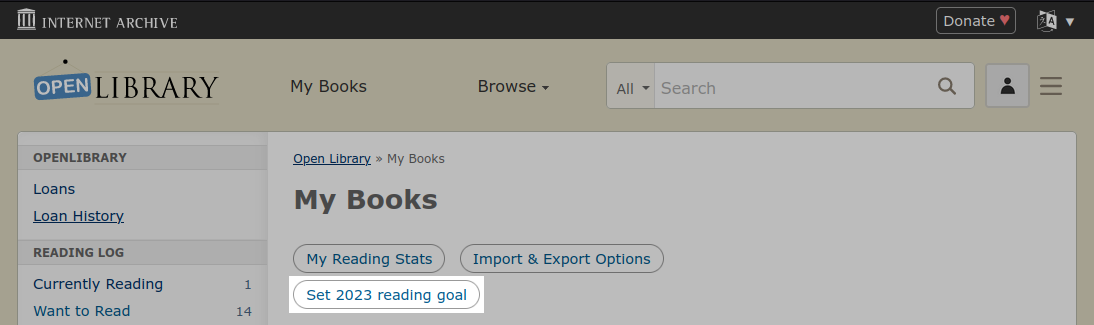
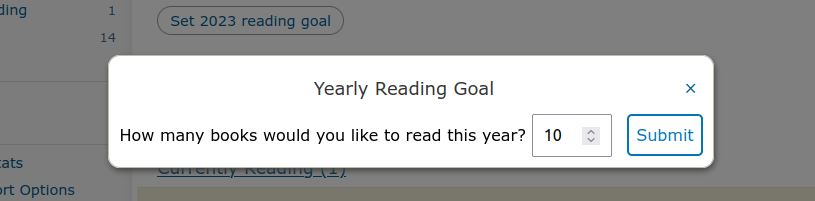
Hello, I am Jayden Teoh, a student from Singapore, and this year I participated as a 2023 Google Summer of Code contributor with the Internet Archive’s Open Library project to improve the site’s performance and supercharge subject pages.
If you are an Open Library patron, you have likely encountered times where certain pages seem to take and eternity to load. The Open Library team understands the importance of a smooth browsing experience and empathizes with how degraded site performance affects patrons. This is why we prioritized site performance as a key focus for our 2023 GSoC roadmap. As strongly as we felt about improving the core performance of the current website, we also wanted to push the boundaries of Open Library’s capabilities by releasing community-powered subject pages we hope will help patrons more easily showcase and discover books they’ll love. I’m excited to share more about what we accomplished and next steps in our plans.
Improving Site Performance
According to Browserstack,”40% of visitors will leave a website if it takes longer than three seconds to load”. But how do we measure which pages are slow or fast? How do we determine if a slow load time is an anomaly or a systemic pattern? Do we care about improving the average load time for a page or eliminating the most egregious case where pages load especially slowly?
Identifying site performance issues can be a challenging task. In order to effectively address this issue, Mek, a GSoC mentor for the project, suggested the use of performance tracking tools such as Sentry, as well as considering Google’s Core Web Vitals metrics, using Google’s PageSpeed Insights (PSI) reports and running Lighthouse audits.
Sentry, a visual dashboard often used for error monitoring, has a “Performance” mode we were able to use to identify and rank pages according to metrics called P50 and P95 — the upper bound number of seconds at which 50% (P50) and 5% (P95) of transaction took to complete. For example, a P95 score of 5 seconds tells us that 95% of such requests completed within 5 seconds (and perhaps 5% were slower). Once we ranked pages in consideration of these metric, it became clearer just how bad certain pages could be in worst case scenarios. We coupled this information with our own domain expertise about which pages are most important to the average patron’s experience and then embarked on a journey with the aspiration of reducing the average load time of key pages by at least half.
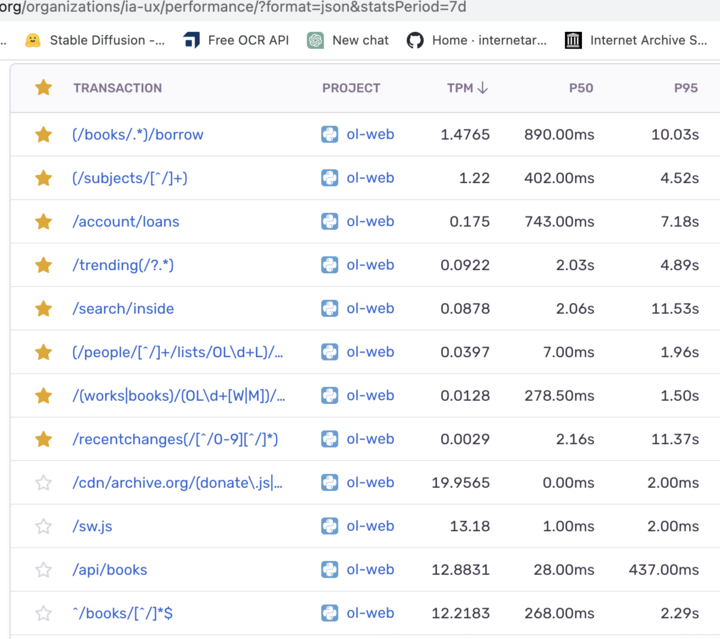
For each row in Sentry’s performance dashboard, one can “drill in” to the page to see stack tracebacks and detailed breakdowns about which functions were participating most to the slow response.
Our research revealed 2 opportunities:
- The “Search Inside” page was taking more than 11 seconds and an average of more than 2 seconds because the response was making redundant archive.org metadata request on each search result match on the page to determine each book’s availability, rather than computing the availability of all the books in a single request.
- Several of the slow pages had a common slow component — the LoanStatus borrow button — which we could speed up by caching and thus “feed two birds with one scone”.
By the end of the 12 weeks of this program, we manage to reduce the load times of several key pages significantly. One of my proudest achievements was the reduction of the ‘search/inside’ page by over 500%. This feature is important to patrons because it allows them to search for content within books, rather than just searching based on the author and title so I am glad we were able to make this feature faster and thus more accessible.
Editor’s note: We are still collecting metrics and plan to add before-and-after graphs of the search inside page speeds. Our changes to the borrow button are in the process of being staged and tested and we’re excited to update this blog post with metrics in the future. Hopefully you have noticed the improvements since it was launched a few weeks ago!
Unleashing the Power of Subject Tags
Empowering Librarians and Expanding Book Categorization at Open Library
For almost a decade, the Open Library has had basic subject pages that give readers a way to browse or search for books on a given topic, see books with similar subjects, and discover prolific authors of a genre. It may surprise you to learn that the whole page experience is generated based on the name of the subject. For instance, when one visits the “Magic” subject page, one may notice a carousel of books that is populated using a query based on its name: “subject:magic“. This approach gives us a simple formula for creating millions of subject pages on-the-fly, but it also has significant shortcomings.
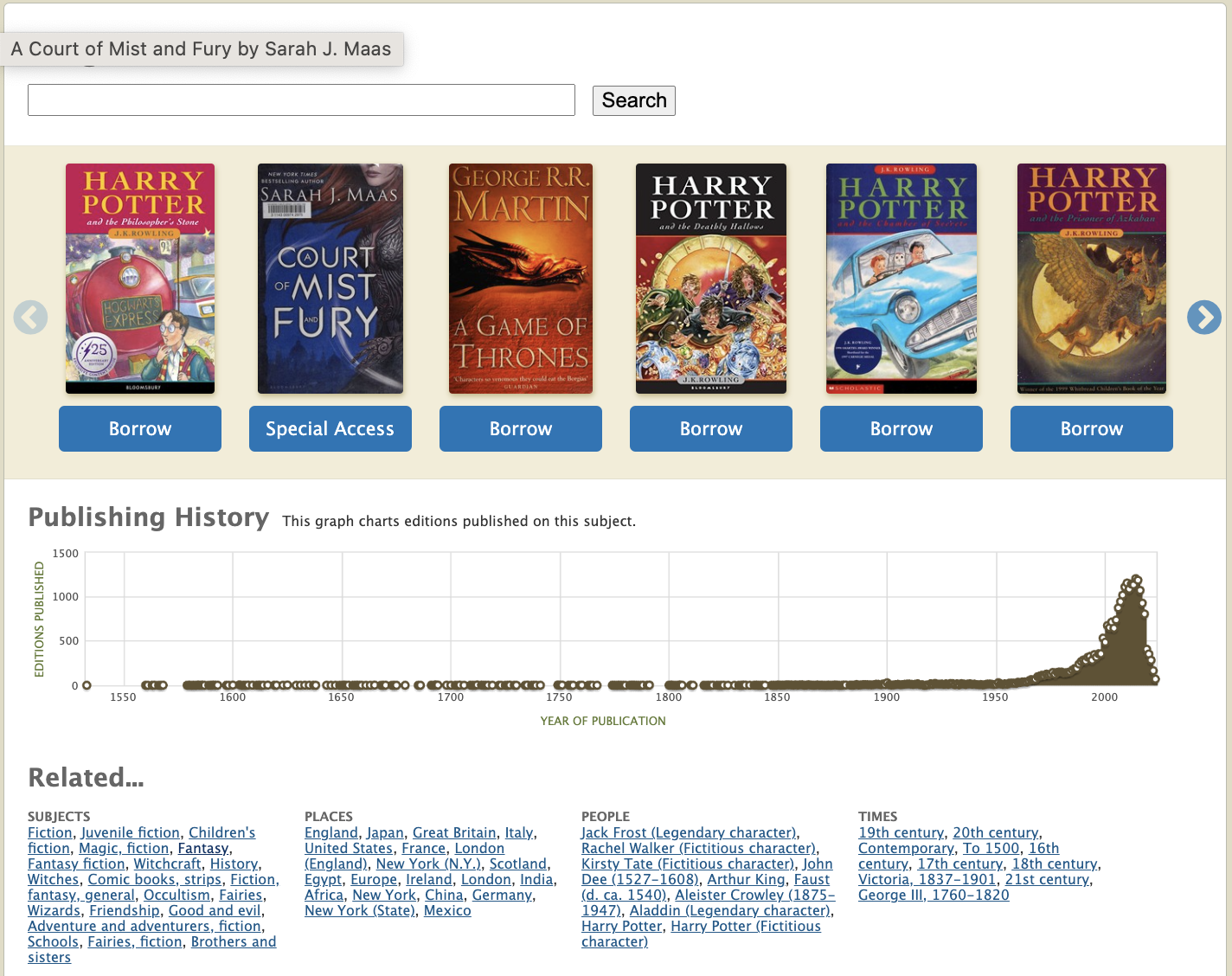
Namely, subject pages are incapable of storing additional metadata about a given subject and the current subject pages is limited to showcasing a single carousel of books. If the subject is overly vague, like “textbooks“, the reader may often not be shown a useful set of books and there’s no affordance provided that helps the reader narrow their search further, e.g. to design textbooks. If we search for a subject called “design textbooks“, we are informed no matching subjects exist. However, if we do an intersecting search for books that are subject:textbooks AND subject:”industrial design”, there are a few interesting results! The problem is, there’s currently no mechanism which allows librarians to extend Open Library subjects and specify which book collections should show up.
My primary objective through GSoC was to give librarians the ability to enrich and edit any subject page on Open Library so each page may be as beautiful and thoughtfully curated as a library or bookstore showcase. Our solution was to give librarians the ability to create a new “Tag” document for any subject page and load it with custom logic to extend how that subject page should be rendered. Tags serve as a catalyst for librarians to provide more precise categorizations within broad subjects. By leveraging Subject tags, librarians can dive deeper into specific areas of interest, allowing readers to discover a rich array of sub-subjects. For instance, librarians might choose to add new rules into the Tag document for the Cooking subject featuring carousels for vegan and budget cooking, in order to make it more useful for readers. This granularity opens up a world of possibilities, enabling readers to explore their preferred niches and discover hidden gems within subjects they cherish. Just like how a physical library may rotate their bookshelves with new categories every month, Subject Tags grant librarians more freedom to curate interesting subject topics that may suit patrons, allowing for a more personal and humane touch to the book discovery process.
By now, I hope you are able to understand just how pertinent Subject Tags will be to our Open Library and why it is a privilege for me to be working on such an important feature. Although the idea is clear, the implementation certainly is not. Open Library’s database is built using our own niche and complex Wiki engine called Infogami. To create a new class of data, we would have to create a new Infogami type. Here’s the catch: there has not been a new Infogami type created in the last 13 years and there is no existing documentation for doing so. Navigating any new code architecture can be a tedious task for any programmer and now I had to miraculously work with an arcane technology that no one knows how to use? What could go wrong?
Thankfully, I had the support of a wonderful community and amazing mentors like Mek, Jim, and Drini. They provided me with a lot of guidance throughout the process of reverse engineering the creation of an Infogami type. And after months of work, I was able to successfully incorporate a new Subject Tags Infogami type into the Open Library architecture. Especially since Open Library is an open-source project, I decided to write a tutorial and document the unintuitive technical aspects of implementing a new Infogami type, as a gift to help future developers who may wish to extend the functionality of the platform in similar ways. The tutorial can be found here.
Now, let me show you the power of Subject Tags and how they can be used to enrich the Open Library’s Subject pages. Let’s use the ‘Magic’ subject page as an example. This is how it looks right now.
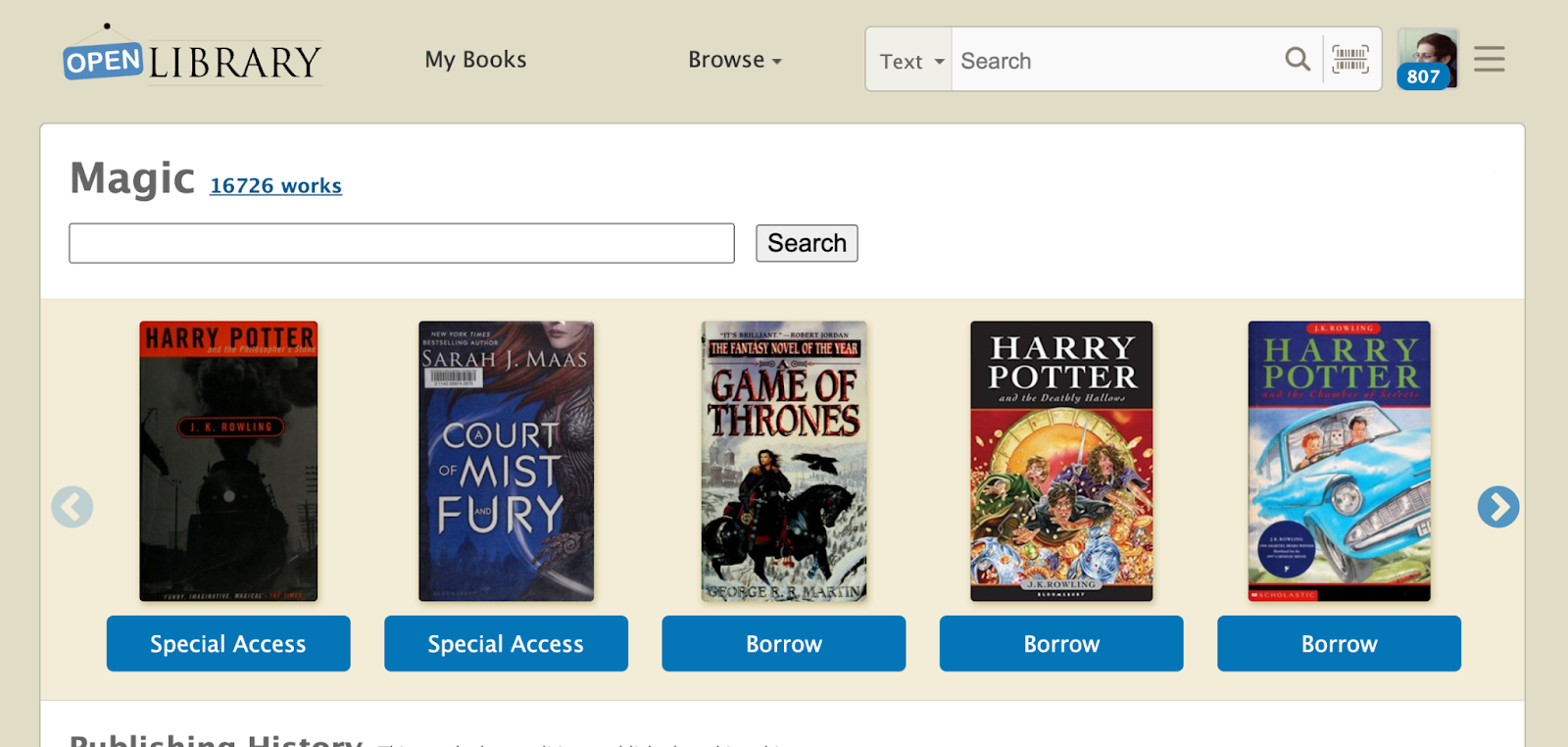
As you can see, currently the subject page is plain with no description about what the subject is about. That’s not very informative is it? Prior to Subject Tags, we are unable to store more information about subjects because they are just strings with no capabilities to store other metadata. However, now with the Subject Tags, we can do that! Let me show you how. First, let’s add a new Subject Tag into the Open Library for the ‘Magic’ subject.
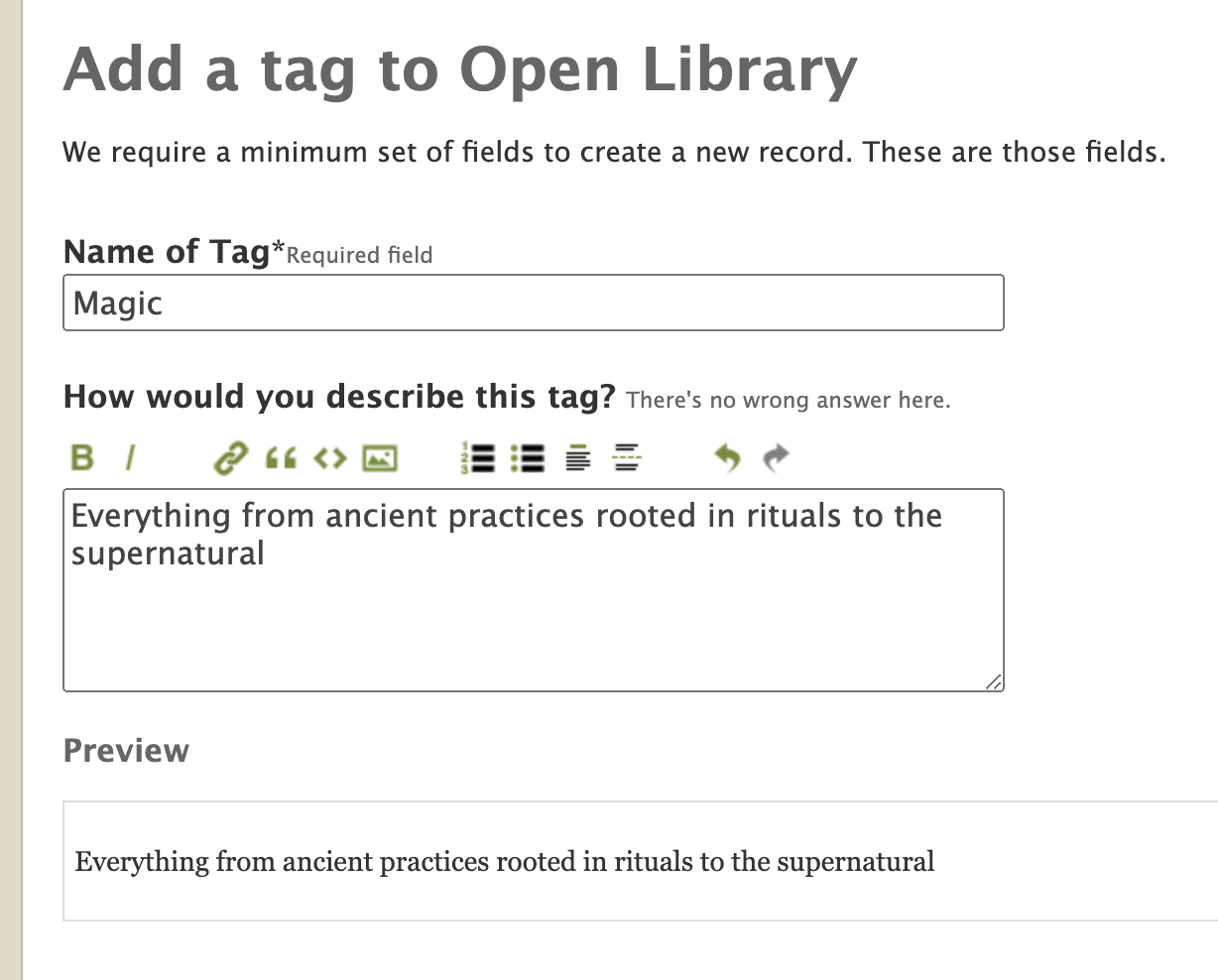
The Subject Tag creation form allows us to store metadata about the ‘Magic’ subject, including its description. After we’ve created the Subject Tag, let’s head back to the ‘Magic’ subject page. Tada, we can now see the newly added description in the subject page.
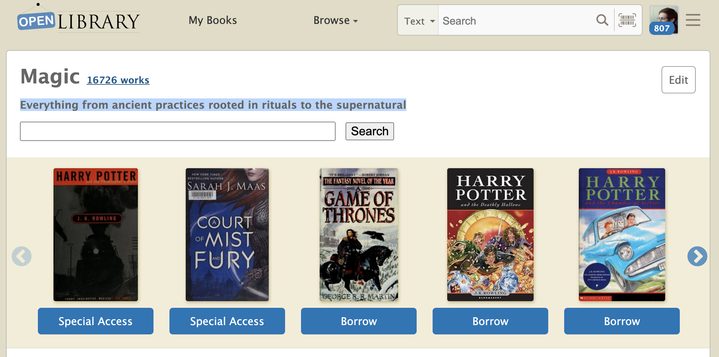
You are probably still not convinced of the utility of Subject Tags. Let me give you a deeper glimpse into the realm of possibilities that Subject Tags offer. Currently on the Magic page, we are only able to display a carousel with books that have the subject ‘Magic’. What if we want to include a carousel displaying books about ‘Magic Tricks for Kids’? Well, with Subject Tags, now we can! As a librarian, we can edit the ‘Magic’ Subject Tag and use the experimental Plugin to define a new carousel. Right now, the interface is quite advanced, is still being prototyped, and is intended for expert librarians who know how to compose queries, but in the future we aim to make it easy for any librarian to extend the functionality of subject pages using Tags.
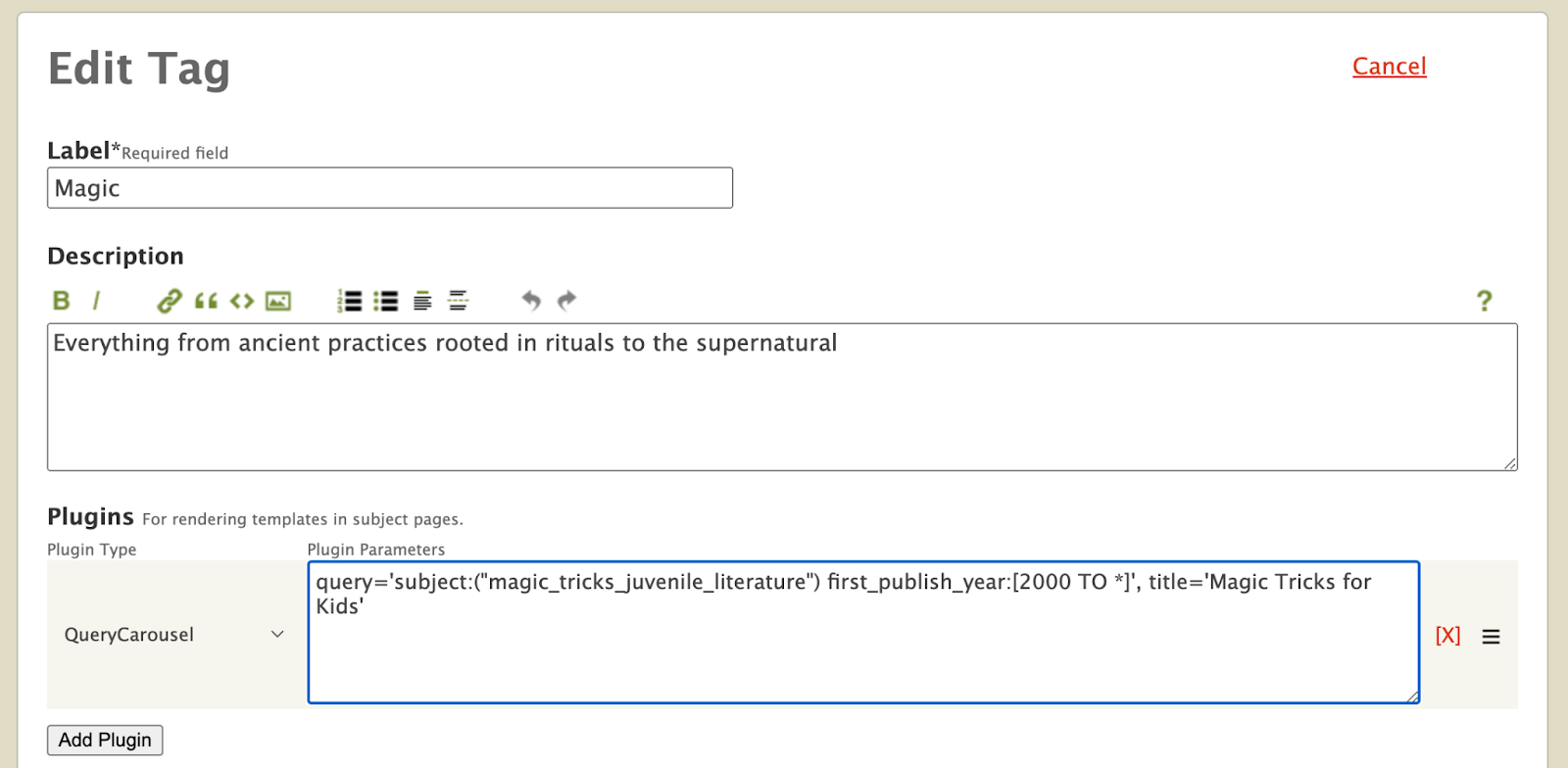
Plugins allow subject pages to load custom templates within our system and utilizes them to enrich the subject page. For example, in the Plugins field of the Subject Tag edit form above, we included a new QueryCarousel Plugin that allows the ‘Magic’ subject page to search for all books with the “magic tricks juvenile literature” subject and display them in a template carousel. Let’s take a look at the ‘Magic’ subject page again.
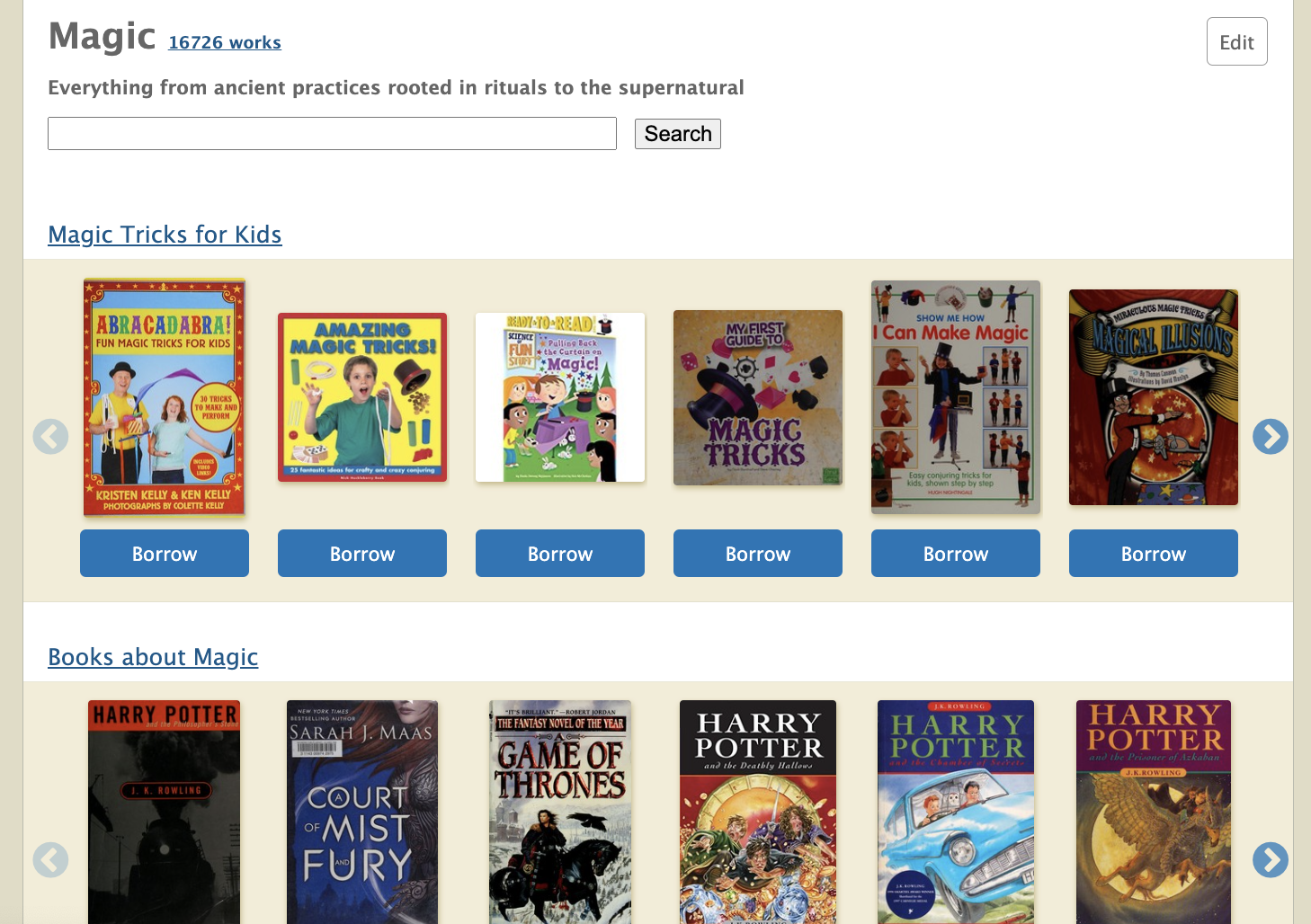
Fascinating isn’t it? Subject Tags have enabled the enhancement of the previously one-dimensional subject pages. Through Subject Tags, librarians are now equipped to curate and display information that can enrich the book discovery experience of patrons.
What happens when librarians want to add a new carousel of books to a subject page but the books haven’t been labeled with subjects? When we developed the Tag feature, adding a subject to books had to be done one book at a time. To aid librarians in the process of curating books and subjects, I also implemented a Bulk Tagging tool that enables librarians to add subjects to multiple books simultaneously.
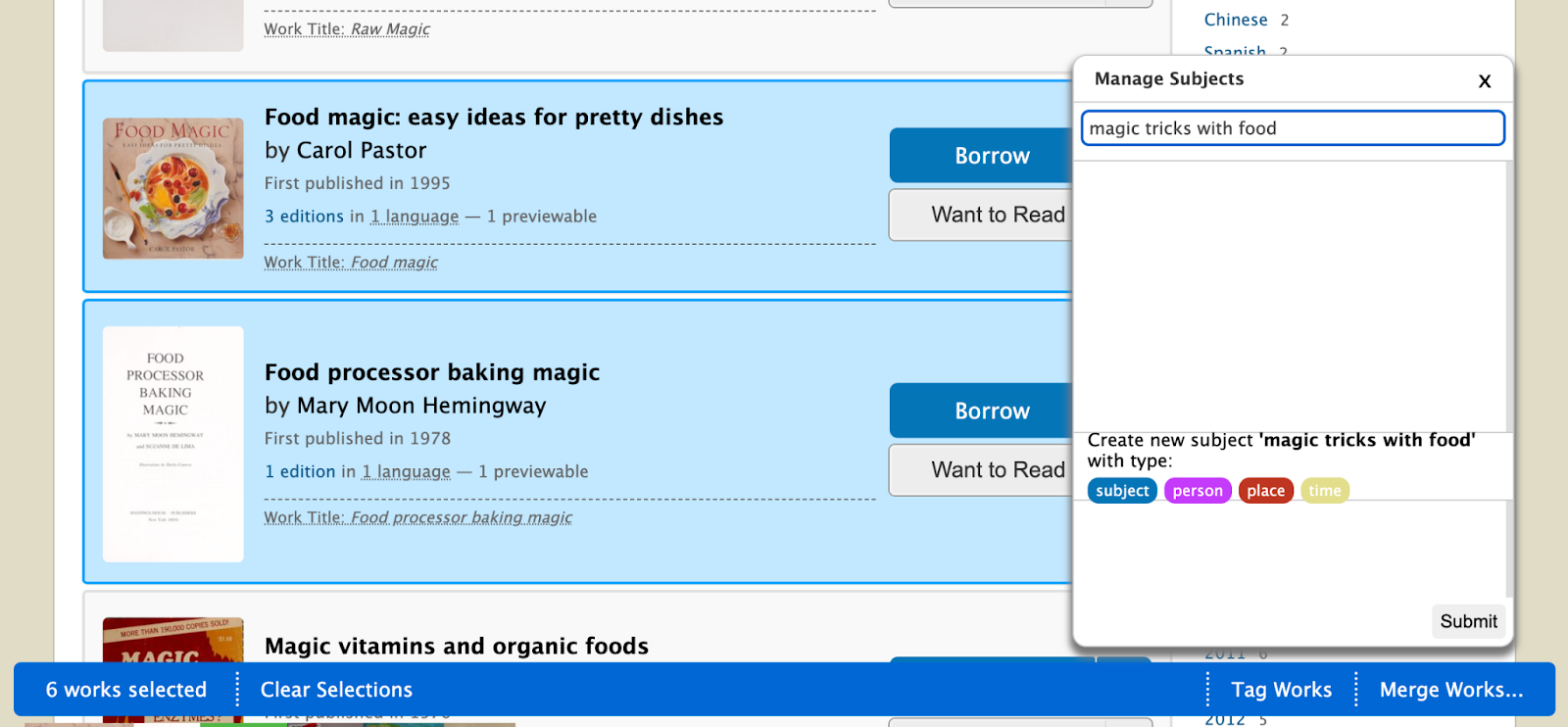
Subject Tags are still in beta so we can time our time understanding the needs of our patrons and the librarians who will use these new tools. As a next step, we have decided to do research on where this feature can have the most impact and will focus our efforts on enriching a small handful of specific subject pages using Tags. One subject we’re excited to prototype with is ‘Cooking’. The team has been curating the best cooking-related information to showcase using Subject Tags and testing new features to launch alongside Subject Tags. Here is a mockup by Roya, a fellow in our design community, showing one possible UI we have in mind:

When Subject Tags are launched, we hope you can visit the ‘Cooking’ page and provide us with input on what we can improve on and what you would like to explore in a Subject page. With your feedback, librarians will have a better understanding on how to enhance your book exploration process with personally curated topics. Moving forward, we will utilize Subject Tags to enrich other subject pages on the Open Library and slowly phase out the mundane subject pages we have currently.
Ending note
Thank you to the incredible Open Library community for their unwavering support over these past months. A special shout-out goes to Mek, whose mentorship has been nothing short of exceptional. Not only has Mek dedicatedly guided me through the program, but also gone the extra mile to make sure I’ve had the most enriching learning journey. Lastly, my deepest thanks to the Internet Archive and Google Summer of Code for making it possible for me to be a part of this life-changing experience. This is an experience that I’ll never forget.