’s been our center focus.
Through the progress we’ve made with our blog program, we have defined processes and identified key roles to form a team of dedicated volunteers responsible for producing one blog post at a time. Each team will consist of a project lead, content writer & graphics, editor, and promoter. This structured approach not only allows us to scale up with additional teams as new volunteers join but also enables us to accommodate the expanding scope of future blog posts.
The ongoing development of the blog program has enabled us to establish two distinct pathways for volunteers to participate. Individuals can choose to fill a specific role in the production of blog posts or they join a blog testing team, which helps us to test and explore best approaches to expanding the program as needed. Here are a few links to documents pertaining to testing and the development of our blog program.
In the process of obtaining these learnings for our blog, our team of volunteers have also been able to advance Open Library’s communications efforts by creating 15 pilot episodes of an amazing unofficial community podcast. In doing so, we’ve achieved a better understanding of what it takes to run a podcast program where community members are empowered to help produce episodes.
Ways to Contribute
You can learn more about our progress with the podcast by visiting here, as we eagerly anticipate sharing an update in the future.
If you’re inspired by the work we’re doing in our communications program, we’d love for you to join us. You can do so by visiting our volunteer page or you can visit our fellowship page to learn more about contributing that way.
Personal Reflections
The process required for a single person to produce a blog post is very different from the systems and conventions required for a team to coordinate on producing content collaboratively. As a fellow on the communications team, I am quite proud to contribute to the mission of Open Library to bring online books to patrons and to serve as a champion for the idea that every reader should be included.
Reflecting on my journey from the time I first arrived at Open Library to where I am today, it feels like I have traversed two entirely different worlds. Each person I’ve encountered throughout my fellowship has played a significant role in contributing to expanding my professional skillsets and fueling my drive for promoting inclusion and accessibility in my work and daily interactions.
Work with Nick
While I intend to continue volunteering with the Open Library to further its communications program as a fellow, I am seeking career opportunities to support developing communications programs for communities, both online and offline. I love engaging with communities and making people feel welcomed. If your community would benefit from working with a communications specialist, please do not hesitate to contact me. I am also open to being contacted with opportunities to share my expertise through speaking, writing, or mentoring others in implementing similar communications programs.
Shoutouts
In Buddhist culture, “Dana” embodies the spirit of generosity. Mek Karpeles, the leader of the Open Library project, has exemplified this virtue by selflessly dedicating his time to help not only myself but also many others in their personal and professional growth. Just as Buddha teaches, I have gratefully received his gift with open hands and intend to share it freely with others.
I also want to thank Wendy Hanamura, the Director of Partnerships at Internet Archive, for providing me with valuable mentoring and foundational knowledge in communications prior to the start of my fellowship here at Open Library. It is a great privilege for me to have both Mek and Wendy as mentors in the same lifetime.
I would like to also acknowledge the valuable contributions from the members of our communications team over the past several months: Rachel Bayston, Urja Upadhyaya, Debbie San, Samuel Grunebaum, Crystal Mares, Roselle Oswalt, and many other volunteers who have played a crucial role in advancing our communications program from the planning phase to its actualization. Their feedback and contributions have greatly enhanced my learning and professional development.
Finally, I want to express my deepest appreciation to the many staff members and community leads across the Internet Archive and Open Library and volunteers who have provided their support to our communications program. Here are some of those names: Lisa S., Chris Freeland, Drini Cami, Jim Champ. Mark H., Brenton Cheng.
Last year, as part of our inaugural ‘Internet Archive Summer of Design fellowship,‘ we conducted design research on making our Books Page easier for patrons to navigate on both desktop and mobile devices. We are excited to announce that a significant number of these improvements have been implemented this past month.
We extend our heartfelt appreciation to Hayoon Choi, Jim Champ, Katherine McGonigle, Jayden Teoh, and all the dedicated individuals involved in bringing these changes to life.
Key design updates we made to the our Books Page:
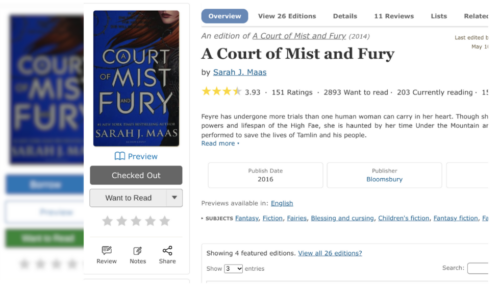
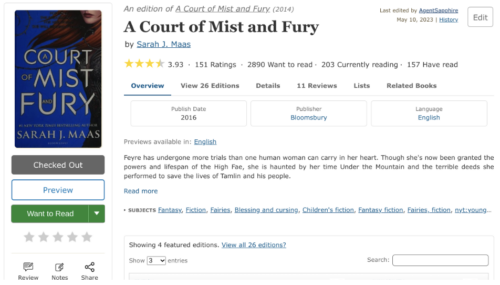
Navigation Menu. The Books Page navigation menu has been designed to be more visually clear and relocated to the top of the page, directly beneath the main menu for better discovery. As you scroll, the fixed sub navigation menu dynamically highlights the corresponding section option based on the scroll position within the website.
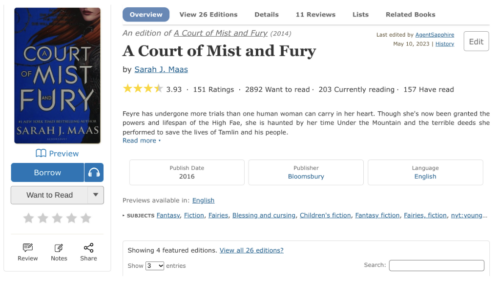
Buttons. Because we had so many buttons competing for attention, the “Preview” button has been replaced with a more subtle link below the book cover. The prominent green “Want to Read” button has also been updated to a more neutral gray color. Finally, on mobile, the share button has been moved up from below the fold, next to the title.
Mobile. The Mobile Books Page now features the book title and author first, then a prominent book cover, and finally available read options, all above the fold.
Desktop
Before
After
Mobile
Before
After
Feedback Welcome
In pursuit of improving accessibility for all patrons, we empathize that website changes may also be challenging for our readers. We welcome and appreciate your feedback so we can further improve the usability of our services. Please feel free to share your thoughts or questions in the comments section and connect with us on Twitter.